[转]不管你的Redis集群规模有多大,都是时候思考下如何提升资源利用率了

Redis 是互联网产品开发中不可缺少的常备武器,它性能高、数据结构丰富、简单易用,但同时也是因为太容易用了,我们的开发同学不管什么数据、不管这数据有多大、不管数据有多少通通塞进去,最后导致的问题就是 Redis 内存使用持续上升,但是又不知道里面的数据是不是有用,是否可以拆分和清理。
为了更好地使用 Redis,除了对 Redis 做一些使用规范,还需要对线上使用的 Redis 有充分的了解。那么问题来了:一个 Redis 的实例用了那么大的内存,里边到底存了啥?都有哪些 key?每个 key 占用了多少空间?
雪球当前有几十个 Redis 集群,近千个 Redis 实例,5T 的内存数据,我们也想要分析业务是否有误用,以提高资源利用率。当然,曾经我们也深深地被这个问题所困扰,今天我就来和大家分享下我是如何解决这个问题的,希望能给各位一些启发。
那有没有什么办法让我们安全高效的看到 Redis 内存消耗的详细报表呢?办法总比问题多,有需求就有解决方案。雪球 SRE 团队针对这个问题实现了一个 Redis 数据可视化平台 RDR (Redis Data Reveal)。RDR 可以非常方便的对 Reids 的内存进行分析,了解一个 Redis 实例里都有哪些 key,哪类 key 占用的空间是多少,最耗内存的 key 有哪些,占比如何,非常直观。
1. 设计思路
我们先梳理下,有什么办法可以拿到 Redis 的所有数据。从我的角度看,大概有以下几种方法,我们分析一下个字的优缺点:
1. 先通过 keys * 命令,拿到所有的 key,然后根据 key 再获取所有的内容。
- 优点:可以不使用 Redis 机器的硬盘,直接网络传输
- 缺点:如果 key 数量特别多,keys 命令可能会导致 Redis 卡住影响业务;需要对 Redis 请求非常多次,资源消耗多;遍历数据太慢
2. 开启 aof,通过 aof 文件获取到所有数据。
- 优点:无需影响 Redis 服务,完全离线操作,足够安全;
- 缺点:有一些 Redis 实例写入频繁,不适合开启 aof,普适性不强;aof 文件有可能特别大,传输、解析起来太慢,效率低。
3. 使用 bgsave,获取 rdb 文件,解析后获取数据。
- 优点:机制成熟,可靠性好;文件相对小,传输、解析效率高;
- 缺点:bgsave 虽然会 fork 子进程,但还是有可能导致主进程卡住一段时间,对业务有产生影响的风险;
以上几种方式我们评估之后,决定采用低峰期在从节点做 bgsave 获取 rdb 文件,相对安全可靠,也可以覆盖所有业务的 Redis 集群。也就是说每个实例每天在低峰期自动生成一个 rdb 文件,即使报表数据有一天的延迟也是可以接受的。
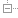
拿到了 rdb 文件就相当于拿到了 Redis 实例的所有数据,接下来就是生成报表的过程了:
- 解析 rdb 文件,获取到 Key 和 Value 的内容;
- 根据相对应的数据结构及内容,估算内存消耗等;
- 统计并生成报表;
逻辑很简单,所以设计思路很清晰。数据流图如下:
我们再看下具体该如何实现,首先是语言选型,雪球 SRE 自研的组件基本都是用 Go 语言做的后端,所以语言选型没什么纠结,直接用 Go。然后就是刚刚说的那几个流程。
1-1. 1. 解析 RDB
按照 Redis 的协议来做就可以了,这个在 GitHub 上搜索 parse rdb 就可以找到许多解析 rdb 文件的库,拿过来使用即可。我们使用了 https://github.com/cupcake/rdb。
1-2. 2. 估算内存消耗
一条记录会有哪些内存使用呢?
我们知道 Redis 的实现里面有一些基础的数据结构,就是用这些结构来实现了对外暴露的各种数据类型:比如 sds、dict、intset、zipmap、adlist、ziplist、quicklist、skiplist 等等。只要根据这条记录的数据类型,找出使用了哪些数据结构,再计算出这些基础数据结构的内存消耗,再加上数据的内存使用,以及一些额外开销比如过期时间等,就可以估算出一条记录到底使用了多少内存。
但是由于 Redis 做了非常多的优化,同样的一种数据类型,在不同场景下使用的数据结构有可能是不同的。比如 List ,比较老版本的 Redis,会根据 list 元素的数量来决定来使用哪种结构,较短的时候使用 adlist,长之后使用 ziplist,数值可以通过 list-max-ziplist-entries 来配置。
3.2 版本以后全都使用了 quicklist。而不同结构对于内存的使用其实是有区别的,我们计算的时候也没办法拿到具体的配置,所以都按默认配置来计算,最后得出的值是一个估算的值,不过也基本可以反应使用情况了。如果大家对于 Redis 使用的各种数据结构感兴趣,想了解其设计及适用场景,可以多搜索一下相关的资料以及阅读 Redis 源码。
举个计算内存使用的例子:
假如我们通过解析 rdb,获取到了一个 key 为 hello,value 为 world,类型为 string ,ttl 为 1440 的一条记录,它的内存使用是这样的:
- 一个 dictEntry 的消耗,Redis db 就是一个大 dict,每对 kv 都是其中的一个 entry ;
- 一 个 robj 的消耗,robj 是为了在同一个 dict 内能够存储不同类型的 value,而使用的一个通用的数据结构,全名是 Redis Object;
- 存储 key 的 sds 消耗,sds 是 Redis 中存储字符串使用的数据结构;
- 存储过期时间消耗;
- 存储 value 的 sds 消耗;
前四项基本是存储任何一个 key 都需要消耗的,最后一项根据 value 的数据结构不同而不同。
- 一个 dictEntry 有 2 个指针,一个 int64 的内存消耗;
- 一个 robj 有 1 指针,一个 int,以及几个使用位域的字段共消耗 4 字节;
- 过期时间也是存储为一个 dictEntry,时间戳为 int64;
- 存储 sds 需要存储 header 以及字符串长度 +1 的空间,header 长度根据字符串长度不同也会有所不同;
我们根据以上信息可以算出,向操作系统申请这些内存,真正需要多少内存。由于 Redis 支持多种 malloc 算法,我们就按 jemalloc 的分配方式算,这里也是可能存在误差的点。
所以最后 key 为 hello 的这条记录在 64 位操作系统上一共会消耗 92 字节。

其他类型的计算也大致是同样的思路,只不过根据不同的数据结构需要计算不同的内存消耗,计算的时候要记得考虑内存对齐的情况。还有由于 zset 的算法涉及到了随机生成层数,我们也使用同样的算法来随机,但是算出来的值肯定不是精确的,也是一个误差点。
1-3. 3. 统计计数
终于可以拿到任何一个 key 的内存使用了,哪些是最有意义最有价值的数据呢?
- top N,毫无疑问最大的前 N 个 key 一定是要关注的;
- 不同数据类型的 key 数量元素数量分布以及内存使用情况;
- 按照前缀分类,统一的前缀一般意味着某个特定的业务在使用,计算各个分类的 key 数量及内存使用情况;
这几个需求实现起来也都很容易:
- 维护一个小顶堆来存储前 N 个最大的即可,最后取出堆中的数据即可;
- 计数即可;
- 一般都会有特定的分隔符,比如 :|._ 等字符,按照这些字符切出公共前缀再统计,同时把所有的数字都替换为 0,便于分类;
1-4. 4. 报表数据
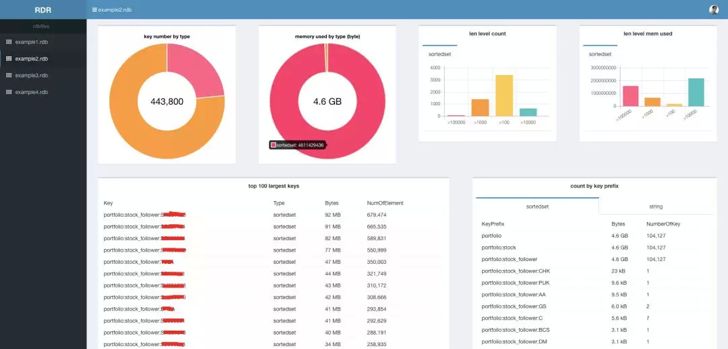
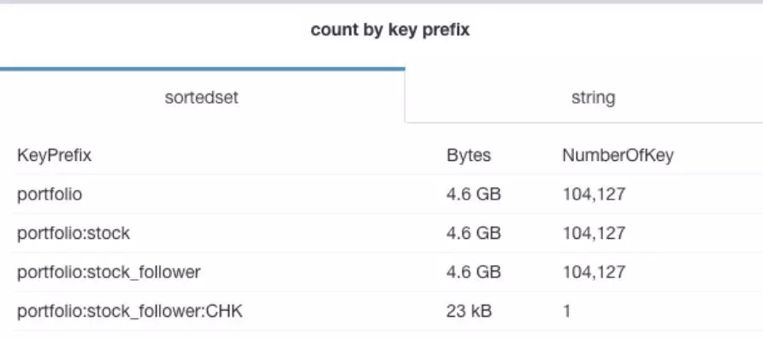
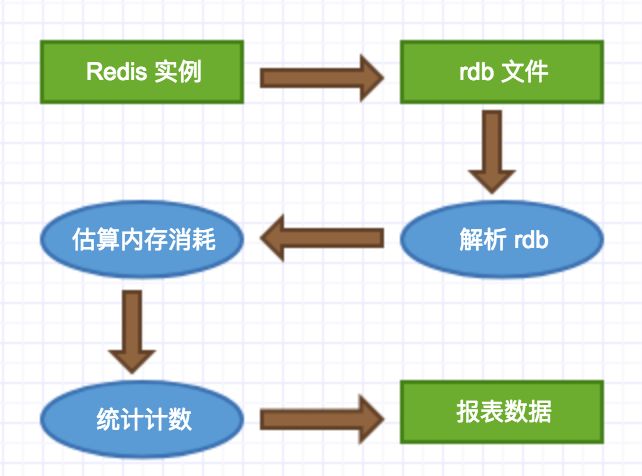
可以每天打开个网页就可以看到某个 Redis 实例的内存使用的详细情况,是件非常幸福的事情,Redis 的内存使用再也不是黑盒。
这个系统上线一年以来对我们优化 Redis 资源使用、提高效率、节约成本提供了非常重要的数据支撑,而且在内部完全自动化,开发同学自己就可以看到当前 Redis 的使用情况是否符合预期,对于保障业务稳定也起到了非常重要的作用。这也是雪球的工程师团队一贯的做法,SRE 提供高效的工具,开发工程师可以自己运维自己的业务系统,可以极大的提高生产效率。
这个项目参考了 redis-rdb-tool 这个开源项目,但是性能上比它高效几倍,为了回馈社区,也希望有机会帮到大家,所以我们决定开源出来。
雪球的内部系统根据自己的特殊场景做了自动化获取 rdb 文件并备份的逻辑,开源出来的版本去除了定制化,只保留了获取到 rdb 之后的分析逻辑以及页面。
项目地址为 https://github.com/xueqiu/rdr。有任何问题可以提 issue,也可以直接邮件联系我:dongmx@xueqiu.com。
![[转]Redis Cluster怎么持久化的](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)