[转]云平台 Linux 服务器问题场景分析思路及工具箱
作者整理了云平台 Linux 服务器(下文中区分了物理机及虚拟机)运维中的常见问题场景、分析工具箱及判别思路,主要针对中高级 linux 服务器运维人员。
1. 前言
本文主要结合笔者在苏宁云平台支撑工作中的实践,以基于经验切实有效的判定分析方式贯穿, 整理了云平台 Linux 服务器(下文中区分了物理机及虚拟机)运维中的常见问题场景、分析工具箱及判别思路。主要包含以下三部分:
1. Linux 服务器 CPU、I/O、内存性能异常的常用工具、判定标准、以及分析思路。
2. Linux 服务器异常宕机的故障可能的原因、定位方法与常规分析思路。
3. Linux 服务器丢包的问题可能的原因、定位方法与常规分析思路。
读者范围:中高级 linux 服务器运维人员
注:本文结合问题图景枚举了各个 tool 与分析关联较大的参数及用法,以起到一个示例说明,各工具的详细用法需要自行阅读研习 man 手册。
2. CPU 异常
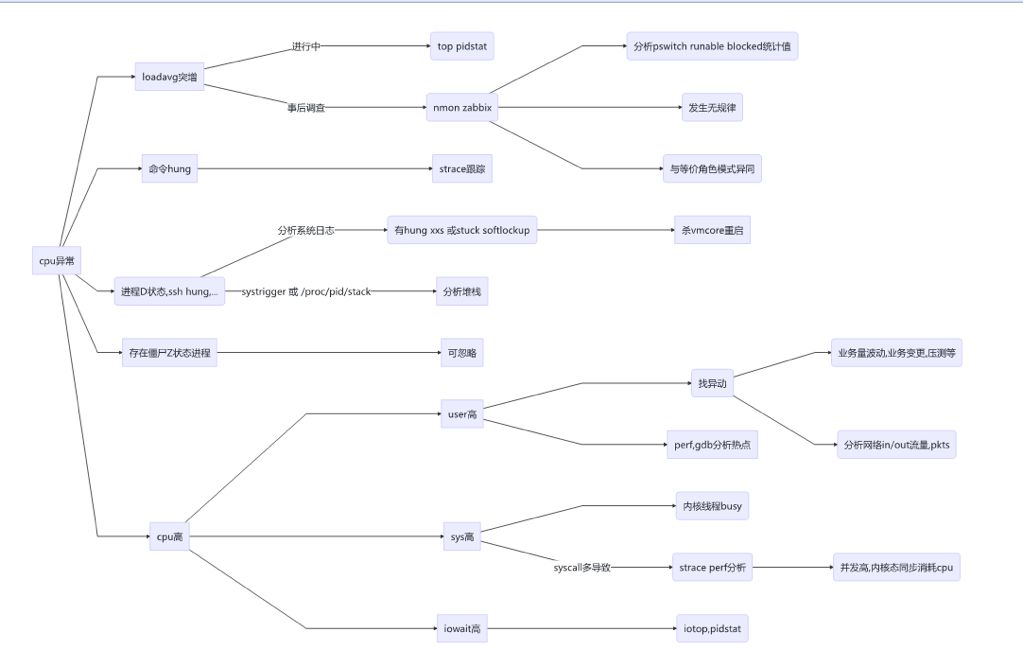
-d 磁盘读写报告 I/O 统计
-r 内存使用及缺页
-u CPU
-l 展示命令行及参数
-w switch
-t 显示线程的统计
-T
-b 块统计
-B 页面
-r 页面使用统计
-R 页面回收统计
-d 磁盘使用统计
-q 调度统计
-S swap
-m 运行频率
-v 文件 inode dentry 活动统计
-w 调度 switch
-W 换入换出统计
-n 网络 DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6 and UDP6
-s 00:00:00 -e 00:21:00 指明要查看的开始结束时间
NMON Visulizar 是来自于 IBM 的 Nmon 可视化分析工具
-c 统计系统调用次数及时间
-f 也 trace 子进程调用
-e 指明关心的调用 eg. -e open,write
eg:
bt 查看执行堆栈
frame 切换工作帧
perf top 在线采样及展示:
-e 指明事件,默认是 cycle,全部时间可 perf list 查询
-G 调用图
-F 采样频率
-d 刷新间隔
-p 特定进程
-C 特定核
perf record/report
record 输出采样文件 perf.data 文件
report 解析
3. 内存异常
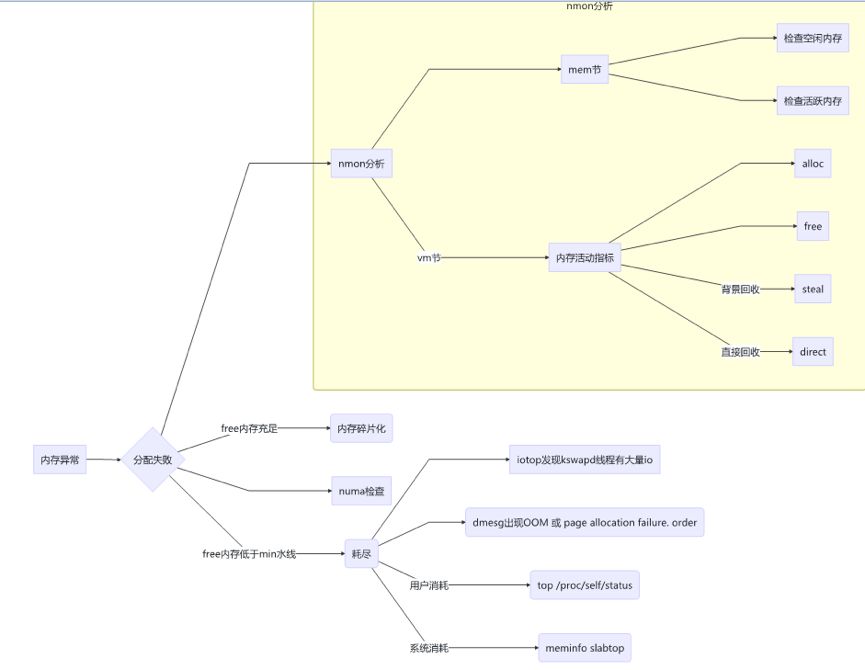
sysctl -a|grep extra_free_kbytes min_free_kbytes extra_free_kbytes 的组合值构成三个水线。
1. 直接回收线 MIN min_free_kbytes
2. 后台回收线 LOW 5/4* min_free_kbytes + extra_free_kbytes
3. 后台回收停止 HIGH 3/2* min_free_kbytes + extra_free_kbytes
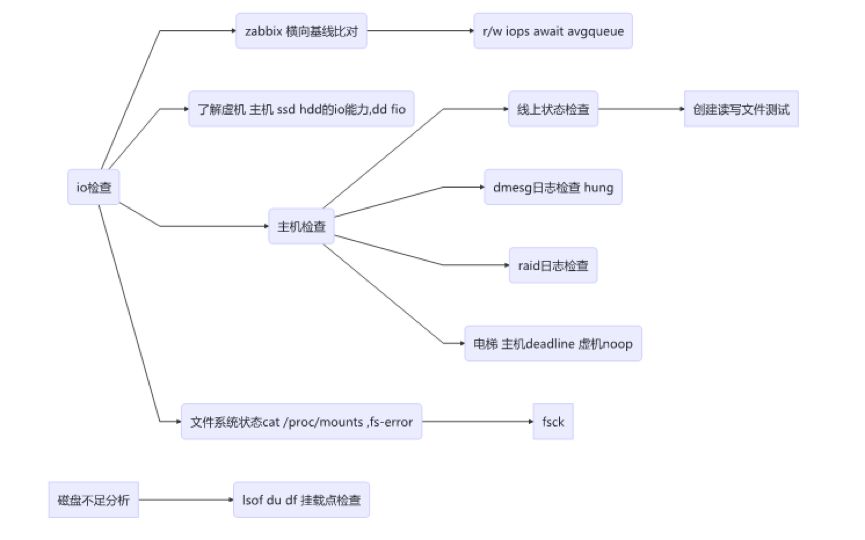
cfq deadline noop
当意外的 I/O 延迟发生,需要深入了解 I/O 延迟分布,需要使用 blktrace & blkparser 工具进行细致分析。
学会合理使用 oflag 标志 sync 同步刷出数据 direct 绕过 pagecache。
用来标定系统 I/O 能力的便捷工具:
面向块占用及文件系统占用的查询分析:strace 可以看出两个命令原理的差异:df 读取文件系统信息,du stat 各个文件然后累加。
4. 网络异常场景
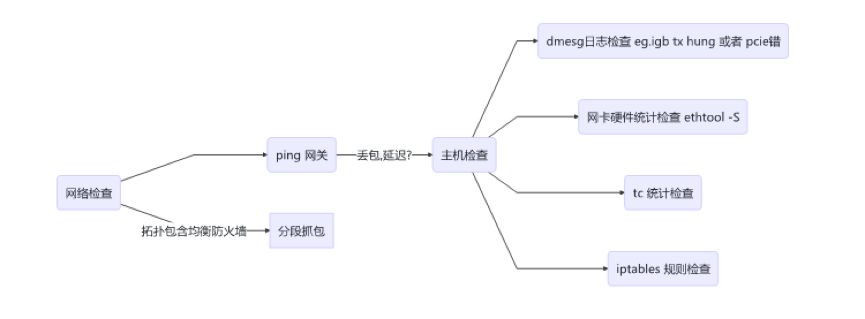
-i 待抓取的网口名字
-w 抓包文件,可以是时间格式化串
-G 回滚时长,单位秒
-c 抓取多少个包后退出
-s 抓取部分报文,单位字节
-r 读取抓包文件离线分析
-z 调用 gzip 等工具做压缩
-Z 切换 user 运行,默认是 tcpdump
-B 设置 buf 大小,不然抓不全单位 KB 10240
5. 宕机场景分析
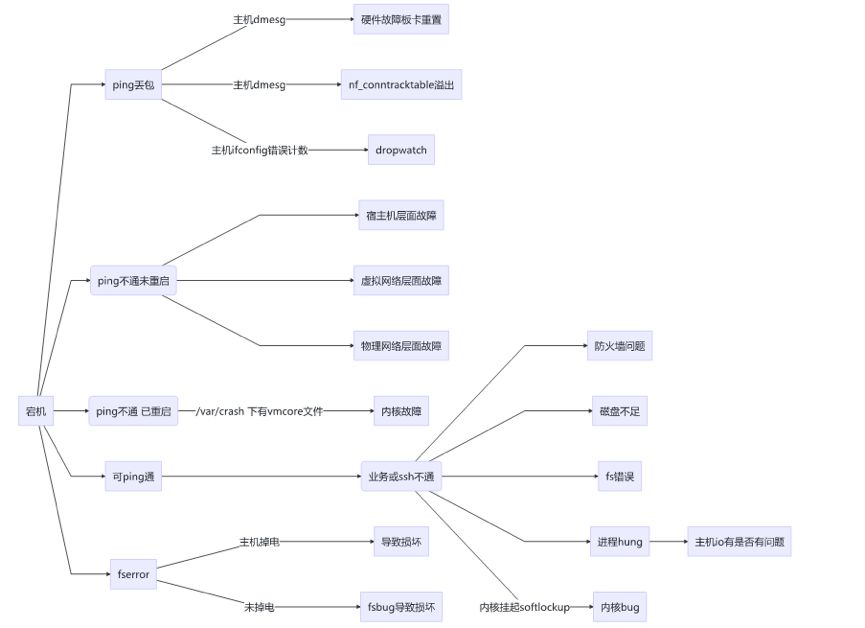
log 查看宕机关联日志
bt 查看宕机位置
sys 查看基本信息
6. 总结
本文场景化地总结了云平台几类常见的 Linux 服务器异常分析思路及 toolset, 篇幅所限无法面面俱到,但如开篇提到,真正的快速有效的问题判别定位离不开对系统领域的熟悉与细致缜密的判断,以场景化方式灵活地运用好工具箱,达到由表及里、由浅入深的理解系统,快速高效解决线上问题。
作者简介
谢英豪,苏宁科技集团云平台中心高级工程师,长期耕耘于 Linux 内核及操作系统的支撑领域,保障苏宁云环境线上海量 KVM Server Farm 的稳定高效运行。
[source]云平台 Linux 服务器问题场景分析思路及工具箱

![[汇总]DevOps资源](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






