今年5月27日, 一位据说在德国的中国程序员@将记忆深埋 在微博公布:
“半年时间,100多TB数据, 利用1024、91、sex8、PronHub、xvideos 等网站采集的数据对比Facebook、instagram、TikTok 、抖音、微博等社交媒体。我们在全球范围内成功识别了10多万从事不可描述行业的小姐姐。”
热炒之下,这套Deep Learning系统瞬间炸了锅,顺便炸翻了在德国处于懵逼状态的一众平时安安静静老老实实的程序员:我们身边竟然藏着这样一个人?!
这引起了我对在德中国籍程序员的行业分类以及专业方向等相关数据的好奇。长期以来德国一直面临着劳动力短缺,特别是工程技术方向,尤其是IT专业人才的极度缺乏,以至于德国政府将这些专业的人才获得欧盟蓝卡的最低年薪标准降到了税前41808欧元(2019)。换句话说,软件信息专业的同学毕业后在德国很容易找到工作,并且获得蓝卡工作居留许可。近年来身边来自印度,俄罗斯,中国的程序员也在逐年增加。那么中国程序员在德国到底从事那些行业呢?
1. 蓝卡和德国程序员数据
先在网上找了一圈,没有找到特别针对中国籍程序员的数据分析,只找到关于蓝卡和在德国工作的程序员的数据分析。
1-1. 蓝卡数据
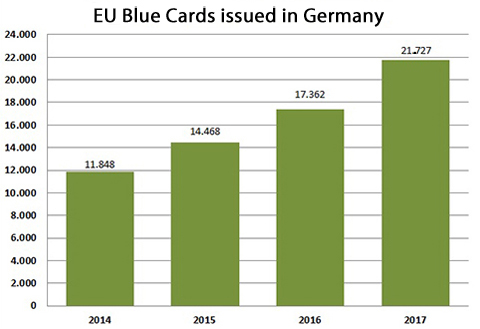
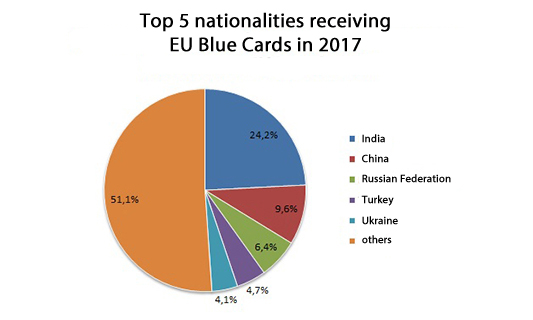
2013-2018年,超过76000外籍人员持蓝卡在德国工作。2017年德国共有21727外国人申请蓝卡工作签证,其中中国国籍申请者占了近10%。这说明仅2017年,就有二千多中国籍雇员申请了蓝卡,这其中IT从业者占比未知。假设IT软件信息领域的中国雇员只占比其中10%,那么过去五年中就有约800名中国籍程序员拿到蓝卡。实际上根据生活和工作的接触,我保守估计在德中国籍程序员数量超过1500 人。
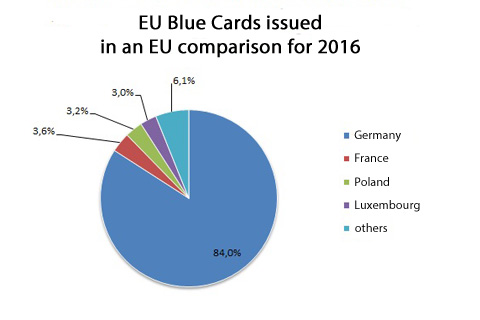
据2016年数据,欧盟蓝卡签证的所在申请国,84%位于德国,可以说几乎整个欧盟的外国工程师都来德国找工作了。
1-2. 在德国工作的程序员数据
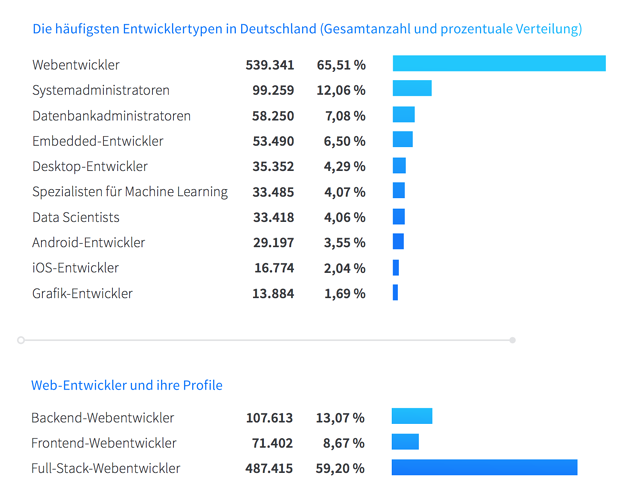
据 来自Stack Overflow的德国IT数据分析,2016年全德国有超过120000软件开发人员,2017年暴增超过820000。不过82万这个数字不可信,毕竟德国总人口才八千多万,如果是将近1%的占比,德国不至于一直闹码农荒。可信的十几万程序员中,软件开发方向数据如下:Web开发占比65.51%,系统管理员位居第二,数据库管理员第三。仅仅这三个方向就吃掉了75%的占比,为什么德国程序员看起来很偏科,爆火的机器学习和数据分析才各占4%左右。
这是因为德国IT行业大多为德国的支柱产业服务,如汽车,制药,机械,电子等,这些公司所需的企业内部管理软件如今多为SAAS构架,同时因为传统行业对云服务的怀疑和不信任态度,亦或安全原因,他们又维护着大量的企业私有服务器,和企业级数据库。所以不难理解前三甲总合占比之大。
虽说国内的移动开发趋势这两年有点弱,但德国的iOS和Android移动开发就从来没有强过,因为缺乏B2C土壤,传统企业一般也不重视移动开发(未必需要),相关产业很多都外包于东欧或者印度,中国的团队。
2. 在德中国程序员数据分析
网络上暂时没有发现任何关于这些可能存在的1500 名中国程序员的数据,这就尴尬了,没数据怎么分析?
—-本文只好结束—-
等等,平时管理的几个德国的IT行业微信群不就是最好的数据源?群友加起来也有500多人了,样本虽不大,但毕竟还是遵循正态分布的。不过必须用Python 3开发一套脚本来收集和处理相关数据。
2-1. 在德中国程序员做什么:
2-1-1. 数据采集
如果使用匿名调查报告方式,扰民且又费时费力,此类信息只能从群昵称上打主意了,首先是发群公告规范群友昵称标准:
昵称| 行业或专业领域| 擅长开发框架或语言
举例:
小呆| 学生| 想找数据分析工作
中二| 前端| nodejs , react
大傻| 机器学习| nlp
老痴| 自动驾驶| c ++
大部分群友按标准改了昵称,但是还有一部分死硬派坚决不改,又不能经常发群消息提醒,只能开发机器人自动提醒了。微信机器人wxpy 是一个包装得非常简洁的微信个人号 API, 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展,一些常见的场景:
运行脚本时自动把日志发送到你的微信
群成员信息获取,邀请或者踢人
跨号或跨群转发消息
监听群聊或者单聊的信息
通过脚本和第三方API交互,比如图灵聊天机器人,智能办公,智能家居
2-1-1-1. 开发需求
获取群聊群成员信息
找出所有群昵称不符合标准的群友
随机抽取5人,在群里发布改昵称提醒消息
同时将这次提醒的5人,存储进数据库
每天早八点晚八点两次定时启动昵称检查脚本
某人在将来被提醒次数超过10次,还不予配合不改昵称时,将自动踢出群
新群友被邀请进入群时,立刻发送群规提示改昵称
2-1-1-2. 开发分解
该任务所需第三方库如下:
pip3 install wxpy
pip3 install apscheduler
pip3 install pymysql
pip3 install DBUtils
1. 建库建表
本文采用的是MySQL,后期可以扩展支持Postgre或者MongoDB。
因为需要存储微信表情字符集,所以表的默认编码采用utf8mb4_unicode_ci。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
DROP TABLE IF EXISTS ` wx_chat_group ` ;
CREATE TABLE ` wx_chat_group ` (
` id ` int ( 11 ) NOT NULL AUTO_INCREMENT ,
` name ` VARCHAR ( 64 ) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' ,
PRIMARY KEY ` id ` ( ` id ` )
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COLLATE utf8mb4_unicode_ci ;
INSERT INTO ` wx_chat_group ` ( ` id ` , ` name ` ) VALUES ( 1 , '德国IT职业信息分享群' ) ;
-- 每次抽取的不合规格的昵称将存储如表以供计数
DROP TABLE IF EXISTS ` wx_chat_nickname_check ` ;
CREATE TABLE ` wx_chat_nickname_check ` (
` id ` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT ,
` group_id ` int ( 9 ) UNSIGNED NOT NULL ,
` wx_puid ` VARCHAR ( 16 ) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' ,
` nickname ` VARCHAR ( 64 ) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' ,
` create_time ` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Create time' ,
PRIMARY KEY ` id ` ( ` id ` ) ,
INDEX ` idx_group_id ` ( ` group_id ` ) ,
INDEX ` idx_create_time ` ( ` create_time ` )
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COLLATE utf8mb4_unicode_ci ;
2. 用户设置
所有用户自定义变量存入conf文件里,如群名,临时存储路径,数据库接入信息,踢人阈值:
[ wechat ]
group_name_1 =德国IT 职业信息分享群
group_id_1 =1
path_tmp =/opt /tmp /
notice_random =5
kick_max =10
tuling_api_key =xxxxx
[ mysql ]
mysql_host =localhost
mysql_port =3306
mysql_user =root
mysql_pwd =xxxx
mysql_database =wechat_group_ibot
3. 监听群消息
初始化群聊对象,并且监听群消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 查找群聊,并且设置附加属性,以备后用
def init_group ( group_name , group_id ) :
group = ensure_one ( bot . groups ( ) . search ( group_name ) )
group . ext_attr = lambda : None
setattr ( group . ext_attr , 'group_id' , group_id )
setattr ( group . ext_attr , 'group_name' , group_name )
return group
# 初始化微信机器人bot
bot = Bot ( cache_path =True , console_qr =True )
# unique chat person's id
bot . enable_puid ( )
# 读取自定义参数
cf = configparser . ConfigParser ( )
cf . read ( 'wechat.conf' )
group_name_1 = cf . get ( 'wechat' , 'group_name_1' )
group_id_1 = cf . get ( 'wechat' , 'group_id_1' )
# 初始化群聊对象
group_1 = init_group ( group_name_1 , group_id_1 )
# 监听类型为NOTE的群消息,如:"aa"邀请"bbb"加入了群聊
@ bot . register ( group_1 , NOTE )
def welcome_for_group ( msg ) :
try :
new_member_name = re . search ( r '邀请"(.+?)"|"(.+?)"通过' , msg . text ) . group ( 1 )
except AttributeError :
return
group_1 . send ( welcome_text . format ( new_member_name , space_after_chat_at ) )
# 保持bot持续运行
bot . join ( )
4. 昵称检查
检查群友昵称,存入数据库并且发送提醒, 具体逻辑代码这里不予累述。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def check_nickname ( nickname ) :
# 正则检验群昵称是否标准
if re . match ( r '([\u4e00-\u9fa5]|[ -~]|[\s\S])+\|([\u4e00-\u9fa5]|[ -~])+\|([\u4e00-\u9fa5]|[ -~])+' , nickname ) :
return True
else :
return False
. . . . . .
# 检查群友昵称
def process_group_members ( group ) :
# 每次检查前先刷新群成员信息,避免用户改了昵称后再次被提醒
# 但刷新会改变成员临时的内部puid,所以检查昵称必须同时结合puid和nickname
group . update_group ( members_details =False )
. . . . . .
for member in group :
nickname = member . name
wx_puid = member . puid
if not check_nickname ( nickname ) :
invalid_member = GroupMember ( nickname , wx_puid , 0 )
invalid_members . append ( invalid_member )
. . . . .
# 随机抽取不合格的5人
random_members = random . sample ( invalid_members , k =5 )
. . . . . .
# 将本次提醒群友存入数据库,供下次计数
def insert_invalid_name ( group_id , wx_puid , nickname ) :
bot_db . execute ( "INSERT INTO wx_chat_nickname_check (`group_id`, `wx_puid`, `nickname`)"
" VALUES (%s, %s, %s)" ,
( group_id , wx_puid , nickname ) )
# 获取昵称不合规群友被提醒计数
def get_invalid_name_count ( group_id , wx_puid , nickname ) :
result = bot_db . get_count ( "SELECT id FROM wx_chat_nickname_check "
"WHERE group_id = %s and (wx_puid = %s or nickname = %s)" , ( group_id , wx_puid , nickname ) )
return result
5. 数据库连接池
这里的数据库连接使用了数据库连接池:DBUtils.PersistentDB
DBUtils.PooledDB: 适用于多线程频繁开启关闭数据库连接
DBUtils.PersistentDB:适用于单线程多次频繁连接数据库
如果不采用线程池而是采取直连,那么运行一段时间后,脚本将出现该错误
pymysql . err . OperationalError : 2006
这里将DBUtils再次封装了一下,写了一个单例模式BotDatabase, 提供了query(select), execute(update, delete) 以及批处理execute等常用接口。
6. 启动定时器
# 早八点晚八点各执行检查一次
def start_schedule_for_checking_member ( group ) :
scheduler = BlockingScheduler ( )
scheduler . add_job ( lambda : process_group_members ( group ) , 'cron' , hour =8 , minute =1 , timezone ="Europe/Paris" )
scheduler . add_job ( lambda : process_group_members ( group ) , 'cron' , hour =20 , minute =1 , timezone ="Europe/Paris" )
2-1-1-3. 最终成果
2-1-1-4. 已知问题
在消息中输入 @群员昵称 并不能真正让该群友收到@提示(显示推送提示),微信App里是在@群员昵称后自动加上了一个特殊的显示空白的字符u’\u2005′ 。但是经测试,加上这个符号也不行,推测是微信Web API基于防范垃圾推送,屏蔽了群提示接口。
wxpy的bot在运行一段时间后会停止工作,出现连接服务器错误,必须重新登录,推测是微信Web API的Session安全机制导致的问题。
2-1-2. 数据清洗
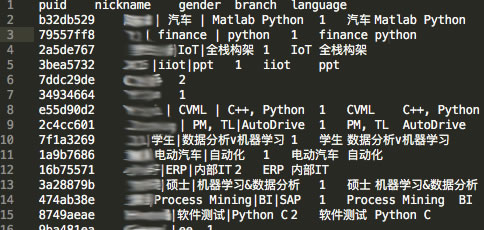
一段时间后大部分群友修改了昵称,于是有了在德中国程序员职业和专业方向的数据,经清洗后,导出CSV规格如下。
2-1-3. 数据分析
该任务所需第三方库如下:
pip3 install pandas
pip3 install matplotlib
pip3 install jieba
pip3 install wordcloud
pip3 install seaborn
pip3 install palettable
2-1-3-1. 开发需求
在德程序员男女比例
在德IT软件专业在职和学生比例
分析在德程序员所处行业和专业方向
程序猿和程序媛所处行业和专业方向对比
分析在德程序员常用开发语言和框架
程序猿和程序媛常用开发语言和框架对比
在职和学生常用开发语言和框架对比
2-1-3-2. 开发分解
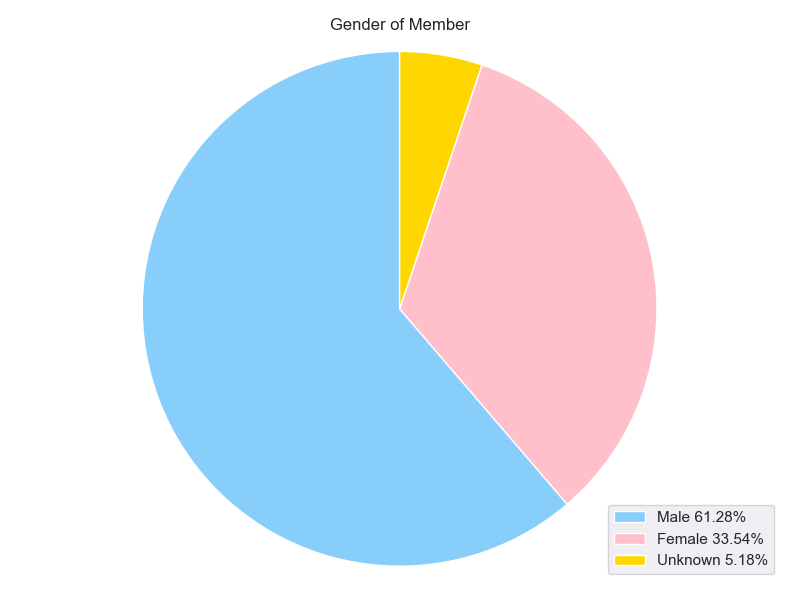
1. 在德程序员男女比例,输出Pie Chart
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def gen_pie_member_gender ( self , csv_file ) :
df = pd . read_csv ( csv_file , delimiter ='\t' , encoding ='utf-8' )
genders = df [ 'gender' ]
col = [ 0 , 0 , 0 ]
for g in genders :
if g == 1 :
col [ 0 ] = col [ 0 ] + 1
elif g == 2 :
col [ 1 ] = col [ 1 ] + 1
else :
col [ 2 ] = col [ 2 ] + 1
perccent_male = '{0:.2f}%' . format ( ( col [ 0 ] /len ( genders ) * 100 ) )
perccent_female = '{0:.2f}%' . format ( ( col [ 1 ] /len ( genders ) * 100 ) )
perccent_unknown = '{0:.2f}%' . format ( ( col [ 2 ] /len ( genders ) * 100 ) )
labels = [ r 'Male %s' % perccent_male ,
r 'Female %s' % perccent_female ,
r 'Unknown %s' % perccent_unknown ]
colors = [ 'lightskyblue' , 'pink' , 'gold' ]
plt . figure ( figsize =( 8 , 6 ) )
patches , texts = plt . pie ( col , colors =colors , startangle =90 )
plt . legend ( patches , labels , loc ="best" )
plt . title ( 'Gender of Member' )
# Set aspect ratio to be equal so that pie is drawn as a circle.
plt . axis ( 'equal' )
plt . tight_layout ( )
path_image = os.path . join ( self . path_analyse ,
'%s_member_gender_pie.png' % self . group_id )
plt . savefig ( path_image , format ='png' , dpi =100 )
plt . close ( )
return path_image
分析:
在德中国程序猿和程序媛比率约为2:1,这个比例基本和中国籍蓝卡申请人男女比率持平。但是根据2018年中国程序员数据调查表,中国程序员群体中男女比例接近12:1。德国的各位猿,你们就偷乐吧。
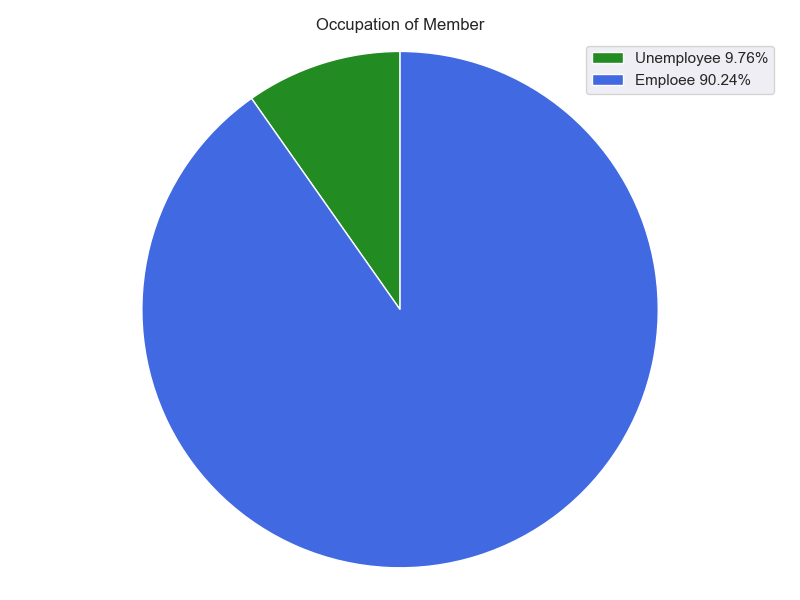
2. 在德IT软件专业在职人员和学生比例,输出Pie Chart
代码和上面雷同。
分析:
IT信息行业在职工作人员和在读学生比率为9比1,绝大部分人是在职工作的。
3. 在德程序员所处行业和专业方向,输出词云
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 这里采用一个汉字停词库,近两千词
@ staticmethod
def load_stopwords ( ) :
filepath = os.path . join ( './assets' , r 'stopwords_cn.txt' )
stopwords = [ line . strip ( ) for line in open ( filepath , encoding ='utf-8' ) . readlines ( ) ]
return stopwords
def gen_wordcloud_info_nicknames ( self , csv_file , column ='branch' , gender ='all' ) :
df = pd . read_csv ( csv_file , delimiter ='\t' , encoding ='utf-8' )
stopwords = set ( STOPWORDS )
stopwords . update ( self . load_stopwords ( ) )
# 可添加一些额外stopword,过滤词云结果
stopwords . add ( '学生' )
#自定义jieba分词词库,定义一些IT软件特殊术语
jieba . load_userdict ( "./assets/jieba_userdict.txt" )
col = df [ column ]
# 将词云按限定图形布局
shape_file = './assets/member_info_shape.png'
word_count = ""
for c in col :
if c is not np . NaN :
seg_list = jieba . cut ( c , cut_all =False , HMM =True )
for word in seg_list :
word_count = word_count + word + " "
mask = np . array ( Image . open ( shape_file ) )
font = r './assets/heiti.ttf'
word_cloud = WordCloud (
margin =0 ,
mask =mask ,
font_path =font ,
scale =1 ,
stopwords =stopwords ,
random_state =42 ,
background_color ='white'
) . generate ( word_count )
path_image = os.path . join ( self . path_analyse ,
'%s_member_word_cloud_%s_%s.png' % ( self . group_id , column , gender ) )
word_cloud . to_file ( path_image )
return path_image
分析:
大数据,数据分析,数据挖掘
机器学习ML,人工智能AI,深度学习
汽车,自动驾驶,CV(机器视觉)
这三个大方向占比最大,说明中国码农在德国还是跟得上软件信息时代的变革的,并没有像一般德国码农那样一个技术吃一辈子。基于德系汽车制造业在电动车和自动驾驶领域的研发投入加重,越来越多的程序员也向这几个领域转型。一些传统企业如制造业,也开始用大数据来发现生产中潜在的工艺改进,或提前故障预警。
云计算,和以上三个方向密切相关,从业人员却不多。这可能是因为德国本土鲜有自己的大规模云计算服务商,很多企业没有自己的私有云,而将云服务部署在AWS上,如AWS就和奔驰,大众等汽车厂商达成了云数据等方向的深度合作。
互联网,电商这些领域在我另一篇文章《中国程序员在德国 》里提过,在德国属于荒漠地带,从业人员数量少可以预见。
咨询和SAP这两个领域,在德国企业里可以说是四平八稳,很多德国传统企业的IT项目多为外包,自己的IT团队只负责管理和规划,所以专业咨询人员必不可少。同时SAP系统在德国各行业的占有率非常高,而且SAP的定制功能强大,包罗万象,可以说,如果不考虑开发时间和成本,你想要什么流程,SAP都能给你二次开发出来。
经济,金融,银行,由于英国脱欧,大批金融机构从伦敦搬到法兰克福,对程序员也是求贤若渴。
图中还出现了区块链倔强而顽强的身影。
4. 程序猿和程序媛所处行业和专业方向对比,导出云图
处理步骤和上述雷同,所以将gen_wordcloud_info_nicknames进行扩展,按branch或者language过滤数据源。
. . . . . .
if gender == 'male' :
df_male = df [ df . gender == 1 ]
col = df_male [ column ]
shape_file = './assets/member_%s_%s_shape.png' % ( column , gender )
elif gender == 'female' :
df_male = df [ df . gender == 2 ]
col = df_male [ column ]
shape_file = './assets/member_%s_%s_shape.png' % ( column , gender )
else :
col = df [ column ]
shape_file = './assets/member_info_shape.png'
. . . . . .
生成图片:
嗯?这是什么鬼,这两坨哪里能看出男女区别了?!
作为有着钢铁直男审美的程序员决不能容忍这么丑陋的数据呈现,好在Python支持透明PNG图片叠加,先准备相应的Alpha透明度较高的图片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 加载透明背景图片
if gender == 'male' :
. . . . . .
shape_alpha_file = './assets/member_%s_%s_shape_alpha.png' % ( column , gender )
elif gender == 'female' :
. . . . . .
shape_alpha_file = './assets/member_%s_%s_shape_alpha.png' % ( column , gender )
else :
. . . . . .
shape_alpha_file = './assets/member_info_shape_alpha.png'
. . . . . .
# 预定义词云输出颜色集范围,突出男女有别
if gender == 'male' :
word_cloud . recolor ( color_func =self . color_func_blue , random_state =3 )
elif gender == 'female' :
word_cloud . recolor ( color_func =self . color_func_red , random_state =3 )
word_cloud . to_file ( path_image )
# 将透明背景图叠加到云图上
background = Image . open ( path_image )
foreground = Image . open ( shape_alpha_file )
background . paste ( foreground , ( 0 , 0 ) , foreground )
background . save ( path_image )
这下数据呈现美观且直观多了。
分析:
在大数据,数据挖掘分析,机器学习上,猿媛平分秋色
自动驾驶和机器视觉CV,猿占比稍微多一点
媛更爱ERP,CRM,VWL,仓管,MES等企业级软件系统领域,还有BI和SAP领域
软件测试少不了程序媛妹子
比较意外的是从事嵌入式开发的女汉子不少
猿从事的专业领域更广,不过这也可能是采样数据不够大的原因
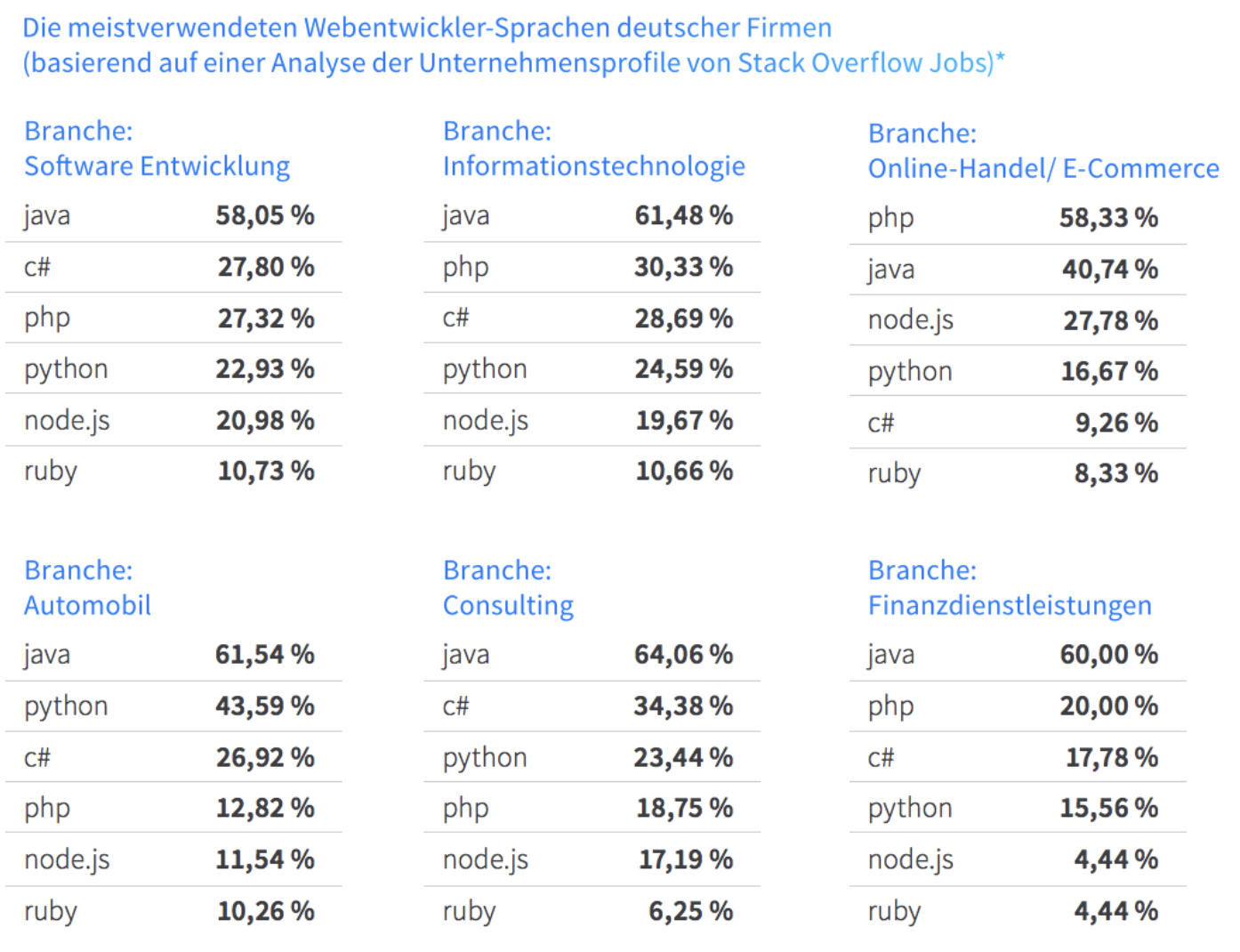
5. 在德程序员常用开发语言和框架
下面这三个分析代码一致,这里只贴出数据结果。
5.1 在德程序员常用开发语言和框架
分析:
得益于大数据和AI的火热,Python当仁不让位居第一。
Java,C和C++并驾齐驱。
Angualr,React,Vue,Jquery,Typescript在企业级应用前端开发里使用广泛
移动开发iOS和Android基本绝迹,原因之前也提了。
以上占比分布基本是符合德国六个行业开发语言占比率的,依次为软件开发,信息技术,电商,汽车,咨询,金融。稍微反常的是德国的中国程序员在工作使用PHP的不多,可是会PHP在德国也是很容易找工作的嘛。
5.2 程序猿和程序媛常用开发语言和框架对比
分析:
猿偏向后端开发,媛偏向前端开发
在Java,C++,C上,猿媛旗鼓相当
在数据库管理和SQL使用上,媛稍微多一点
总体来说,在德程序媛的能力并不比程序猿弱,技术栈相当广,德国不愧是培养理工女汉子的国度。
5.3 在职人员和学生常用开发语言和框架对比
分析:
加上这个对比,是因为之前担心一些热门语言是因为在读学生用得多,才占比高。不过从这个图看来,程序员们在工作中是确确实实使用到了这些技术栈,并不只停留在大学和科研领域。
2-2. 在德中国程序员说什么:聊天数据分析
以上知道了在德中国程序员们做什么,那么来看看他们平时聊什么?
2-2-1. 数据采集
2-2-1-1. 开发需求
监听并记录群聊入库
开发分解
1. 首先建表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
DROP TABLE IF EXISTS `wx_chat_history`;
CREATE TABLE `wx_chat_history` (
`id` BIGINT (20) NOT NULL AUTO_INCREMENT ,
`group_id` int (9) UNSIGNED NOT NULL ,
`msg_type` VARCHAR (16) COLLATE utf8_unicode_ci NOT NULL DEFAULT 'Text' ,
`wx_puid` VARCHAR (16) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' ,
`gp_user_name` VARCHAR (70) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' ,
`sender_name` VARCHAR (64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' ,
`receiver_name` VARCHAR (64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' ,
`msg` VARCHAR (2048) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' ,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Create time' ,
PRIMARY KEY `id` (`id`),
INDEX `idx_group_id` (`group_id`),
INDEX `idx_create_time` (`create_time`)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COLLATE utf8mb4_unicode_ci;
2. 数据持久化
通过监听群消息,将获取的消息录入数据库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 将puid,nickname,消息等相应数据存入数据库
def insert_chat_history ( group_id , msg_type , wx_puid , gp_user_name , sender_name , receiver_name , msg ) :
bot_db . execute ( "INSERT INTO wx_chat_history (`group_id`, `msg_type`, `wx_puid`, "
"`gp_user_name`, `sender_name`, `receiver_name`, `msg`)"
" VALUES (%s, %s, %s, %s, %s, %s, %s)" ,
( group_id , msg_type , wx_puid , gp_user_name , sender_name , receiver_name , msg ) )
def save_message ( msg , group_id ) :
# create_time = msg.create_time.strftime('%Y-%m-%d %H:%M:%S')
member_name = msg . member . name
wx_puid = msg . member . puid
gp_user_name = msg . member . user_name
message = ''
# 常规消息
if msg . type == TEXT :
message = msg . text
# 分享链接
elif msg . type == SHARING :
art_list = msg . articles
for item in art_list :
print ( item . url + ' ' + item . title + ' ' + item . summary )
message = item . url + '||' + item . title + '||' + item . summary
insert_chat_history ( group_id , msg . type , wx_puid , gp_user_name , member_name , '' , message )
# 监听群聊,包含自己发送的消息
@ bot . register ( group_1 , except_self =False )
def reg_msg_for_group ( msg ) :
save_message ( msg , group_id_1 )
# keep login by block thread
bot . join ( )
2-2-2. 数据清洗
定义函数,可以从数据库里提取指定时间段(如一个月)的数据,并生成csv以供下一步使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def save_chat_in_current_month ( self , group_id ) :
results = self . load_chat_history ( group_id , self . fl_days [ 0 ] , self . fl_days [ 1 ] )
path_csv_file = os . path . join ( self . path_analyse ,
'%s_chat_%s_%s.csv' % ( self . group_id , self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
with open ( path_csv_file , mode ='w' , encoding ='utf-8' ) as csv_file :
fieldnames = [ 'id' , 'create_time' , 'msg_type' , 'wx_puid' , 'sender_name' , 'msg' ]
csv_writer = csv . writer ( csv_file , delimiter ='\t' , quotechar ='"' , quoting =csv . QUOTE_MINIMAL )
csv_writer . writerow ( fieldnames )
for row in results :
row_id = row [ 0 ]
msg_type = row [ 1 ]
wx_puid = row [ 2 ]
sender_name = row [ 3 ]
msg = row [ 4 ]
create_time = row [ 5 ]
msg = self . format_message ( msg )
csv_writer . writerow ( [ row_id , create_time , msg_type , wx_puid , sender_name , msg ] )
csv_file . close ( )
return path_csv_file
最终生成的CSV格式文件:
2-2-3. 数据分析
2-2-3-1. 开发需求
生成话题词云
分析消息种类占比
分析日均聊天曲线
分析群员聊天活跃时间热点图
开发分解
1. 话题词云
相关代码和上面相近,生成的云图:
分析:
德国中国两者工作生活的对比是永恒的话题,到底回国还是留德,经常是热点。
因为是职业群,所以大部分话题还是集中在职场:公司,工作,老板,工资,技术
IT领域不得不提领头羊美国,包括硅谷的工资。
讨论贸易战少不了华为
创业目前在留德华中也是个热门话题
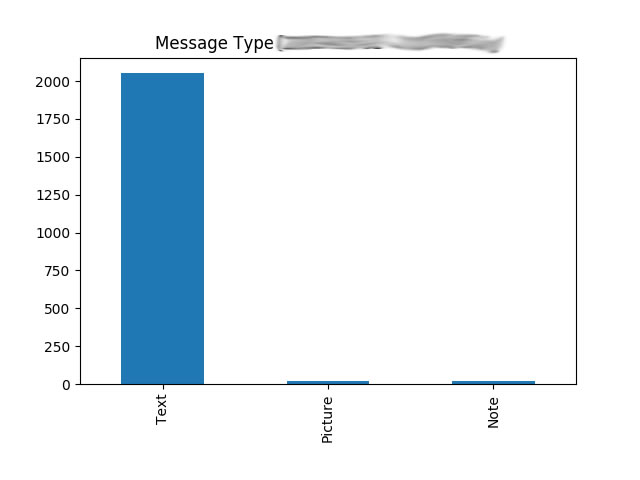
2. 消息种类占比,生成Bar Chart
def gen_bar_plot_msg_type ( self , csv_file ) :
df = pd . read_csv ( csv_file , delimiter ='\t' , encoding ='utf-8' )
df [ 'msg_type' ] . value_counts ( ) . plot ( kind ='bar' )
plt . subplots_adjust ( bottom =0.2 )
plt . title ( 'Message Type [%s - %s]' % ( self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
path_image = os.path . join ( self . path_analyse ,
'%s_chat_msg_type_bar_%s_%s.png' % ( self . group_id , self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
plt . savefig ( path_image )
plt . close ( )
return path_image
分析:
聊天以文字信息为主,没有出现其他灌水群的斗图行为。
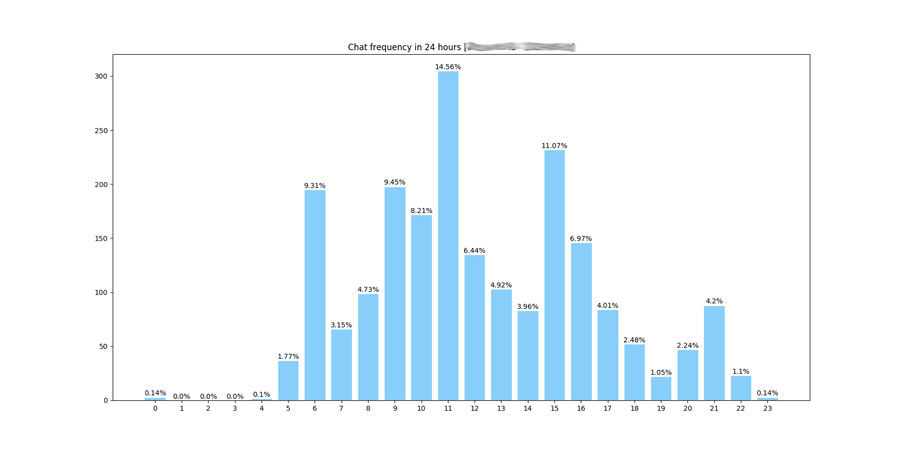
3. 日均聊天频率,生成Bar Chart
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def gen_bar_plot_chat_freq_day ( self , csv_file ) :
df = pd . read_csv ( csv_file , delimiter ='\t' , encoding ='utf-8' )
msg_count = len ( df )
time_list = self . cal_time_list_chat_freq_day ( df )
plt . figure ( figsize =( 18 , 9 ) )
plt . bar ( time_list . keys ( ) , time_list . values ( ) , width =. 8 , facecolor ='lightskyblue' , edgecolor ='white' )
plt . xticks ( range ( len ( time_list ) ) , time_list . keys ( ) )
for x_axies in time_list :
y_axies = time_list [ x_axies ]
label = '{}%' . format ( round ( y_axies *1.0 /msg_count *100 , 2 ) )
plt . text ( x_axies , y_axies +0.05 , label , ha ='center' , va ='bottom' )
plt . title ( 'Chat frequency in 24 hours [%s - %s]' % ( self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
path_image = os.path . join ( self . path_analyse ,
'%s_chat_freq_day_bar_%s_%s.png' % ( self . group_id , self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
plt . savefig ( path_image )
plt . close ( )
return path_image
分析:
每日从六点开始活跃,估计是一部分人上班通勤坐车时有时间聊聊
早七八点到公司开始工作,安静
早九、十点开始活跃,到午休11点左右到达高峰
午休后工作时间
下午三点开始活跃,这时是德企里的下午茶时间
晚9点饭后再次活跃一下
4. 群员聊天活跃时间周热点图, 输出Heat Map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def gen_heatmap_member_activity ( self , csv_file ) :
df = pd . read_csv ( csv_file , delimiter ='\t' , encoding ='utf-8' )
create_times = df [ 'create_time' ]
week_online = [ [ 0 for j in range ( 24 ) ] for i in range ( 7 ) ]
for li in create_times :
week_online [ int ( mk_datetime ( li , "%Y-%m-%d %H:%M:%S" ) . weekday ( ) ) ] [ int ( li [ 11 : 13 ] ) ] += 1
week_online = np . array ( [ li for li in week_online ] )
columns = [ str ( i ) + '-' + str ( i + 1 ) for i in range ( 0 , 24 ) ]
index = [ 'Mon.' , 'Tue.' , 'Wed.' , 'Thu.' , 'Fri.' , 'Sat.' , 'Sun.' ]
week_online = pd . DataFrame ( week_online , index =index , columns =columns )
plt . figure ( figsize =( 18.5 , 9 ) )
plt . rcParams [ 'font.sans-serif' ] = [ 'SimHei' ]
sns . set ( )
# Draw a heatmap with the numeric values in each cell
sns . heatmap ( week_online , annot =True , fmt ="d" , cmap ="YlGnBu" )
path_image = os.path . join ( self . path_analyse ,
'%s_activity_heatmap_%s_%s.png' % ( self . group_id , self . fl_days [ 0 ] , self . fl_days [ 1 ] ) )
plt . savefig ( path_image , format ='png' , dpi =300 )
plt . close ( )
return path_image
分析:
周一大家都很忙,或者装着很忙的样子
周二下午开始活跃了
周三上午也活跃起来
周四,快到周末了,放松,全天活跃
周五,上午欢乐时光,下午和德国同事一样,走的走跑的跑
周末死一般沉寂
从这个分析图可以看出,中国程序员上班是非常用心和责任感的,同时也非常遵守德企工作时间相关制度,坚决不加班,坚决朝九晚五。
996是什么?能吃吗?
认真地说,为工作和任务有限加班是可以的,但我非常反对无效的为加班而加班,把996作为KPI考勤标准的做法。
德国大中型企业一般做法是员工自行调配加班时间,某段时间任务紧,加班时间多了的话可以将超时存起来,之后再换成休假;实在没空休假的可以换成工资,不过一般HR和工会不推荐这么做,超时太多将强制休假—-员工健康比工作重要。
在德企小公司或咨询公司里,就不一定了,因为可能业绩和分红挂钩,或者小公司项目紧张,主动或被动加班是很常见的。
绝大多数IT企业并不固定员工的上下班时间,而是采用核心时间制度,比如10-15这五个小时员工必须在岗,但员工可以自行决定上班和下班时间,早来早走,晚来晚走,自由度高。
2-2-4. 制作pdf总报表
以上数据分析步骤生成了若干独立的图片报表,不便传阅,可以将其集中整理并且排版格式化到一个pdf总报表里,方便阅读。
所需第三方库如下,可以将含图片的html页面完整输出成pdf文件。
pip3 install pdfkit
Install wkhtmltopdf
Debian /Ubuntu :
> sudo apt -get install wkhtmltopdf
Redhat /CentOS
> sudo yum install wkhtmltopdf
MacOS
> brew install Caskroom /cask /wkhtmltopdf
开发分解
1. 准备HTML模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
< ! DOCTYPE html >
< html lang ="en" >
< head >
< meta charset ="UTF-8" >
<style>
h1 {
text-align : center ;
}
h2 {
text-align : center ;
margin-top : 20px ;
}
img {
display : block ;
margin : 0 auto ;
}
</style>
< /head >
< body >
< h1 > { { group_name } } 聊天数据分析< /h1 >
< h2 > { { date_begin } } - { { date_end } } < /h2 >
< h2 > 24 小时内聊天频率< /h2 >
< img src ="{{img_chat_freq_day}}" style ="width:100%;" />
< h2 > 消息类型< /h2 >
< img src ="{{img_chat_msg_type}}" style ="width:80%;" />
< h2 > 日均聊天数量< /h2 >
< img src ="{{img_chat_count_day}}" style ="width:100%;" />
< h2 > 群友活跃时间热点图< /h2 >
< img src ="{{img_chat_heating_act}}" style ="width:100%;" />
< div class ="divider_b" > < /div >
. . . . . .
2. 生成pdf
读取HTML模板,替换Pattern,生成pdf
with open ( './assets/chat_analysis_%s.html' % lang , 'r' ) as file :
file_data = file . read ( )
# 替换Pattern
file_data = file_data . replace ( '{{date_begin}}' , self . fl_days [ 0 ] )
file_data = file_data . replace ( '{{date_end}}' , self . fl_days [ 1 ] )
file_data = file_data . replace ( '{{img_chat_history}}' , Path ( img_chat_history ) . name )
file_data = file_data . replace ( '{{img_chat_freq_day}}' , Path ( img_chat_freq_day ) . name )
. . . . . .
# 输出临时HTML文件
with open ( path_html , 'w' ) as file :
file . write ( file_data )
# 输出pdf
pdfkit . from_file ( path_html , path_pdf )
3. 定时任务
添加定时任务,每月第一天早八点自动启动数据分析任务,分析上个月数据,然后自动将pdf报表发到群里。
# 08:10am at the first day of the month
scheduler . add_job ( lambda : process_schedule ( bot_db , bot , group_1 ) , 'cron' ,
month ='1-12' , day =1 , hour =8 , minute =1 , timezone ="Europe/Paris" )
# 发送文件到指定群里
group . send_file ( file_path )
最终pdf报表预览:
2-3.
2-4. 总结
通过数据分析可以非常直观地了解工作和生活在德国的中国程序员们,平时做什么工作,说什么话题。不过因为采样数量较小,某些分析无法采用更明确的类别数量占比图,分析结果难免有偏差,还请见谅。
本文使用Python和相关库快速完成了数据采集,清洗和分析的工作,你可以基于该项目,扩展自己的数据分析模块,比如图灵聊天机器人,连接各类第三方服务。
文中聊天记录只短时间采集并供本文脱敏分析,后期清除不再继续监听。
项目源代码已上传至 GitHub ,欢迎指教和加星。
PS:@将记忆深埋 究竟在不在这几个IT群里,始终是个谜。
2-4-1. 参考资料
Figures on the EU Blue Card
76.000 Ausländer mit “Blauer Karte” in Deutschland
Der Stack Overflow Entwicklerreport 2017
2018年中国程序员数据调查表
https://statistik.arbeitsagentur.de/Statischer-Content/Arbeitsmarktberichte/Berufe/generische-Publikationen/Broschuere-Informatik.pdf











![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






