[转]关于负载均衡的一切
什么是负载均衡?
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据均匀分摊到多个操作单元上执行,负载均衡的关键在于均匀。
常见的负载均衡方案有哪些?
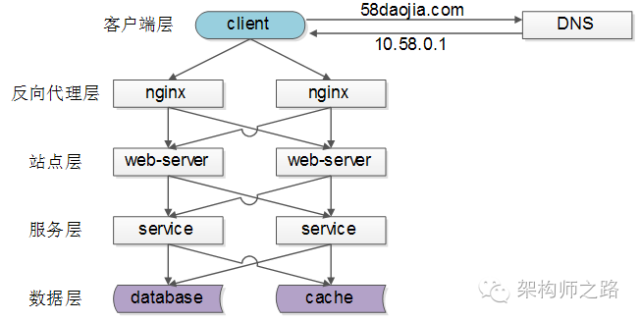
常见互联网分布式架构如上,分为:
- 客户端层
- 反向代理层
- 站点层
- 服务层
- 数据层
可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现整体的均匀分摊。
第一层:客户端层到反向代理层
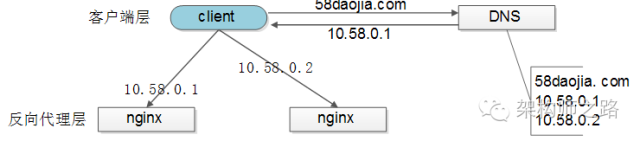
客户端层到反向代理层的负载均衡,是通过“DNS轮询”实现的。
DNS-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问DNS-server,会轮询返回这些ip,保证每个ip的解析概率是相同的。这些ip就是nginx的外网ip,以做到每台nginx的请求分配也是均衡的。
假设你快速检测到故障,可以通过更新 DNS 配置(手动方式或使用软件)来停止引用损坏的服务器。
遗憾的是,由于 DNS 记录是有缓存的,这些缓存记录可能会在客户端或者 DNS 层次结构中的其他名称服务器中,在它们过期之前,大约有 50% 的请求仍然可能失败。DNS 记录的 TTL(time to live,生存时间)通常为几分钟或更长,因此这会对系统的可用性造成重大影响。
更糟糕的是一些客户端完全忽略了 TTL,所以一些请求将在一段时间内被定向到已经宕机的 web 服务器上。设置非常短的 DNS TTL 也不是什么好主意;这意味着 DNS 服务的负载增加,延迟增加,因为客户端不得不更加频繁地执行 DNS 查找。如果你的 DNS 服务不可用,那么使用更短的 TTL 访问服务将更快地降级,因为缓存服务 IP 地址的客户端更少。
第二层:反向代理层到站点层
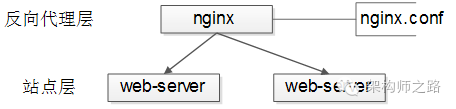
反向代理层到站点层的负载均衡,是通过“nginx”实现的。
画外音:nginx是反向代理的泛指, 4 层(Layer 4)网络均衡器
修改nginx.conf,可以实现多种均衡策略:
(1) 请求轮询:和DNS轮询类似,请求依次路由到各个web-server;
(2) 最少连接路由:哪个web-server的连接少,路由到哪个web-server;
(3) ip哈希:按照访问用户的ip哈希值来路由web-server,只要用户的ip分布是均匀的,请求理论上也是均匀的,ip哈希均衡方法可以做到,同一个用户的请求固定落到同一台web-server上,此策略适合有状态服务,例如session;
画外音:站点层可以存储session,但强烈不建议这么做,站点层无状态是分布式架构设计的基本原则之一,session最好放到数据层存储。
(4) 4 层均衡器可以进行健康检查,并仅仅向那些通过检查的 web 服务器发送流量。与 DNS 均衡不同的是,如果一个 web 服务器崩溃,将流量重定向到另一个 web 服务器上的延迟很小,尽管现有连接将被重置。
4 层均衡器可以做加权平均,处理不同容量的后端,它为运维人员提供了强大的能力和灵活性,同时在计算能力方面相对便宜。
第三层:站点层到服务层 (增加 7 层负载均衡)
随着时间的推移,你的客户开始对一些更加高级的特性提出要求。
虽然 4 层负载均衡器可以高效地在多个 web 服务器之间分配负载,但这种分配是只在源 IP 地址和目标 IP 地址、协议和端口上进行的。4 层均衡器对请求的内容一无所知,所以也无法实现很多高级特性。相对而言,7 层(L7)负载均衡器知道请求的结构和内容,可以做得更多。
在 7 层均衡器中可以实现的一些特性包括缓存、限流、错误注入和代价敏感的负载均衡(部分请求需要更多的服务端处理时间)。
它们还可以基于请求的属性(例如 HTTP cookies)进行均衡、终止 SSL 连接,并帮助抵御应用层拒绝服务(DoS)攻击。7 层均衡器成本较高,不易扩容——它们为处理请求做了更多的计算,而且每个活动请求都会消耗一些系统资源。在一个或多个 7 层均衡器池前运行 4 层均衡器可以帮助解决扩展问题。
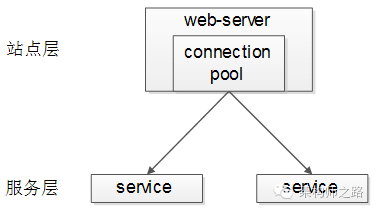
站点层到服务层的负载均衡,是通过“服务连接池”实现的。
上游连接池会建立与下游服务多个连接,每次请求会“随机”选取连接来访问下游服务。除了负载均衡,服务连接池还能够实现故障转移、超时处理、限流限速、ID串行化等诸多功能。
第四层:访问数据层
在数据量很大的情况下,由于数据层(db/cache)涉及数据的水平切分,所以数据层的负载均衡更为复杂一些,它分为“数据的均衡”,与“请求的均衡”。
数据的均衡是指:水平切分后的每个服务(db/cache),数据量是均匀的。
请求的均衡是指:水平切分后的每个服务(db/cache),请求量是均匀的。
业内常见的水平切分方式有这么几种:
一、按照range水平切分
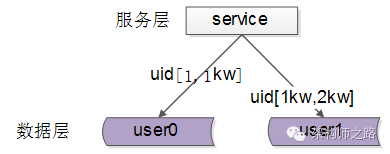
每一个数据服务,存储一定范围的数据:
- user0服务:存储uid范围1-1kw
- user1服务:存储uid范围1kw-2kw
这个方案的好处是:
- 规则简单,service只需判断一下uid范围就能路由到对应的存储服务
- 数据均衡性较好
- 比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务
不足是:
- 请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大
二、按照id哈希水平切分
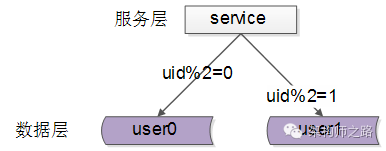
每一个数据服务,存储某个key值hash后的部分数据:
- user0服务:存储偶数uid数据
- user1服务:存储奇数uid数据
这个方案的好处是:
- 规则简单,service只需对uid进行hash能路由到对应的存储服务
- 数据均衡性较好
- 请求均匀性较好
不足是:
- 不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移
三、按照一致性hash算法切分
一致性hash算法本质上也是一种取模算法,不过,不同于上边按服务器数量取模,一致性hash是对固定值2^32取模。IPv4的地址是4组8位2进制数组成,所以用2^32可以保证每个IP地址会有唯一的映射
总结
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据均匀分摊到多个操作单元上执行,其的关键在于均匀:
- 反向代理层的负载均衡,是通过“DNS轮询”实现的
- 站点层的负载均衡,是通过“nginx”实现的
- 服务层的负载均衡,是通过“服务连接池”实现的
- 数据层的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”
[source]
https://opensource.com/article/18/10/internet-scale-load-balancing
![[转]“反向代理层”绝不能替代“DNS轮询”!](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






