[转]分布式缓存竟这样把注册中心搞垮
每当有机会写故障类主题的时候,我都会在开始前静静地望着显示器很久,经过多次煎熬和挣扎之后才敢提起笔来,为什么呢?
因为这样的话题很容易招来吐槽,比如 “说了半天,不就是配置没配好吗?”,或者 “这代码是猪写的吗?你们团队有懂性能测试的同学吗?”,这样的评论略带挑衅,而且充满了鄙视之意。
不过我觉得,在技术的世界里,多数情况都是客观场景决定了主观结果,而主观结果又反映了客观场景,把场景与结果串起来,用自己的方式写下来,传播出去,与有相同经历的同学聊上一聊,也未尝不是一件好事。
上个月,我们的系统因注册中心崩塌而引发的一场事故,本是一件稀松平常的事件,可我们猜中了开始却没料到原因,始作俑者竟是已在产线运行多年的某分布式缓存系统。
1. 回顾一下故障过程
这到底是怎么一回事呢?先来回顾一下故障过程。
11 月,某交易日的上午 10 点左右。在中间件监控系统没有触发任何报警的情况下,某应用团队负责人突然跑过来说:“怎么缓存响应这么慢?你们在干什么事吗?”
由于此正在交易盘中,中间件运维团队瞬间炸锅,紧急查看了一系列监控数据,先是通过 Zabbix 查看了如 CPU、内存、网络及磁盘等基础预警,一切正常,再查看服务健康状况,经过一圈折腾之后,也没发现任何疑点。
懵圈了,没道理啊。10 点 30 分,收到一通报警信息,内容为 “ZK 集群中的某一个节点故障,端口不通,不能获取 Node 信息,请迅速处理!”。
这简单,ZK 服务端口不通,重启,立即恢复。10 点 40 分,ZK 集群全部瘫痪,无法获取 Node 数据。
由于应用系统的 Dubbo 服务与分布式缓存使用的是同一套 ZK 集群,而且在此期间应用未重启过,因此应用服务自身暂时未受到影响。
没道理啊,无论应用侧还是缓存侧,近一个月以来都没有发布过版本,而且分布式缓存除了在 ZK 中存一些节点相关信息之外,基本对 ZK 无依赖。
10 点 50 分,ZK 集群全部重启,10 分钟后,再次瘫痪。神奇了,到底哪里出了问题呢?
10 点 55 分,ZK 集群全部重启,1 分钟后,发现 Node Count 达到近 22W+,再次崩溃。

10 点 58 分,通过增加监控脚本,查明 Node 源头来自分布式缓存系统的本地缓存服务。
11 点 00 分,通过控制台关闭本地缓存服务后,ZK 集群第三次重启,通过脚本删除本地化缓存所产生的大量 Node 信息。
11 点 05 分,产线 ZK 集群全部恢复,无异常。一场风波虽说过去了,但每个人的脸上流露出茫然的表情。
邪了门了,这本地缓存为什么能把注册中心搞崩塌?都上线一年多了,之前为什么不出问题?为什么偏偏今天出事?一堆的问号,充斥着每个人的大脑。
2. 我们本地缓存的工作机制
在这里,我就通过系统流程示意图的方式,简要的说明下我们本地缓存系统的一些核心工作机制。
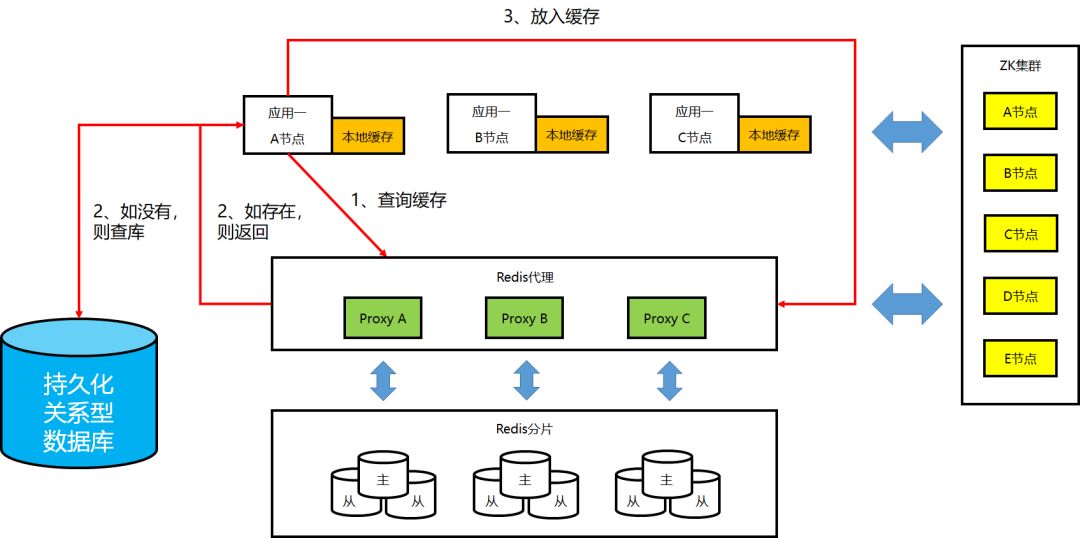
①非本地缓存的工作机制
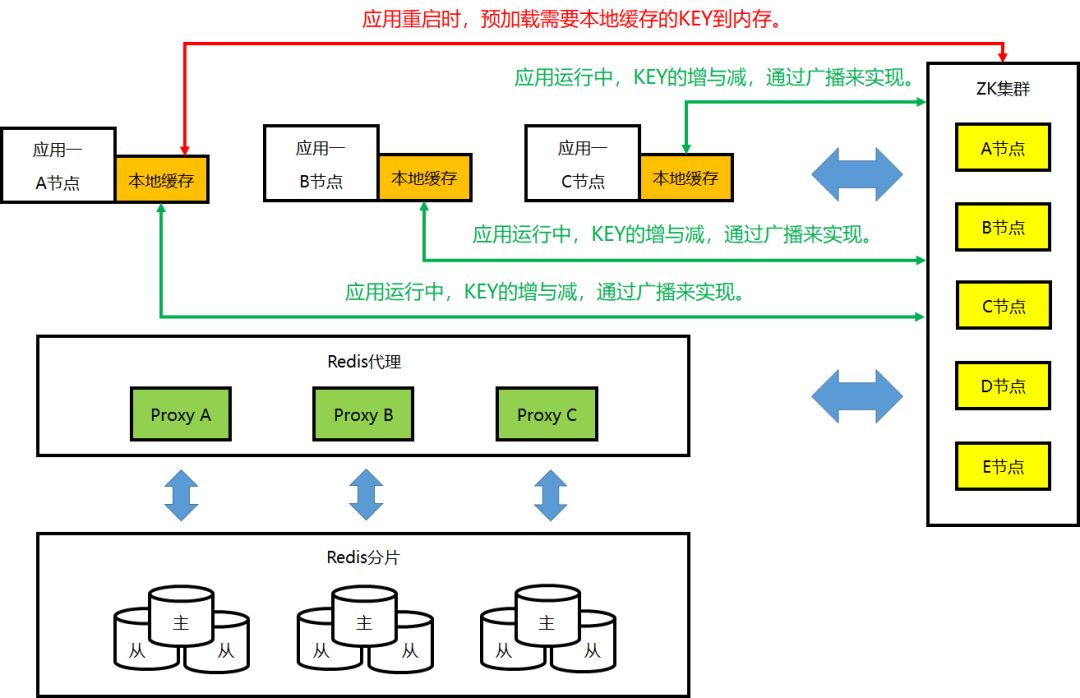
②本地缓存的工作机制:Key 预加载/更新
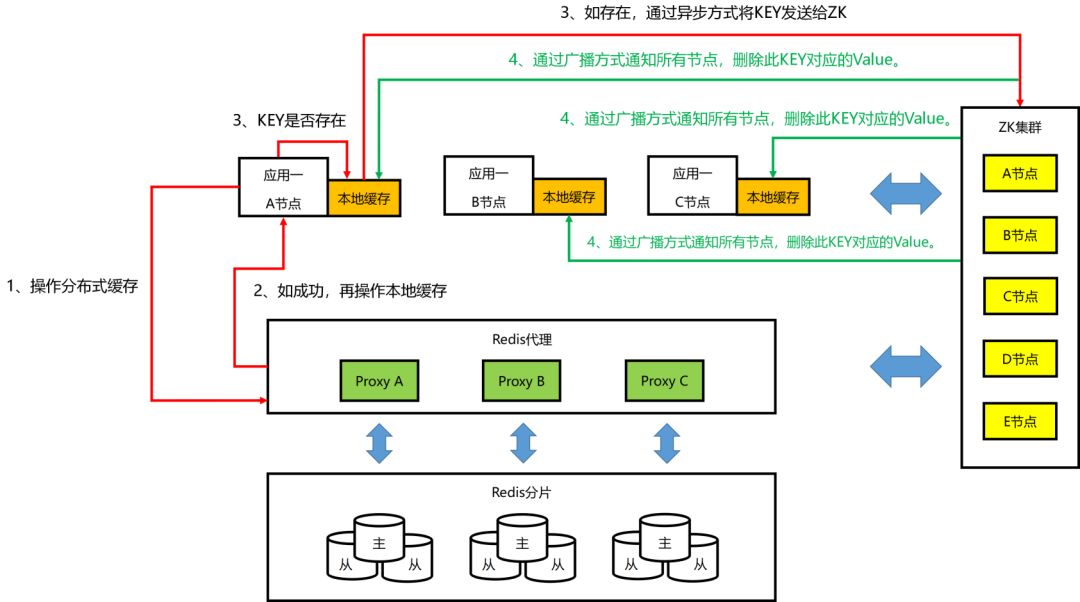
③本地缓存的工作机制:Set/Delete 操作
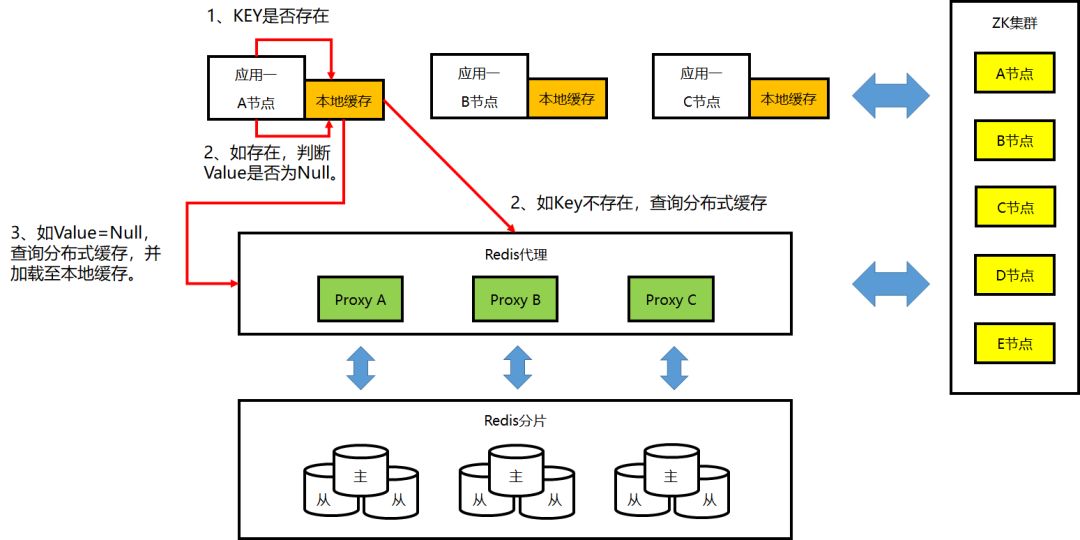
④本地缓存的工作机制:Get 操作
顺带提一句,由于历史性与资源紧缺的原因,我们部分缓存系统与应用系统的 ZK 集群是混用的,正因如此,给本次事故埋下了隐患。
3. ZK 集群是怎样被搞挂的呢?
说到这里,相信对中间件有一定了解的人基本能猜出本事件的全貌。
简单来说,就是在上线初期,由于流量小,应用系统接入量小,我们本地缓存的消息通知是利用 ZK 来实现的,而且还用到了广播。
但随着流量的增加与应用系统接入量的增多,消息发送量成倍增长,最终达到承载能力的上限,ZK 集群崩溃。的确,原因基本猜对了,但消息发送量为什么会成倍的增长呢?
根据本地缓存的工作机制,我们一般会在里面存些什么呢?
- 更新频率较低,但访问却很频繁,比如系统参数或业务参数。
- 单个 Key/Value 较大,网络消耗比较大,性能下降明显。
- 服务端资源匮乏或不稳定(如 I/O),但对稳定性要求极高。
懵圈了,就放些参数类信息,而且更新频率极低,这样就把五个节点的 ZK 集群打爆了?
为了找到真相,我们立即进行了代码走读,最终发现了蹊跷。
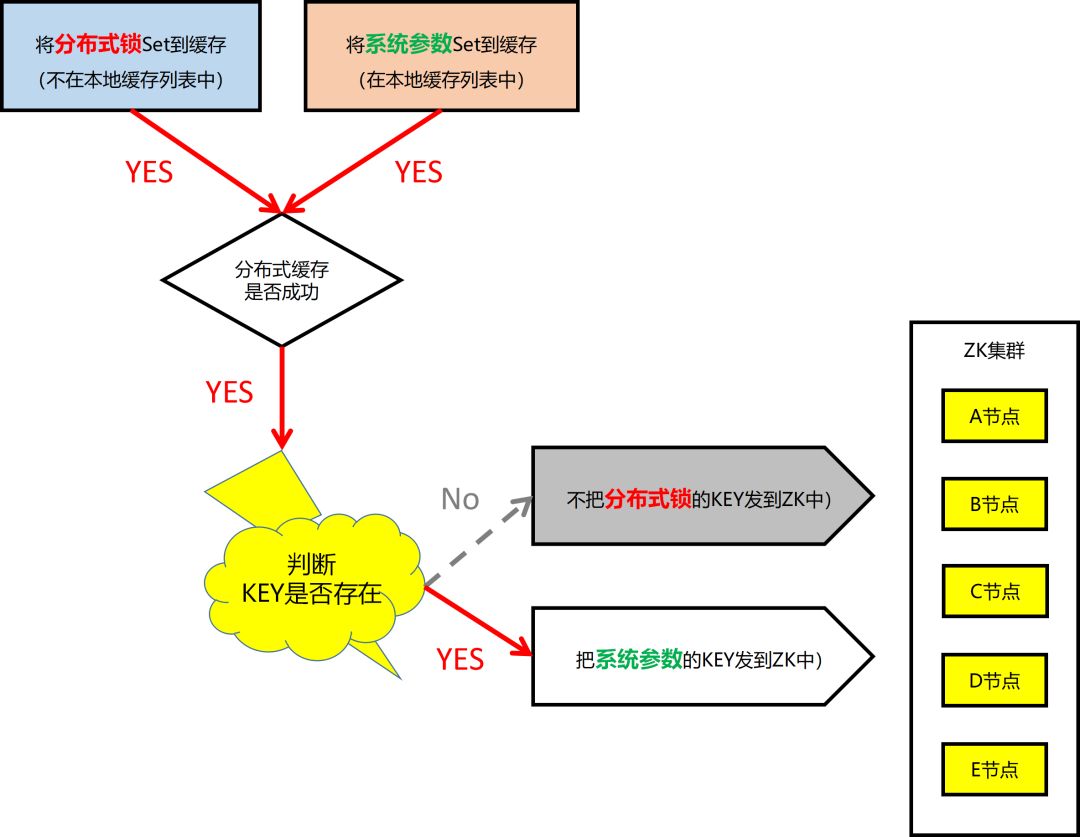
根据设计,在 “本地缓存的工作机制 – Set/Delete 操作” 的工作机制中,当一个 Key 完成服务端缓存操作后,如果没有被加到本地缓存规则列表中的 Key,是不可能被触发消息通知的。
但这里明显存在 Bug,导致把所有的 Key 都发到了 ZK 中。
这样就很好理解了,虽然应用系统近期没有发布版本,但却通过缓存控制台,悄悄地把分布式锁加到了这套缓存分片中,所以交易一开盘,只需几十分钟,立马打爆。
另外,除了发现 Bug 之外,通过事后测试验证,我们还得出了以下几点结论:
- 利用 ZK 进行消息同步,ZK 本身的负载能力较弱,是否切换到 MQ?
- 监控手段的单一,监控的薄弱。
- 系统部署结构不合理,基础架构的 ZK 不应该与应用的 ZK 混用。

说到这里,这个故事也该结束了。
4. 讲在最后
看完这个故事,一些爱好怼人的小伙伴也许会忍不住发问。你们自己设计的架构,你们自己编写的代码,难道不知道其中的逻辑吗?这么低级的错误,居然还有脸拿出来说?
那可未必,对每个技术团队而言,核心成员的离职与业务形态的变化,都或多或少会引发技术团队对现有系统形成 “知其然,而不知其所以然” 的情况,虽说每个团队都在想方设法进行避免,但想完全杜绝,绝非易事。
作为技术管理者,具备良好的心态,把每次故障都看成是一次蝉变的过程,从中得到总结与经验,并加以传承,今后不再犯,那就是好样的。
不过,万一哪天失手,给系统来了个彻底瘫痪,该怎么办呢?祝大家一切顺利吧。
作者:王晔倞
[source]没想到,我们的分布式缓存竟这样把注册中心搞垮!

![[总结]QPS、TPS、RT,并发,流量,带宽,端口计算,吞吐量](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






