常规的日志收集方案中 Client 端都需要额外安装一个 Agent 来收集日志,例如 logstash、filebeat 等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实现日志收集呢?Rsyslog 就是你要找的答案!
Rsyslog 是高速的日志收集处理服务,它具有高性能、安全可靠和模块化设计的特点,能够接收来自各种来源的日志输入(例如:file,tcp,udp,uxsock 等),并通过处理后将结果输出的不同的目的地(例如:mysql,mongodb,elasticsearch,kafka 等),每秒处理日志量能够超过百万条。
Rsyslog 作为 syslog 的增强升级版本已经在各 linux 发行版默认安装了,无需额外安装。
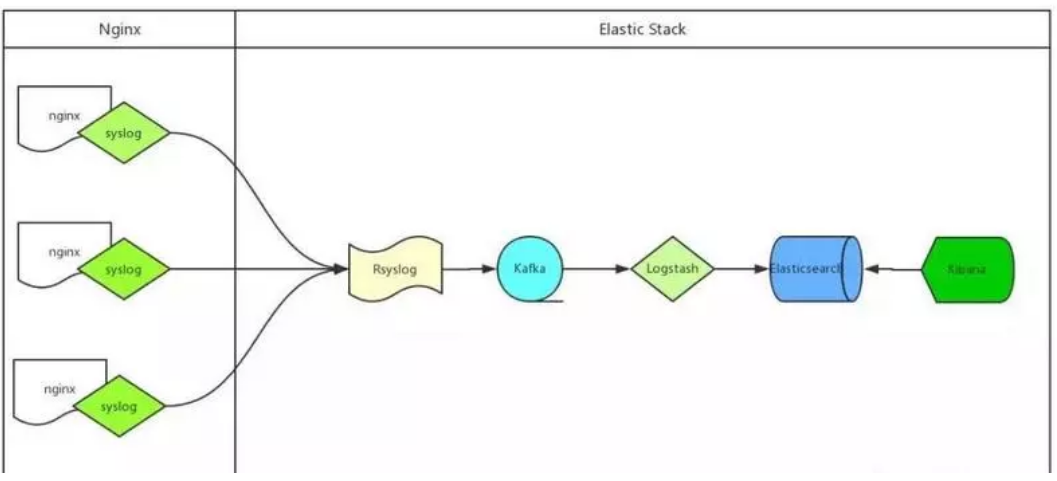
ELK 通过 Rsyslog 收集日志流程图如下:
处理流程为:Nginx –syslog–> Rsyslog –omkafka–> Kafka –> Logstash –> Elasticsearch –> Kibana;
Nginx 产生日志通过 syslog 系统服务传给 Rsyslog 服务端,Rsyslog 接收到日志后通过 omkafka 模块将日志写入 Kafka,Logstash 读取 Kafka 队列然后写入 Elasticsearch,用户通过 Kibana 检索 Elasticsearch 里存储的日志。
Rsyslog 服务系统自带无需安装,所以整个流程中客户端不需要额外安装应用。
服务端虽然 Rsyslog 也已安装,但默认没有 omkafka 模块,如果需要 Rsyslog 写入 Kafka 需要先安装这个模块。
omkafka 模块在 rsyslog v8.7.0 之后的版本才支持,所以需要先通过rsyslogd -v命令查看 rsyslog 版本,如果版本较低则需要升级。
添加 rsyslog 源的 key
# apt-key adv --recv-keys --keyserver keys.gnupg.net AEF0CF8E
添加 rsyslog 源地址
echo "deb http://debian.adiscon.com/v8-stable wheezy/" > > /etc /apt /sources . list
echo "deb-src http://debian.adiscon.com/v8-stable wheezy/" > > /etc /apt /sources . list
升级 rsyslog 服务
# apt-get update && apt-get -y install rsyslog
安装编译工具,下边 autoreconf 需要用到,不然无法生成 configure 文件
# apt-get -y install pkg-config autoconf automake libtool unzip<strong>omkafka 需要安装一堆的依赖包</strong>
# apt-get -y install libdbi-dev libmysqlclient-dev postgresql-client libpq-dev libnet-dev librdkafka-dev libgrok-dev libgrok1 libgrok-dev libpcre3-dev libtokyocabinet-dev libglib2.0-dev libmongo-client-dev libhiredis-dev
# apt-get -y install libestr-dev libfastjson-dev uuid-dev liblogging-stdlog-dev libgcrypt-dev
# apt-get -y install flex bison librdkafka1 librdkafka-dev librdkafka1-dbg
编译安装 omkafka 模块
# mkdir tmp && cd tmp
# git init
# git pull git@github.com:VertiPub/omkafka.git
# autoreconf -fvi
# ./configure --sbindir=/usr/sbin --libdir=/usr/lib --enable-omkafka && make && make install && cd ..
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
log_format jsonlog '{'
'"host": "$host",'
'"server_addr": "$server_addr",'
'"http_x_forwarded_for":"$http_x_forwarded_for",'
'"remote_addr":"$remote_addr",'
'"time_local":"$time_local",'
'"request_method":"$request_method",'
'"request_uri":"$request_uri",'
'"status":$status,'
'"body_bytes_sent":$body_bytes_sent,'
'"http_referer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"upstream_addr":"$upstream_addr",'
'"upstream_status":"$upstream_status",'
'"upstream_response_time":"$upstream_response_time",'
'"request_time":$request_time'
'}' ;
access_log syslog : server =rsyslog . domain . com , facility =local7 , tag =nginx_access_log , severity =info jsonlog ;
Nginx 在 v1.10 之后的版本才支持 syslog 的方式处理日志,请确保你的 Nginx 版本高于 1.10;
为了降低 logstash 的处理压力,同时也为了降低整个配置的复杂度,我们 nginx 的日志直接采用 json 格式;
抛弃文本文件记录 nginx 日志,改用 syslog 直接将日志传输到远端的 rsyslog 服务器,以便我们后续的处理;这样做的另一个非常重要的好处是我们再也无需考虑 nginx 日志的分割和定期删除问题(一般我们为了方便管理通常会采用 logrotate 服务来对日志进行按天拆分和定期删除, 以免磁盘被占满)。
access_log 直接输出到 syslog 服务,各参数解释如下:
syslog :指明日志用 syslog 服务接收;server :接收 syslog 发送日志的 Rsyslog 服务端地址,默认使用 udp 协议,端口是 514;facility :指定记录日志消息的类型,例如认证类型 auth、计划任务 cron、程序自定义的 local0-7 等,没有什么特别的含义,不必深究,默认的值是 local7;tag :给日志添加一个 tag,主要是为了方便我们在服务端区分是哪个服务或者 client 传来的日志,例如我们这里给了 tag:nginx_access_log,如果有多个服务同时都写日志给 rsyslog,且配置了不通的 tag,在 rsyslog 服务端就可以根据这个 tag 找出哪些是 nginx 的日志;severity :定义日志的级别,例如 debug,info,notice 等,默认是 error。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# cat /etc/rsyslog.d/rsyslog_nginx_kafka_cluster.conf
module ( load ="imudp" )
input ( type ="imudp" port ="514" )
# nginx access log ==> rsyslog server(local) ==> kafka
module ( load ="omkafka" )
template ( name ="nginxLog" type ="string" string ="%msg%" )
if $ inputname == "imudp" then {
if ( $ programname == "nginx_access_log" ) then
action ( type ="omkafka"
template ="nginxLog"
broker =[ "10.82.9.202:9092" , "10.82.9.203:9092" , "10.82.9.204:9092" ]
topic ="rsyslog_nginx"
partitions . auto ="on"
confParam =[
"socket.keepalive.enable=true"
]
)
}
: rawmsg , contains , "nginx_access_log" ~
在 rsyslog.d 目录下添加一个专门处理 nginx 日志的配置文件;
rsyslog 配置文件重要配置解释如下:
module :加载模块,这里我们需要加载 imudp 模块来接收 nginx 服务器 syslog 发过来的日志数据,也需要加载 omkafka 模块来将日志写入到 kafka。input :开启 udp 协议,端口 514,也可以同时开启 tcp 协议,两者可以共存。template :定义一个模板,名字叫 nginxLog,模板里可以定义日志的格式,因为我们传的已经是 json 了,不需要再匹配格式,所以这里不额外定义,注意模板名字要唯一。action :在匹配到 inputname 为 imudp 且 programname 为 nginx_access_log(就是我们上边 nginx 配置里边的 tag)之后的处理方式,这里的配置为匹配到的日志通过 omkafka 模块写入 kafka 集群,还有一些关于 omkafka 更详细的配置参考上边给出的 omkafka 模块官方文档。:rawmsg, contains :最后这一行的意思是忽略包含 nginx_access_log 的日志,没有这一行的话 rsyslog 服务默认会把所有日志都记录到 message 里边一份,我们已经把日志输出到 kafka 了,本地就没必要再记录了。
omkafka 模块检查 kafka 里边 topic 是否存在,如果不存在则创建,无需手动创建 kafka 的 topic。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
input {
kafka {
bootstrap_servers => "10.82.9.202:9092,10.82.9.203:9092,10.82.9.204:9092"
topics => [ "rsyslog_nginx" ]
}
}
filter {
mutate {
gsub => [ "message" , "\\x" , "\\\x" ]
}
json {
source => "message"
}
date {
match => [ "time_local" , "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => [ "10.82.9.205" , "10.82.9.206" , "10.82.9.207" ]
index => "rsyslog-nginx-%{+YYYY.MM.dd}"
}
}
重要配置参数解释如下:
input :配置 kafka 的集群地址和 topic 名字;filter :一些过滤策略,因为传入 kafka 的时候是 json 格式,所以不需要额外处理,唯一需要注意的是如果日志中有中文,例如 url 中有中文内容时需要替换\x,不然 json 格式会报错。output :配置 ES 服务器集群的地址和 index,index 自动按天分割。
配置完成后分别重启 rsyslog 服务和 nginx 服务,访问 nginx 产生日志。
查看 kafka 是否有正常生成 topic。
# bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181
__consumer_offsets
rsyslog_nginx
查看 topic 是否能正常接收日志
# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic rsyslog_nginx
{ "host" : "domain.com" , "server_addr" : "172.17.0.2" , "http_x_forwarded_for" : "58.52.198.68" , "remote_addr" : "10.120.89.84" , "time_local" : "28/Aug/2018:14:26:00 +0800" , "request_method" : "GET" , "request_uri" : "/" , "status" : 200 , "body_bytes_sent" : 1461 , "http_referer" : "-" , "http_user_agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" , "upstream_addr" : "-" , "upstream_status" : "-" , "upstream_response_time" : "-" , "request_time" : 0.000 }
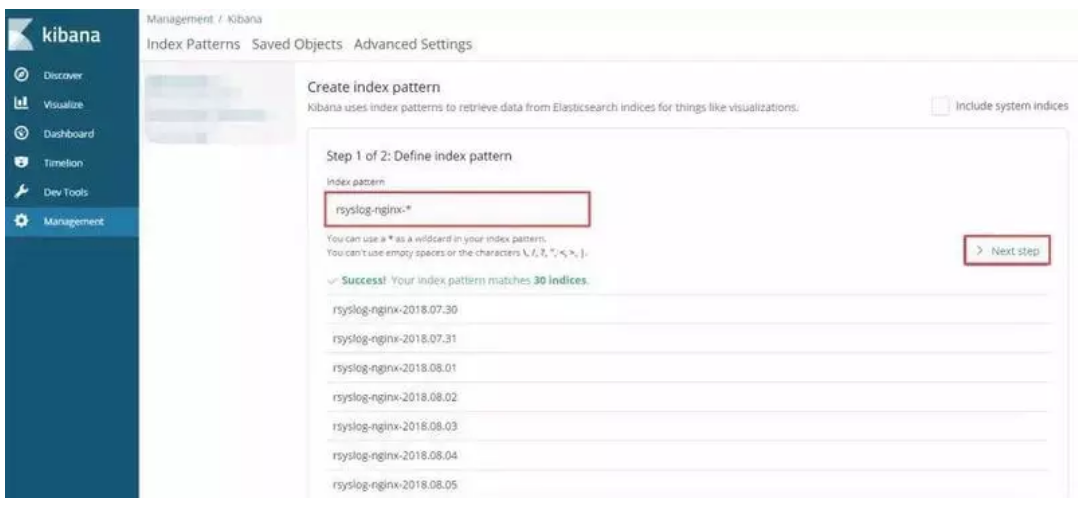
kibana 添加 index,查看 Elasticsearch 中是否有数据,如果前两步都正常,kibana 搜不到 index 或 index 没有数据,多半是 index 名字写错了之类的基础问题,仔细检查。
打开 Kibana 添加rsyslog-nginx-*的 Index,并选择 timestamp,创建 Index Pattern。
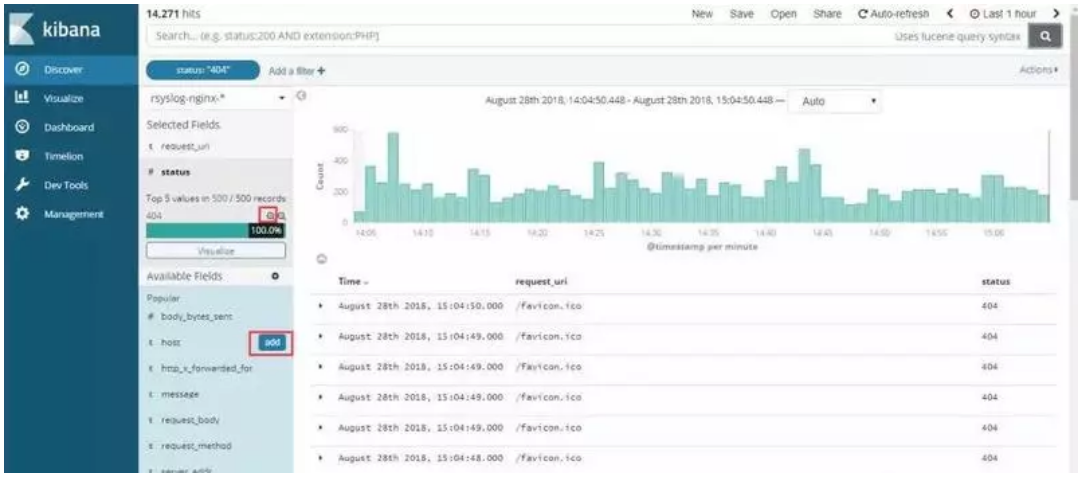
进入 Discover 页面,可以很直观的看到各个时间点请求量的变化,根据左侧 Field 实现简单过滤,例如我们想查看所有访问状态为 404 的 uri,可以点击 request_uri 和 status 后边的 add,这两项的内容将出现在右侧,然后点击 status 下边 404 状态码后边的加号,则只查看状态为 404 的请求,点击上方 auto-refresh 可以设置页面自动刷新时间。
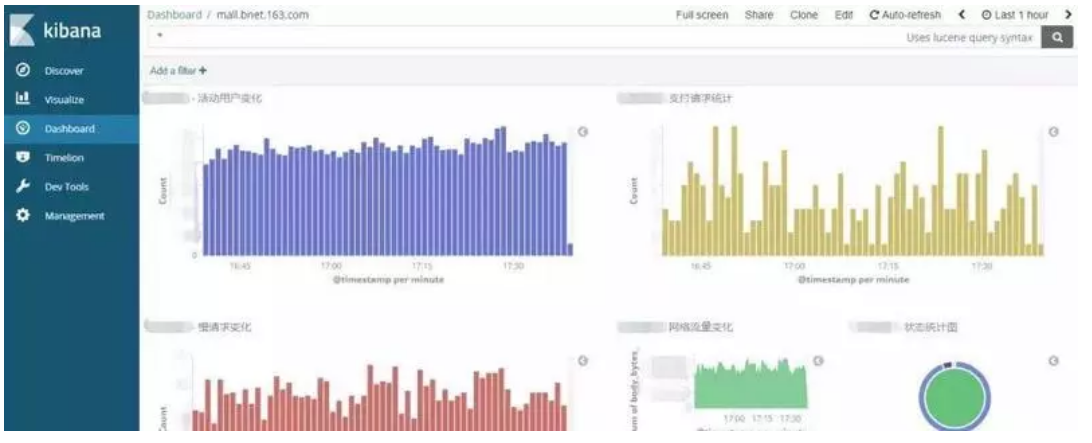
通过各种条件的组合查询可以实现各种各样的需求,例如每秒请求、带宽占用、异常比例、慢响应、TOP IP、TOP URL 等等各种情况,并且可以通过 Visualize 很方便的将这些信息绘制图标,生成 Dashboard 保存。
Nginx 的 access log 绝对是网站的一个宝藏,通过日志量的变化可以知道网站的流量情况,通过对 status 状态的分析可以知道我们提供服务的可靠性,通过对特定活动 url 的追踪可以实时了解活动的火爆程度,通过对某些条件的组合查询也能为网站运营提供建议和帮助,从而使我们的网站更友好更易用;
Rsyslog 服务的单点问题可以通过部署多个 Rsyslog 服务过三层负载来保证高可用,不过以我们的经验来说 rsyslog 服务还是很稳定的,跑了一年多,每分钟日志处理量在 20w 左右,没有出现过宕机情况,不想这么复杂的话可以写个 check rsyslog 服务状态的脚本跑后台,挂了自动拉起来;
整个过程中我们使用了 UDP 协议,第一是因为 Nginx 日志的 syslog 模式默认支持的就是 UDP 协议,翻了官网没找到支持 TCP 的方式,我想这也是考虑到 UDP 协议的性能要比 TCP 好的多,第二也考虑到如果使用 TCP 遇到网络不稳定的情况下可能会不停的重试或等待,影响到 Nginx 的稳定。对于因为内容过长超过以太网数据帧长度的问题暂时没有遇到。
补充
1. 根据geoip实现地理信息可视化
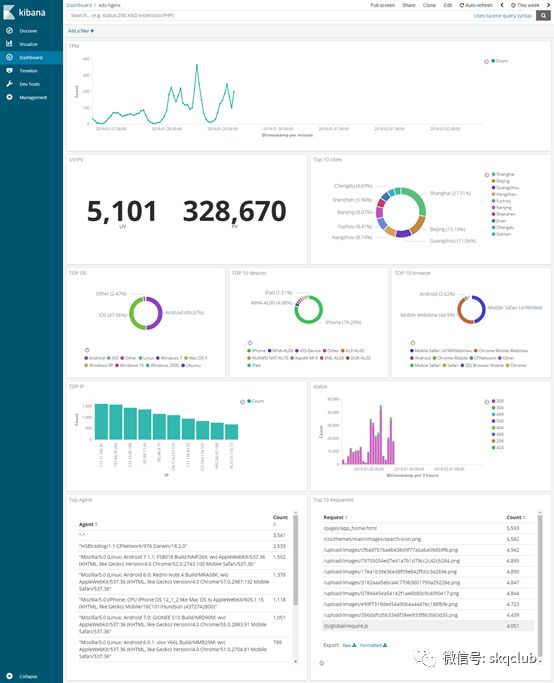
我们采集了Nginx的access日志并通过ELK做了如下的概览分析,其中包括:TPM(Tansaction per minute)、UV/PV、top 10 cities、TOP OS、TOP 10 devices、TOP 10 browser、TOP IPs、Status及TOP 10 Request,效果如下:
这些可视化数据的实现主要分三步:
数据提取收集; 数据结构化; 数据可视化 ;
本次主要分享第二点和第三点,即如何将收集到的数据结构化和可视化。
数据结构化
我们从access.log文件中随便取一条来分析:
220.248.110.165 - - [ 25 /Jan /2019 : 21 : 27 : 18 +0800 ] "GET/appServer/account/login/accountLogin.json?jsonpCallback=checkLoginCode_1548422789887&mobile=138****2230&password=h%2FsAdzihQ26S046EA1ObAuRCcHC0binJw3ztpChJH%2F50SVvZbzSWQetW2sNJIM0CZh0OALX51z%2BEhGpTiREFaA%3D%3D&loginexplain=Mozilla/5.0%20(Windows%20NT%206.1;%20WOW64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/71.0.3578.98%20Safari/537.36&channel=mobileweb&_=1548422782082HTTP/1.1" 200 384 "https://xxx.xxxx.com/pages/asset.html" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/71.0.3578.98 Safari/537.36"
这里如果根据nginx默认的结构化配置可以获得的字段有:
$ remote_addr - $ remote_user [ $ time_local ] "$request" $ status $ body_bytes_sent "$http_referer" "$http_user_agent"
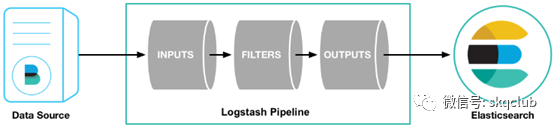
我们知道ELK是流式的数据处理模式,Filebeat采集数据,Kafka做数据消息池,Elasticsearch存储数据,Logstash做数据的中转,所以数据的结构化处理在Logstash这里实现。
回忆下logstash的管道模式(输入、过滤器、输出),输入接受来自文件、kafka、beats等各方的数据、输出到ES,所以数据分析结构化的核心工作又都集中在了过滤器部分:
Logstash是通过filter过滤器来进行数据处理的,并且提供了丰富的插件,本文使用了使用了json、grok、geoip、useragent和mutate这五个插件,简介如下:
Json:将json格式数据转化为field字段;
grok:将非结构化数据通过正则匹配结构化;
geoip:将IP地址国家城市化;
useragent:将请求的agent结构分析出来;
mutate:格式转换,比如字符串转化为浮点数;
其中grok的正则规则配置在logstash/vendor/bundle/jruby/x.x/gems/logstash-patterns-core-xxx/patterns/grok-patterns文件中,logstash自带的grok正则中有Apache的标准日志格式:
COMMONAPACHELOG % { IPORHOST : clientip } % { HTTPDUSER : ident } % { USER : auth } \ [ % { HTTPDATE : timestamp } \ ] "(?:%{WORD:verb} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" % { NUMBER : response } ( ? : % { NUMBER : bytes } | -)
COMBINEDAPACHELOG % { COMMONAPACHELOG } % { QS : referrer } % { QS : agent }
我们对比参考写出nginx的匹配格式:
NGINXACESS % { IPORHOST : clientip } ( % { HTTPDUSER : ident } | -) ( % { HTTPDUSER : auth } | -) \ [ % { HTTPDATE : timestamp } \ ] "(?:%{WORD:method} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" % { NUMBER : response } ( ? : % { NUMBER : bytes } | -) % { QS : referrer } % { QS : agent }
不过到这里还只能获取基本的请求字段,还不能根据IP知道是哪个国家的哪个城市,也不能根据agent分析出用户使用的是什么手机、什么操作系统以及哪个浏览器,这部分使用了插件geoip和useragent,最终logstash的配置filter代码如下:
数据结构化后如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
{
"_source" : {
"response" : "200" ,
"message" : "220.248.110.165 - - [25/Jan/2019:21:27:18+0800] \"GET/appServer/account/login/accountLogin.json?jsonpCallback=checkLoginCode_1548422789887&mobile=138****2230&password=h%2FsAdzihQ26S046EA1ObAuRCcHC0binJw3ztpChJH%2F50SVvZbzSWQetW2sNJIM0CZh0OALX51z%2BEhGpTiREFaA%3D%3D&loginexplain=Mozilla/5.0%20(Windows%20NT%206.1;%20WOW64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/71.0.3578.98%20Safari/537.36&channel=mobileweb&_=1548422782082HTTP/1.1\" 200 384 \"https://xxx.xxx.com/pages/asset.html\"\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/71.0.3578.98 Safari/537.36\"" ,
"browseragent" : {
"name" : "Chrome" ,
"os" : "Windows 7" ,
"major" : "71" ,
"build" : "" ,
"patch" : "3578" ,
"os_name" : "Windows 7" ,
"minor" : "0" ,
"device" : "Other"
} ,
"@timestamp" : "2019-01-25T13:27:19.720Z" ,
"method" : "GET" ,
"referrer" : "\"https://xxx.xxx.com/pages/asset.html\"" ,
"type" : "xds_nginx" ,
"ident" : "-" ,
"timestamp" : "25/Jan/2019:21:27:18 +0800" ,
"bytes" : "384" ,
"agent" : "\"Mozilla/5.0 (Windows NT 6.1; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98Safari/537.36\"" ,
"geoip" : {
"country_name" : "China" ,
"ip" : "220.248.110.165" ,
"latitude" : 31.0456 ,
"country_code3" : "CN" ,
"region_name" : "Shanghai" ,
"timezone" : "Asia/Shanghai" ,
"country_code2" : "CN" ,
"city_name" : "Shanghai" ,
"region_code" : "31" ,
"coordinates" : [
121.3997 ,
31.0456
] ,
"continent_code" : "AS" ,
"longitude" : 121.3997 ,
"location" : {
"lon" : 121.3997 ,
"lat" : 31.0456
}
} ,
"clientip" : "220.248.110.165" ,
"@version" : "1" ,
"offset" : 34829616 ,
"request" : "/appServer/account/login/accountLogin.json?jsonpCallback=checkLoginCode_1548422789887&mobile=138****2230&password=h%2FsAdzihQ26S046EA1ObAuRCcHC0binJw3ztpChJH%2F50SVvZbzSWQetW2sNJIM0CZh0OALX51z%2BEhGpTiREFaA%3D%3D&loginexplain=Mozilla/5.0%20(Windows%20NT%206.1;%20WOW64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/71.0.3578.98%20Safari/537.36&channel=mobileweb&_=1548422782082" ,
"auth" : "-" ,
"httpversion" : "1.1" ,
"highlight" : {
"request" : [
"jsonpCallback=checkLoginCode_1548422789887&mobile=@kibana-highlighted-field@138****2230@/kibana-highlighted-field@&password=h%2FsAdzihQ26S046EA1ObAuRCcHC0binJw3ztpChJH%2F50SVvZbzSWQetW2sNJIM0CZh0OALX51z%2BEhGpTiREFaA%3D%3D&loginexplain=Mozilla/5.0%20(Windows%20NT%206.1;%20WOW64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/71.0.3578.98%20Safari/537.36&channel=mobileweb&_=1548422782082"
]
}
数据可视化
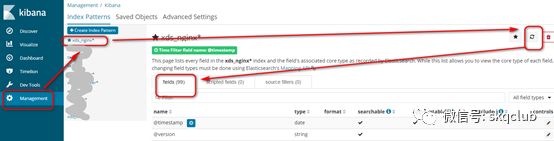
有了字段的结构化后的数据后,通过Kibana来实现数据可视化部分,注意在配置各模块之前需要刷新下索引信息 ,否则进来的结构数据不会生效
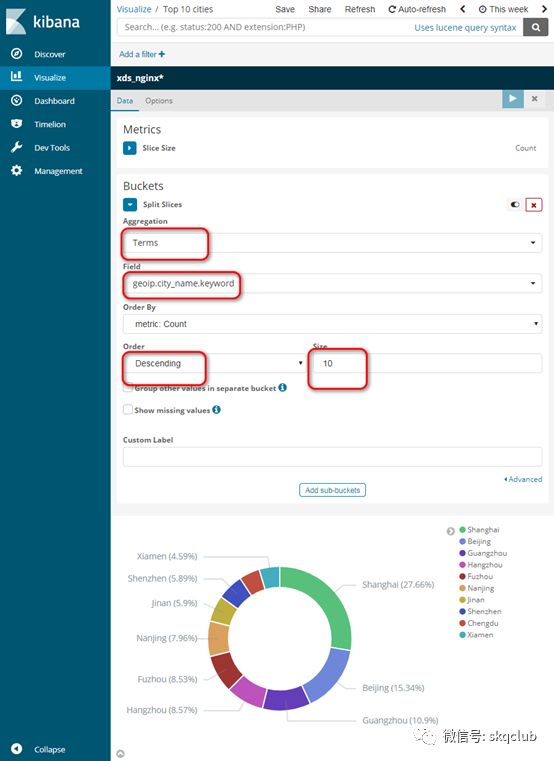
我们以访问IP所在地的城市数据为例:
根据上图设置便可以统计一段时间内的访问情况,我们设置的可视化模块如下:
备注:
问: syslog可以直接到logstash。为什么用 kafaka,rsyslog,难道只为了避免syslog将log存为文件?

![[转]小白都能看懂的Hadoop架构原理](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






