[转]图数据库真的比关系数据库更先进吗?

AI 前线导读:图数据库有很多用途,适用于比如反欺诈、智能推荐等等应用场景,也有人说:图数据库可以做到关系数据库可以做到的任何事情。那图数据库究竟是怎样存储这些数据的,为什么它能适用于上述那些场景,图数据库真的比关系数据库先进么?本文作者花了一些时间去认真了解了一下图数据库,并将与我们分享他对图数据库的一些心得体会。
1. 传闻中的图数据库
最近老是听到图数据库,说其有很多用处,例如:
- 智能问答
- 反欺诈
- 反洗钱
- 智能推荐
- ……
也听到有同事表示,图数据库可以做到关系数据库可以做到的任何事情,但我自身对图数据库的理解仅仅只局限于图的数据模型是:
- 有多个实体
- 实体之间有关系进行关联
如下, 引自 NEO4J 网站:
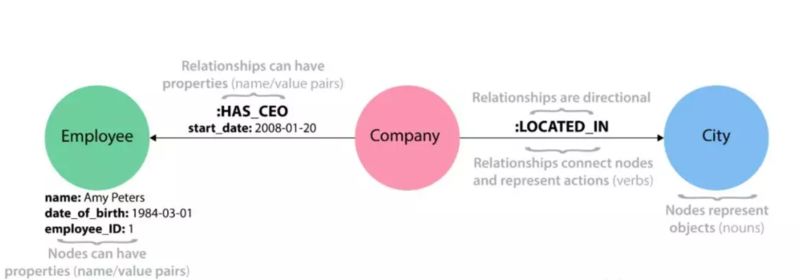
那图数据库究竟是怎样存储这些数据的,为啥它就能适用于上述那些场景,他真的比关系数据库先进么?
这一直成为我挥之不去的谜团,正好最近有空,了解了一下图数据库的基本概念及使用形式,终于对图数据库有了一个大致的认知。
2. 从 NEO4J 的 RDB VS GRAPH DB 文档中学习
对图数据库的入门我是从 NEO4J 的这篇文章开始的:
https://neo4j.com/developer/graph-db-vs-rdbms/
2-1. 关系数据库的存储模型
文章开始部分陈述了关系数据库的数据模型,如下图,引自 neo4j 网站:
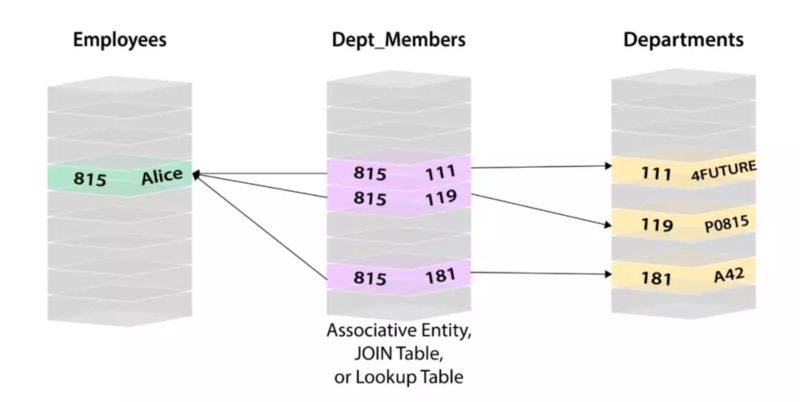
正确的说,这仅仅是 关系数据库范式 指导下设计的数据模型。
这里发散一下,数据库范式诞生于一个存储极为稀缺昂贵的年代,其指导思想是尽量少地占用存储以及同一份数据库不会有多个副本以避免不知道哪个是 source of truth 等问题。
目前在追求时间性能以及存储廉价的年代,已经没有多少人会按照范式设计数据库表了,反而,根据范式,故意反向实施,反而变成了一个提升性能的指导原则,哈。
在上面的关系数据库表设计示例中,我们可以看到,Employee 单独存储,Departments 单独存储,员工与部门的关系也单独存储,在获得一个员工从属于哪个部门时需要做表关联,对应到硬盘中,就是需要从硬盘的三大块区域,7 个磁盘位置,里找到 7 行数据后做处理才有结果。
也就是说在这个数据模型下,性能很低。
继续发散一下,实际这里,通过数据库范式的逆向操作能不能优化查询?
2-2. 图数据库的存储模型
然后文章继续介绍了图数据库下的存储模型,如下,引自 NEO4J 网站:
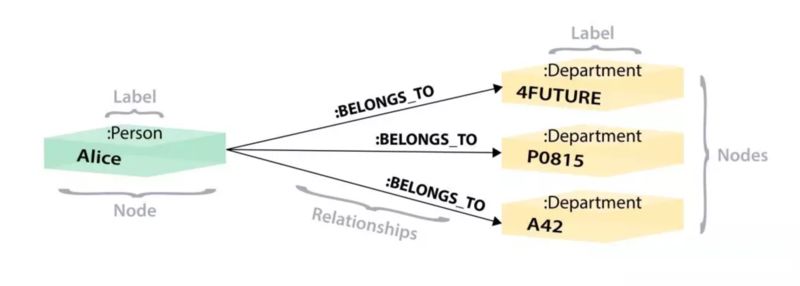
在图数据中,BELONGS 这个关系数据会跟实体数据 Alice 存储到一起,这样的话,就能大大地提升 “Alice 是哪个部门的员工”这个问题的解决速度,因为它减少了磁盘查询的次数,只需要从 4 个磁盘位置里拿到对应的数据即可。
以上差别是图数据库与传统关系数据库的最核心差别。
2-3. 图数据库的查询形式
其查询是使用一种叫 Cypher 的语言进行的,如下:
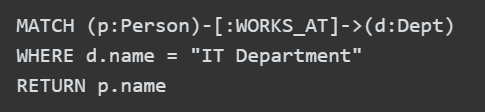
以上是一个查询语句,跟 SQL 很像,但对图这种数据结构做了表达上的优化。
2-4. 对图数据库的初步推断
从其查询的形式上来看,要实现筛查 d.name = “IT Department”的人名,那么必须能建索引。
从其存储形式,一个实体要包含所有的各种各样的关系上来看,其必须支持动态的数据结构
因此图数据库看起来就是拥有以下特性的存储引擎:
- 对图查询进行了表达形式优化的类 SQL 查询语言
- 动态字段存储
- KV 形式的一级索引(也有可能是 BTREE 形式,但 KV 形式更适合)
- BTREE 形式的二级索引
在数据组织形式和查询读取技术中其应并无更多的黑科技。
3. 在我眼中的 图数据库 VS 关系数据库
在 NEO4J 的文档里,大力吹嘘图数据库的优势,但完全没有提到其缺点,并且之前就提到了,其有很多独特的应用场景,如一开始就提到的反洗钱、反欺诈、推荐等等场景,那他应该是一个颠覆性的产品,可以完全替代 RDBS,为什么现实中 RDBS 是主流呢?
实际上,这还是一个老生常谈的原因,不同的数据库适用于不同的场景。
在我看来,实际图数据库和关系数据库的本质区别是其数据模型的设计理念(如果说数据库范式就是关系数据库设计理念的话)。
传统关系数据库也可以用于存储查询图模式的数据,只要根据范式设计原则反向设计一下就可以了。
对应到上面的员工、部门、从属关系 的例子,在 RDB 中,可以将从属关系变成一个字段值 “111,119,189”就可以存储到关系数据库的员工行记录里了。经过这种范式反的过程后,关系数据库存储的数据模型形式就跟图数据库存储一样了。
既然如此,图数据库为什么诞生了呢?因为:
- 关系数据库的行格式是固定的,要做动态字段就要自行代码处理呀
- 可能数据库里的 BTREE 的聚簇对于图来说也是不必要的,有额外的性能消耗呀
- NODE 的物理大小变化范围很大,跟 RDS 数据库的优化形式可能不匹配会下降性能呀
- SQL 语言表达能力强,但是写起来繁琐,没有针对图数据模型进行优化呀
因此图数据库为了处理这些不方便,应运而生了。
4. 图数据模式 VS 范式设计模式
这里讨论的是两种设计理念的联系与区别。
我们之前就已经多次提到了,范式在关系数据库的现代应用中,会做反范式化的一些处理以提升性能。
然后我们看图数据模式,以下的内容引用自 NEO4J 博客最差实践描述:https://neo4j.com/blog/dark-side-neo4j-worst-practices/:
In terms of data modeling, it’s important to find the middle ground between placing all attributes and properties in a single node and separating each attribute into an individual node. Both of the following extremist approaches will cause significant problems for your graph, as you can see below:
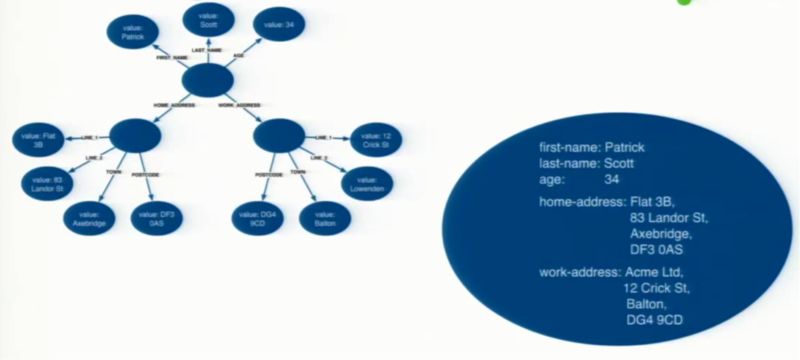
Of course, the right way to model that kind of case is in the middle so everything that is a thing on its own should be a node. So a person, of course, and maybe their address should be a node on its own, but then you should make use of properties which describe the attributes of those entities.
意思大概就是:你不能把一个人的所有 关系 / 属性 都变成关系,或者都变成属性。你要适中选择一个度,例如地址可以成为单独一个实体,用关系与”NODE- 人”进行关联,其他的都是人的属性。
那何谓适合的度呢?
假设存在这么一个设计,人物 NODE 与 地址 NODE 产生关联,地址 NODE 与 省份 NODE、市 NODE、县 NODE 产生关联
如果我需要知道 人物 NODE 所在的省份信息,是不是需要通过地址这个 NODE 跳转一下(JOIN 一下)再查找省份信息呢?这会不会很慢呢?
还是说,我们知道了我们要查省份这个信息,因此,我们就直接把省份这个信息直接关联到人物这个 NODE 里呢? 如果很多间接关系都直接扔到了一个 NODE 里,会不会 NODE 变得无穷大,也变得很慢呢?
按照我们最初对图数据库的理解,实体的关系都会直接存储到实体中,但是通过这些情况的分析,我们会发现,是不会这么做的,这要看那些关系是我们关心的,一些多层间接关系我们不关心的话,就直接通过多个间接关系表达就可以了。
现在有没有一点 对于 图模式数据 和 范式化模式数据 的联系区别有点感觉?
对,图数据模型以及范式化数据模型是两个极端:
- 极端的图数据模型从实体出发整合了一个实体的所有关系
- 极端的范式数据模型从关系出发,整合了所有同类型的关系
而真正高性能的数据模型,取决于业务数据使用形态,在他们之间取得一个适合于业务的平衡。
5. 给出最终结论
最后,图数据库只是一个从图数据模型设计理念出发,有特定适合场景的数据库实现而已,并无神奇的地方。
对于靠近 图数据库模型设计理念的数据模型,其以实体维度组织数据,可以更好地获取一个实体的属性及关系,因此对于识别实体特性的场景更高效,如识别账户是否被卷入欺诈等。
而对于靠近 范式数据库设计理念的数据模型,其以关系维度组织整合同类关系,可以更好地获得一类关系的整体特征,同时由于同一类关系其格式形态固定,因此能获得更好的更新及插入性能。
以上很多是个人对于图数据库的一些思考,仅为抛砖引玉,若大家有不同意见,欢迎斧正!
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






