1. 导语
社交媒体、电子邮件、聊天、产品评论和推荐的文本挖掘和分析已经成为几乎所有行业垂直行业研究数据模式的宝贵资源,它能够帮助企业获得更多信息、更加了解客户、预测和增强客户体验、量身定制营销活动,并协助做决策。
快速了解客户评论的基调
了解客户喜欢或不喜欢的产品或服务
了解可能影响新客户购买决策的因素
为企业提供市场意识
尽早解决问题
了解股市情绪以获得对金融信号预测的见解
确定人们对客户支持的看法
社交媒体监控
品牌/产品/公司人气/声誉/感知监控
不满意的客户检测监控和警报
营销活动监控/分析
客户服务意见监测/分析
品牌情绪态度分析
客户反馈分析
竞争情绪分析
品牌影响者监控
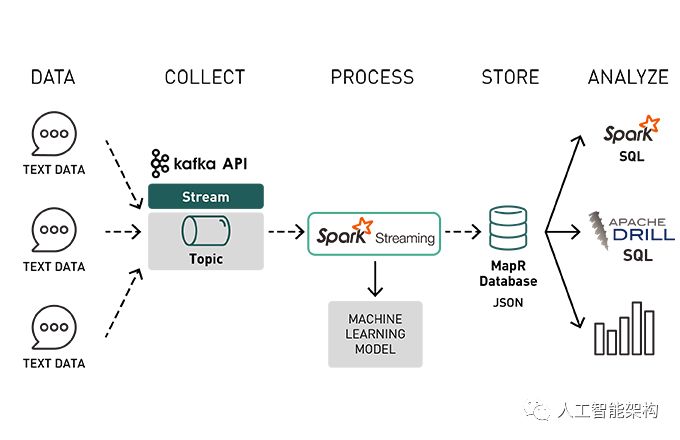
手动分析客户或潜在客户产生的大量文本非常耗时,机器学习更有效,通过流分析,可以实现并提供预测。
本文是系列文章中的第一篇,在这篇文章中我们讨论了将流数据与机器学习和快速存储相结合的数据管道的体系结构。在第一部分,将使用Spark机器学习数据管道探索情绪分析。我们将使用亚马逊产品评论的数据集,并构建机器学习模型,将评论分类为正面或负面。在本文的第二部分中,我们将使用机器学习模型与流数据实时分类文档。
在这篇文章中,我们将讨论以下内容:
分类和情感分析概念概述
从文本文档构建特征向量
培训机器学习模型,使用逻辑回归对正面和负面评论进行分类
评估和保存机器学习模型
2. 分类
分类是一种监督学习算法,它是基于标记数据(如电子邮件主题和消息文本)来识别所属类别(如,电子邮件是否为垃圾邮件)。用于分类的一些常见用例包括信用卡欺诈、垃圾电子邮件的检测和情绪分析。
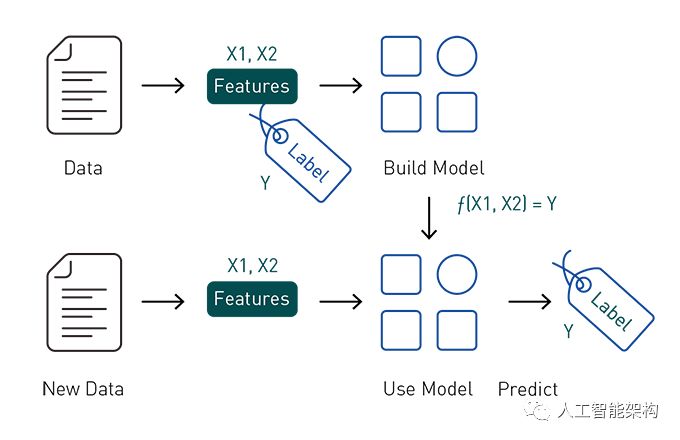
分类使用的是有标签和预定特征的一组数据,并基于该信息学习如何标记新的记录,主要功能是进行预测。要构建分类器模型,需要探索和提取最有助于分类的特征。
让我们通过一个案例来分析正面或负面的文本分类。
想要预测什么?
在此示例中,客户评论评级用于将评论标记为肯定评论。4至5星的评论被认为是积极的评论,1至2星的评论被认为是负面评论。
可以使用哪些属性进行预测?
审核文本单词用作发现正面或负面相似性的功能,以便将客户文本情绪分类为正面或负面。
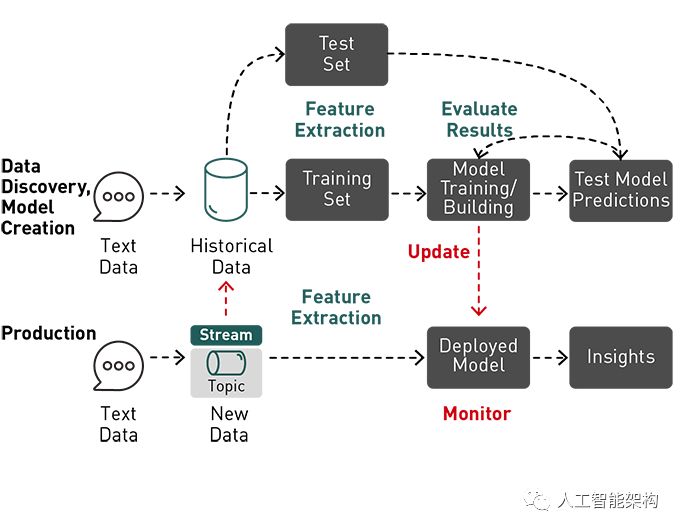
3. 机器学习工作流程
使用机器学习是一个迭代过程,涉及:
数据发现和模型创建
分析历史数据
由于格式,大小或结构,识别传统分析或数据库未使用的新数据源
跨多个数据源收集,关联和分析数据
了解并应用正确类型的机器学习算法以从数据中获取价值
培训,测试和评估机器学习算法的结果以构建模型
在生产中使用模型进行预测
数据发现和使用新数据更新模型
4. 特征提取
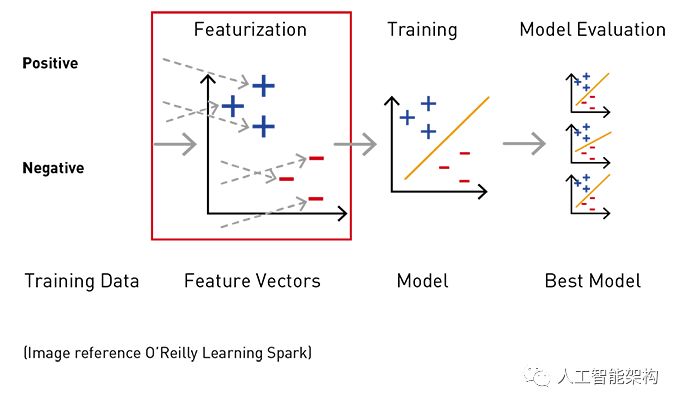
特征是数据中可用于进行预测的有趣属性。特征提取是将原始数据转换为机器学习算法的输入过程。为了在Spark机器学习算法中使用,必须将特征放入特征向量中,特征向量是表示每个特征的值的数字向量。要构建分类器模型,需要提取并测试,从而找到最有助于分类的感兴趣的特征。
4-1. Apache Spark用于文本特征提取
SparkMLlib中的TF-IDF(术语频率-逆文档频率)特征提取器可用于将文本转换为特征向量。与文档集合相比,TF-IDF计算单个文档中最重要的单词。对于文档集合中的每个单词,它计算:
术语频率(TF),是特定文档中单词出现的次数
文档频率(DF),它是文档集合中单词出现的次数
术语频率 – 逆文档频率(TF-IDF),它测量文档中单词的重要性(该单词在该文档中出现很多,但在文档集合中很少见)
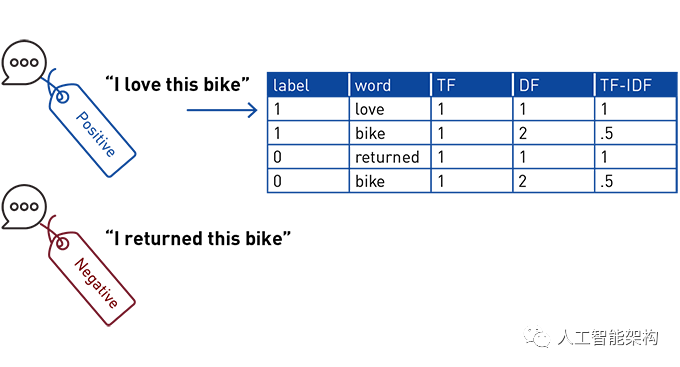
例如,如果有关于自行车配件的评论集合,那么评论中的“returned”一词对于该文档而言比“bike”这个词更重要。在下面的简单示例中,有一个正面文本文档和一个负面文本文档,其中包含“love”、“bike”和“returned”(在过滤后删除无关紧要的单词,如“我”)。显示了TF、DF和TF-IDF计算。单词“bike”的TF为1:2文档(每个文档中的字数),文档频率为2(文档集中的字数),TF-IDF为1/2(TF除以DF)。
5. Logistic回归
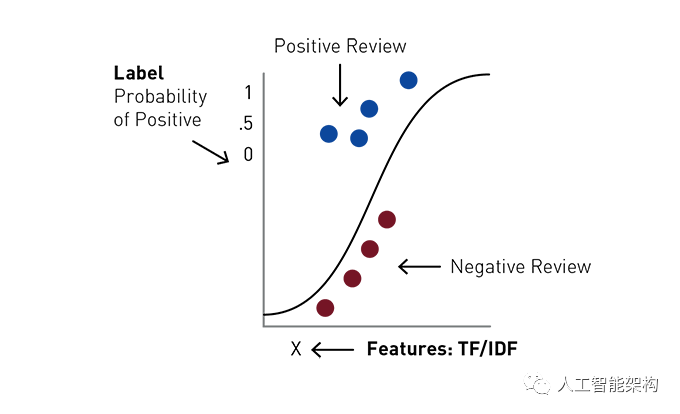
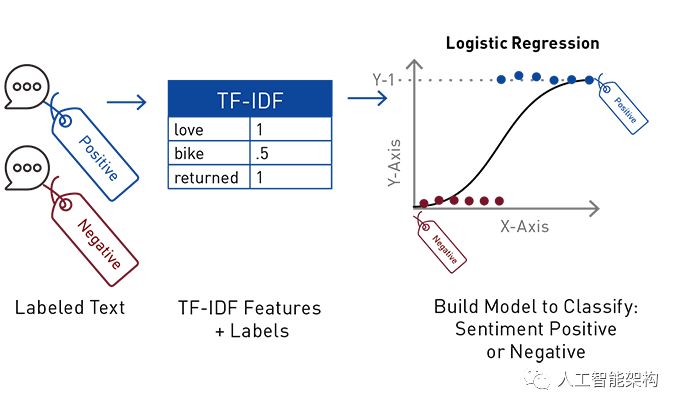
逻辑回归是预测二元响应的常用方法,这是广义线性模型的一个特例,它可以预测结果的概率。逻辑回归通过使用逻辑函数估计概率来测量“Y”标签和X“特征”之间的关系。该模型预测概率,用于预测标签类。
在我们的文本分类案例中,给定TF-IDF值的标签和特征向量,逻辑回归试图预测评论文本为正或负的概率。Logistic回归通过将每个TF-IDF特征乘以权重并将总和通过sigmoid函数找到文本集合中每个单词的最佳拟合权重,该函数将输入x转换为输出y,即得到0到1之间的数字,逻辑回归可以理解为找到最合适的参数:
Logistic回归具有以下优点:
6. 数据探索和特征提取
我们将使用亚马逊体育和户外产品评论数据的数据集,数据集有以下模式,对显示的字段进行情绪分析:
reviewerID – 评论者的ID,例如,A2SUAM1J3GNN3B
数据集具有以下JSON格式:
{
"reviewerID" : "A1PUWI9RTQV19S" ,
"asin" : "B003Y5C132" ,
"reviewerName" : "kris" ,
"helpful" : [ 0 , 1 ] ,
"reviewText" : "A little small in hind sight, but I did order a .30 cal box. Good condition, and keeps my ammo organized." ,
"overall" : 5.0 ,
"summary" : "Nice ammo can" ,
"unixReviewTime" : 1384905600 ,
"reviewTime" : "11 20, 2013"
}
在这种情况下,我们将使用逻辑回归来预测正面或负面的标签,基于以下内容:
标签:
总体而言 – 产品评级4-5 = 1正面
总体而言 – 产品评级1-2 = 0否定
特征:
reviewText +评论摘要→TF-IDF功能
7. 使用Spark ML
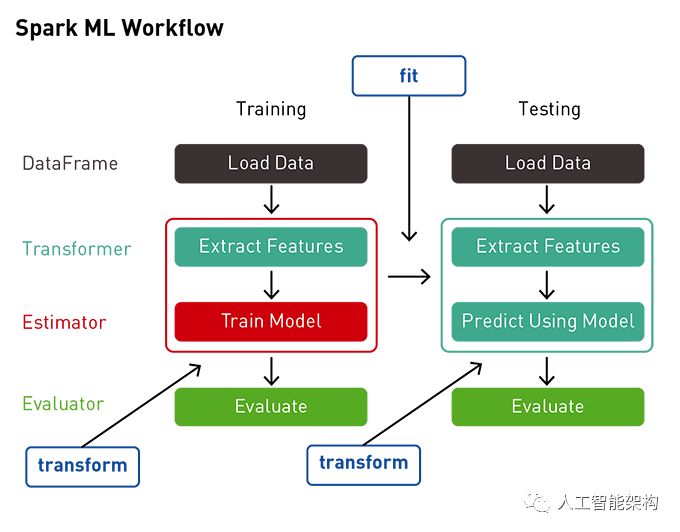
Spark ML提供了一套基于DataFrames的统一的高级API,旨在使机器学习变得简单易用。在DataFrames之上构建ML API可以提供分区数据处理的可扩展性,并且易于使用SQL进行数据操作。
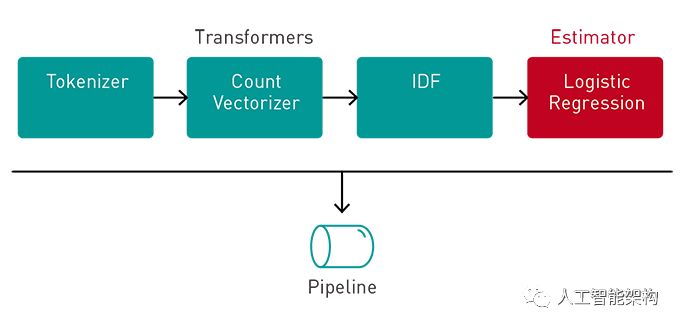
我们将使用ML Pipeline通过变换器传递数据以提取特征和估计器来生成模型。
变压器:变压器是一种将一种变换DataFrame为另一种变换器的算法DataFrame。我们将使用变换器来获得DataFrame具有特征向量列的变量。
估计器:估算器是一种算法,可以适合DataFrame生成变压器。我们将使用估计器来训练模型,该模型可以转换输入数据以获得预测。
管道:管道将多个变换器和估算器链接在一起以指定ML工作流程。
8. 将文本中的数据加载到DataFrame
第一步将数据加载到DataFrame,我们指定数据源格式和加载到的路径,接着使用withColum方法添加一个将审阅摘要与审阅文本相结合的示例,然后删除不需要的列。
import org . apache . spark . _
import org . apache . spark . ml . _
import org . apache . spark . sql . _
var file ="/user/mapr/data/revsporttrain.json"
val df0 = spark . read . format ( "json" )
. option ( "inferSchema" , "true" )
. load ( file )
val df = df0 . withColumn ( "reviewTS" ,
concat ( $ "summary" , lit ( " " ) , $ "reviewText" ) )
. drop ( "helpful" )
. drop ( "reviewerID" )
. drop ( "reviewerName" )
. drop ( "reviewTime" )
该DataFrame printSchema显示模式:
df . printSchema
root
| -- asin : string ( nullable = true )
| -- overall : double ( nullable = true )
| -- reviewText : string ( nullable = true )
| -- summary : string ( nullable = true )
| -- unixReviewTime : long ( nullable = true )
| -- reviewTS : string ( nullable = true )
该DataFrame show方法显示前20行或指定的行数:
df . show ( 5 ) < img class ="img_loading" src ="data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==" crossorigin ="anonymous" data -ratio ="0.16842105263157894" data -src ="https://mmbiz.qpic.cn/mmbiz_png/mkjCniaBPibTIlfg0ELYypDbibEXu5umu0eyS3aGsGV5FUEicN7YnpMv6yMysPic72QplCQHN71LJOTNImHGvvp4YQg/640?wx_fmt=png" data -type ="png" data -w ="570" />
9. 摘要统计
Spark DataFrames包含一些用于统计处理的内置函数。该describe()函数对所有数字列执行摘要统计计算,并将它们作为a返回DataFrame。下面,我们分析产品评级:
df . describe ( "overall" ) . show
result :
+-------+------------------+
| summary | overall |
+-------+------------------+
| count | 200000 |
| mean | 4.395105 |
| stddev | 0.9894654790262587 |
| min | 1.0 |
| max | 5.0 |
+-------+------------------+
在下面的代码中,我们过滤去除中性评价(=3),然后使用Spark Bucketizer将标签0/1列添加到数据集中为Positive(总评级>=4)而不是正数(总评级<4)评论。然后,显示结果总计数。通过标签列对数据进行分组并计算每个分组中的实例数量,显示正样本的数量大约是负样本的13倍。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
val df1 = df . filter ( "overall !=3" )
val bucketizer = new Bucketizer ( )
. setInputCol ( "overall" )
. setOutputCol ( "label" )
. setSplits ( Array ( Double . NegativeInfinity , 4.0 ,
Double . PositiveInfinity ) )
val df2 = bucketizer . transform ( df1 )
df2 . groupBy ( "overall" , "label" ) . count . show
result :
+-------+-----+------+
| overall | label | count |
+-------+-----+------+
| 2.0 | 0.0 | 6916 |
| 5.0 | 1.0 | 127515 |
| 1.0 | 0.0 | 6198 |
| 4.0 | 1.0 | 43303 |
+-------+-----+------+
10. 分层抽样
为了确保模型对负样本敏感,我们可以使用分层抽样将两种样本类型放在同一个基础上。sampleBy()当提供要返回的每个样本类型的分数时,DataFrames函数执行此操作。在这里,保留所有负实例,但将负实例下采样到10%,然后显示结果。
val fractions = Map ( 1.0 -> . 1 , 0.0 -> 1.0 )
val df3 = df2 . stat . sampleBy ( "label" , fractions , 36L )
df3 . groupBy ( "label" ) . count . show
result :
+-----+-----+
| label | count |
+-----+-----+
| 0.0 | 13114 |
| 1.0 | 17086 |
+-----+-----+
下面,数据被分成训练集和测试集:80%的数据用于训练模型,20%用于测试。
// split into training and test dataset
val splitSeed = 5043
val Array ( trainingData , testData ) = df3 . randomSplit ( Array ( 0.8 , 0.2 ) , splitSeed )
11. 特征提取与流水线
ML需要将标签和特征向量作为列添加到输入中DataFrame,我们设置一个管道来通过变换器传递数据,以便提取特征和标签。
在RegexTokenizer采用输入文本列,并返回一个DataFrame通过使用所提供的正则表达式模式与文本分割的一个附加列的矩阵。将StopWordsRemover过滤出的话,应被排除在外,因为词频繁出现,不进行尽可能多的意义,如“I”、“is”。
在下面的代码中,RegexTokenizer将使用review和summary文本将列拆分为一个包含单词数组的列,然后由以下内容过滤StopWordsRemover:
val tokenizer = new RegexTokenizer ( )
. setInputCol ( "reviewTS" )
. setOutputCol ( "reviewTokensUf" )
. setPattern ( "\\s+|[,.()\"]" )
val remover = new StopWordsRemover ( )
. setStopWords ( StopWordsRemover
. loadDefaultStopWords ( "english" ) )
. setInputCol ( "reviewTokensUf" )
. setOutputCol ( "reviewTokens" )
作为输入栏review以及将所述reviewTokens的过滤柱的话,如下所示:
CountVectorizer用于将前一步骤中的单词标记数组转换为单词标记计数的向量。该CountVectorizer正在执行的TF-IDF特征提取的TF部分。
val cv = new CountVectorizer ( )
. setInputCol ( "reviewTokens" )
. setOutputCol ( "cv" )
. setVocabSize ( 200000 )
下面显示了CountVectorizer作为输入列reviewTokens并添加cv矢量化字数列的结果的示例。在cv专栏中:56004是TF词汇的大小;第二个数组是是词语的位置,该词汇按语料库中的术语频率排序;第三组数组是reviewTokens文本中单词(TF)的计数。
在cv列下方,由CountVectorizer(TF-IDF特征提取的TF部分)创建,是IDF的输入。IDF采用从CountVectorizer向下和向下权重特征创建的特征向量,这些特征向量经常出现在文本集合中(TF-IDF特征提取的IDF部分)。输出features列是TF-IDF特征向量,逻辑回归函数将使用该向量。
// list of feature columns
val idf = new IDF ( )
. setInputCol ( "cv" )
. setOutputCol ( "features" )
以下显示了IDF的结果,它作为输入列cv并添加了features矢量化TF-IDF的列。在cv专栏中,56004是单词词汇的大小;第二个数组是词语词汇中词语的位置,该词汇按语料库中术语频率排序;第三个数组是reviewTokens文本中单词的TF-IDF。
管道中的最后一个元素是估算器,一个逻辑回归分类器,它将训练标签和特征向量并返回模型。
// create Logistic Regression estimator
// regularizer parameters avoid overfitting
val lr = new LogisticRegression ( )
. setMaxIter ( 100 )
. setRegParam ( 0.02 )
. setElasticNetParam ( 0.3 )
下面,我们把Tokenizer、CountVectorizer、IDF和Logistic回归分类的管道。管道将多个变换器和估计器链接在一起,以指定用于训练和使用模型的ML工作流程。
val steps = Array ( tokenizer , remover , cv , idf , lr )
val pipeline = new Pipeline ( ) . setStages ( steps )
12. 训练模型
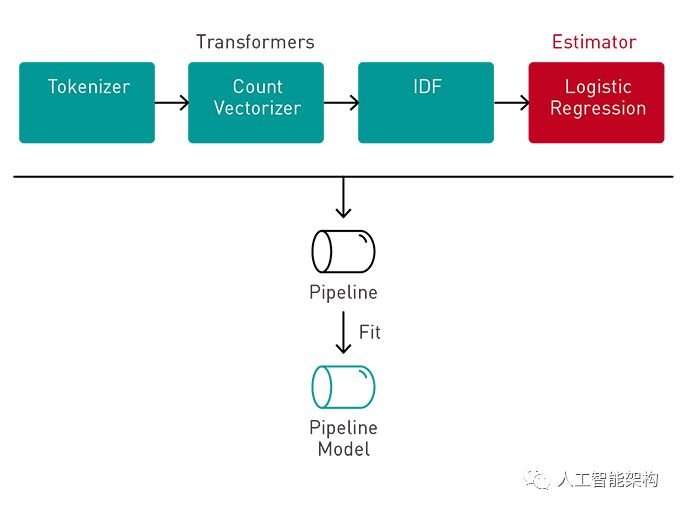
接下来,我们使用弹性网络正则化训练逻辑回归模型。通过在输入特征和与这些特征相关联的标记输出之间建立关联来训练模型。该pipeline.fit方法返回适合的管道模型。
val model = pipeline . fit ( trainingData )
注意:训练模型的另一个选项是使用网络搜索调整参数,并选择最佳模型,使用Spark CrossValidator和ParamGridBuilder进行K交叉验证。
接下来,我们可以从拟合的管道模型中获取CountVectorizer和LogisticRegression模型,以便打印醋文本词汇中单词的系数权重(单词特征重要性)。
// get vocabulary from the CountVectorizer
val vocabulary = model . stages ( 2 )
. asInstanceOf [ CountVectorizerModel ]
. vocabulary
// get the logistic regression model
val lrModel = model . stages . last
. asInstanceOf [ LogisticRegressionModel ]
// Get array of coefficient weights
val weights = lrModel . coefficients . toArray
// create array of word and corresponding weight
val word_weight = vocabulary . zip ( weights )
// create a dataframe with word and weights columns
val cdf = sc . parallelize ( word_weight )
. toDF ( "word" , "weights" )
回想一下,逻辑回归生成公式的系数权重,以预测特征x(在本例中为单词)的出现概率,以最大化结果Y,1或0的概率(在这种情况下,正面或负面文本)情绪。权重可以解释为:
下面我们按降序对权重进行排序,以显示最积极的单词。结果表明
“great”、“perfect”、“easy”、“works”和“excellent”是最重要的积极语言。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// show the most positive weighted words
cdf . orderBy ( desc ( "weights" ) ) . show ( 10 )
result :
+---------+-------------------+
| word | weight |
+---------+-------------------+
| great | 0.6078697902359276 |
| perfect | 0.34404726951273945 |
| excellent | 0.28217372351853814 |
| easy | 0.26293906850341764 |
| love | 0.23518819188672227 |
| works | 0.229342771859023 |
| good | 0.2116386469012886 |
| highly | 0.2044040462730194 |
| nice | 0.20088266981583622 |
| best | 0.18194893152633945 |
+---------+-------------------+
下面,我们按照升序对权重进行排序,以显示最负面的词。结果表明“returned”、
“poor”、“waste”和“useless”是最重要的否定词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// show the most negative sentiment words
cdf . orderBy ( "weights" ) . show ( 10 )
result :
+-------------+--------------------+
| word | weight |
+-------------+--------------------+
| returned | -0.38185206877117467 |
| poor | -0.35366409294425644 |
| waste | -0.3159724826017525 |
| useless | -0.2914292653060789 |
| return | -0.2724012497362986 |
| disappointing | -0.2666580559444479 |
| broke | -0.2656765359468423 |
| disappointed | -0.23852780960293438 |
| returning | -0.22432617475366876 |
| junk | -0.21457169691127467 |
+-------------+--------------------+
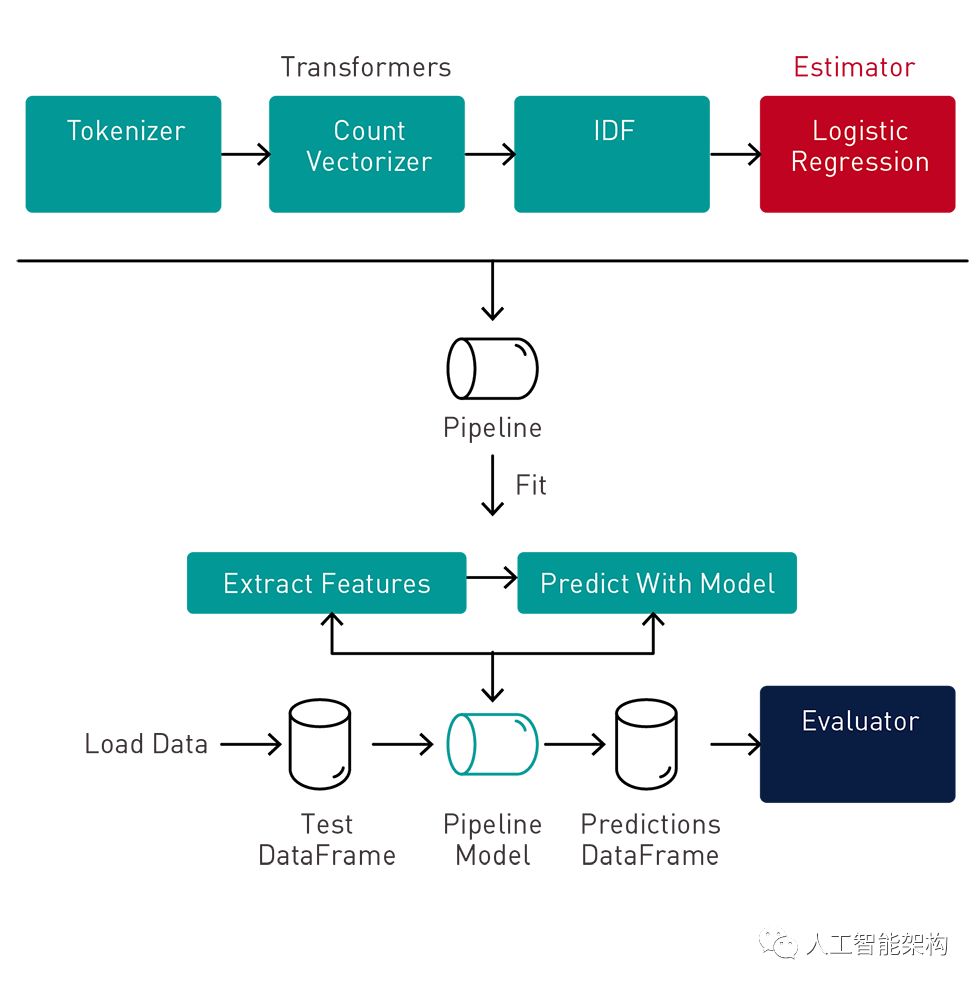
13. 预测和模型评估
可以使用尚未用于任何训练的测试数据集来确定模型的性能。我们DataFrame使用管道模型转换测试,管道模型将根据管道步骤传递测试数据,通过特征提取阶段,使用逻辑回归模型进行估计,然后将标签预测返回到新的列中DataFrame。
val predictions = model . transform ( testData )
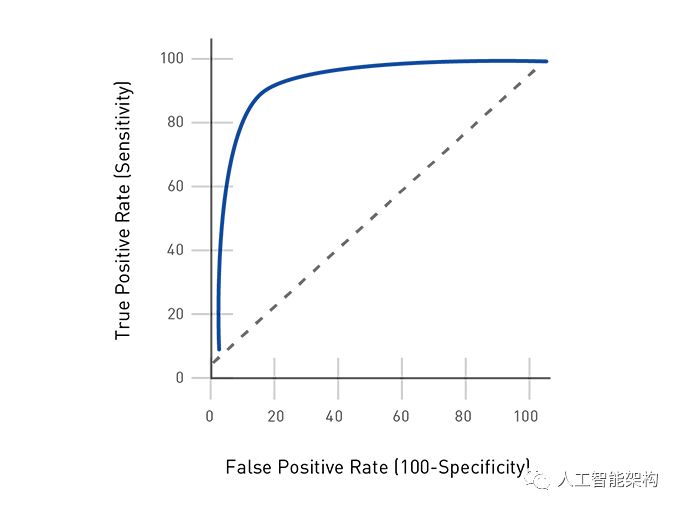
BinaryClassificationEvaluator提供了一个度量标准来衡量拟合模型对测试数据的影响程度。此评估程序的默认度量标准是ROC曲线下的区域,该区域测量了测试从误报中正确分类正面的能力。值越接近1,预测越好。
下面,我们将预测DataFrame(具有rawPrediction列和标签列)传递给
BinaryClassificationEvaluator,返回0.93作为ROC曲线下的区域。
val evaluator = new BinaryClassificationEvaluator ( )
val areaUnderROC = evaluator . evaluate ( predictions )
result : 0.9350783400583272
下面,计算更多的指标。
真正的积极因素是模型正确预测积极情绪的频率。
误报是模型错误地预测积极情绪的频率。
真实的否定表明模型正确预测负面情绪的频率。
假阴性表示模型错误地预测负面情绪的频率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
val lp = predictions . select ( "label" , "prediction" )
val counttotal = predictions . count ( )
val correct = lp . filter ( $ "label" === $ "prediction" ) . count ( )
val wrong = lp . filter ( not ( $ "label" === $ "prediction" ) ) . count ( )
val ratioWrong = wrong . toDouble / counttotal . toDouble
val lp = predictions . select ( "prediction" , "label" )
val counttotal = predictions . count ( ) . toDouble
val correct = lp . filter ( $ "label" === $ "prediction" )
. count ( )
val wrong = lp . filter ( "label != prediction" )
. count ( )
val ratioWrong =wrong /counttotal
val ratioCorrect =correct /counttotal
val truen =( lp . filter ( $ "label" === 0.0 )
. filter ( $ "label" === $ "prediction" )
. count ( ) ) /counttotal
val truep = ( lp . filter ( $ "label" === 1.0 )
. filter ( $ "label" === $ "prediction" )
. count ( ) ) /counttotal
val falsen = ( lp . filter ( $ "label" === 0.0 )
. filter ( not ( $ "label" === $ "prediction" ) )
. count ( ) ) /counttotal
val falsep = ( lp . filter ( $ "label" === 1.0 )
. filter ( not ( $ "label" === $ "prediction" ) )
. count ( ) ) /counttotal
val precision = truep / ( truep + falsep )
val recall = truep / ( truep + falsen )
val fmeasure = 2 precision recall / ( precision + recall )
val accuracy =( truep + truen ) / ( truep + truen + falsep + falsen )
result :
counttotal : 6112.0
correct : 5290.0
wrong : 822.0
ratioWrong : 0.13448952879581152
ratioCorrect : 0.8655104712041884
truen : 0.3417866492146597
truep : 0.5237238219895288
falsen : 0.044829842931937175
falsep : 0.08965968586387435
precision : 0.8538276873833023
recall : 0.9211510791366907
fmeasure : 0.8862126245847176
accuracy : 0.8655104712041886
下面,打印出摘要并查看评论中负面情绪概率最高的:
predictions . filter ( $ "prediction" === 0.0 )
. select ( "summary" , "reviewTokens" , "overall" , "prediction" )
. orderBy ( desc ( "rawPrediction" ) ) . show ( 5 )
result :
+--------------------+--------------------+-------+----------+
| summary | reviewTokens | overall | prediction |
+--------------------+--------------------+-------+----------+
| Worthless Garbage ! | [ worthless , garba . . . | 1.0 | 0.0 |
| Decent but failin . . . | [ decent , failing , . . . | 1.0 | 0.0 |
| over rated and po . . . | [ rated , poorly , m . . . | 2.0 | 0.0 |
| dont waste your m . . . | [ dont , waste , mon . . . | 1.0 | 0.0 |
| Cheap Chinese JUNK ! | [ cheap , chinese , . . . . | 1.0 | 0.0 |
+--------------------+--------------------+-------+----------+
下面,打印出正面情绪概率最高的评论:
predictions . filter ( $ "prediction" === 1.0 )
. select ( "summary" , "reviewTokens" , "overall" , "prediction" )
. orderBy ( "rawPrediction" ) . show ( 5 )
result :
+--------------------+--------------------+-------+----------+
| summary | reviewTokens | overall | prediction |
+--------------------+--------------------+-------+----------+
| great | [ great , excellent . . . | 5.0 | 1.0 |
| Outstanding Purchase | [ outstanding , pur . . . | 5.0 | 1.0 |
| A fantastic stov . . . . | [ fantastic , stov . . . . | 5.0 | 1.0 |
| Small But Delight . . . | [ small , delightfu . . . | 5.0 | 1.0 |
| Kabar made a good . . . | [ kabar , made , goo . . . | 5.0 | 1.0 |
+--------------------+--------------------+-------+----------+
14. 保存模型
现在可以将适合的管道模型保存到分布式文件存储中,以便以后在生产中使用。这样可以在管道中保存特征提取和逻辑回归模型。
var dir = "/user/mapr/sentmodel/"
model . write . overwrite ( ) . save ( dir )
保存管道模型的结果是用于元数据的JSON文件和用于数据的Parquet文件。我们可以使用load命令重新加载模型,原始和重新加载的模型是相同的:
val sameModel = org . apache . spark . ml . PipelineModel . load ( modeldirectory )
15. 结语
有很多很棒的工具来构建分类模型。Apache Spark提供了一个出色的框架,用于构建可以从大量分布式数据,集中提取有价值的业务问题的解决方案。机器学习算法无法完美地回答所有问题。但是,它确实为人类在预测结果时提供了依据。
[source]基于大数据的情绪分析(一)



![[转]基于大数据的情绪分析(二)](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






