1. 导言
情绪分析使用机器学习算法来确定正面或负面文本内容的方式。情绪分析的示例包括:
快速了解客户评论的基调:
了解客户喜欢或不喜欢的产品或服务。
了解可能影响新客户购买决策的因素。
为企业提供市场意识。
尽早解决问题
了解股市情绪,以获得对金融信号预测的见解
社交媒体监控
品牌/产品/公司人气/声誉/感知监控
不满意的客户检测监控和警报
营销活动监控/分析
客户服务意见监测/分析
品牌情绪态度分析
客户反馈分析
竞争情绪分析
品牌影响者监控
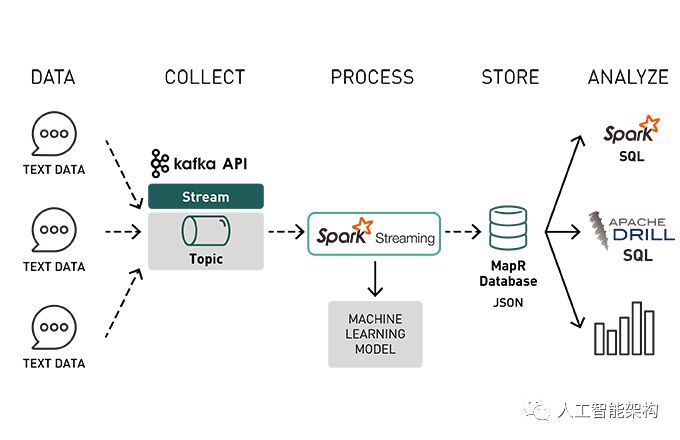
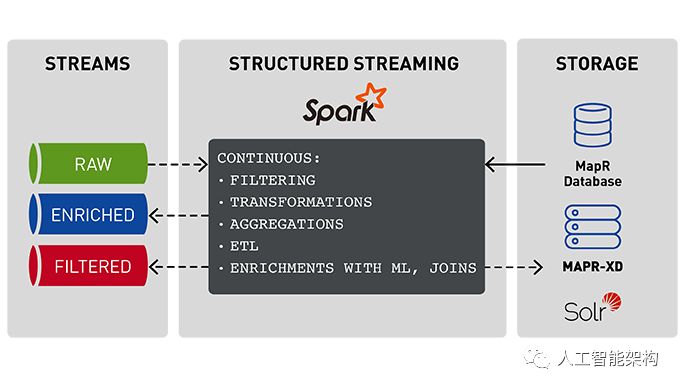
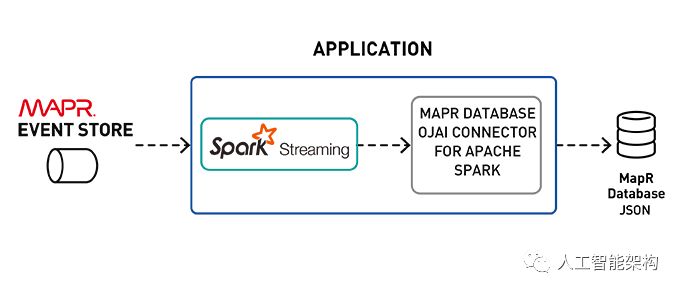
本文将讨论将流数据与机器学习和快速存储相结合的数据管道的体系结构。在上一篇文章中,我们使用Spark Machine学习数据管道探索了情绪分析,并保存了情绪分析机器学习模型。在本文着重讨论使用保存的情绪分析模型和流数据来对产品情绪进行实时分析,将结果存储在MapR数据库中,并使它们可以快速用于Spark和Drill SQL。
在本文中,我们将讨论以下内容:
流媒体概念概述
使用Spark结构化流媒体获取Kafka事件
使用机器学习模型丰富事件
在MapR数据库中存储事件
使用Apache Spark SQL和Apache Drill查询MapR数据库中快速可用的丰富事件
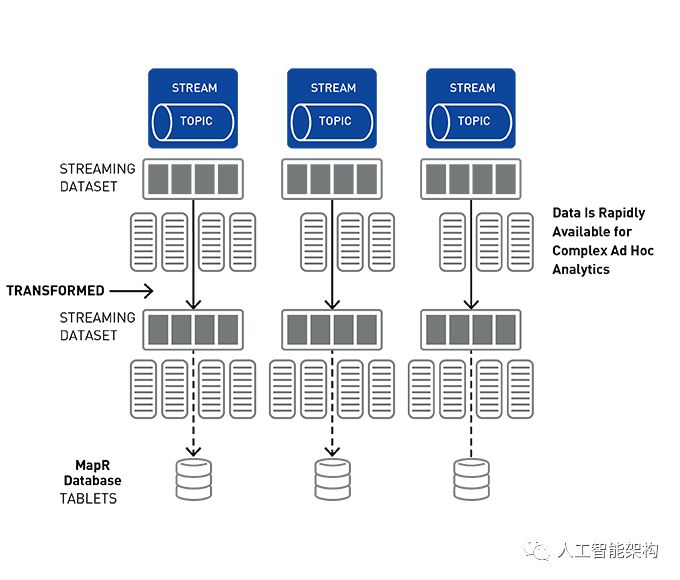
2. 流媒体概念
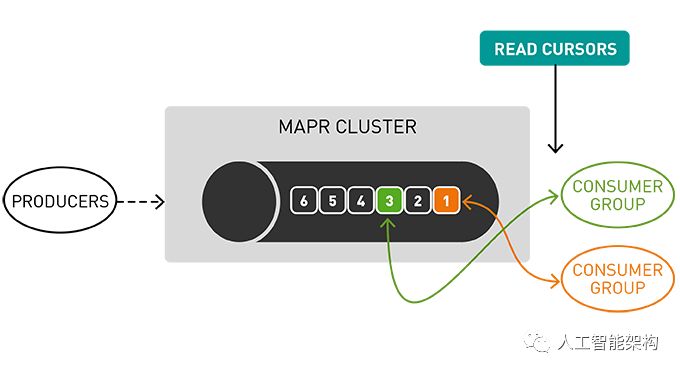
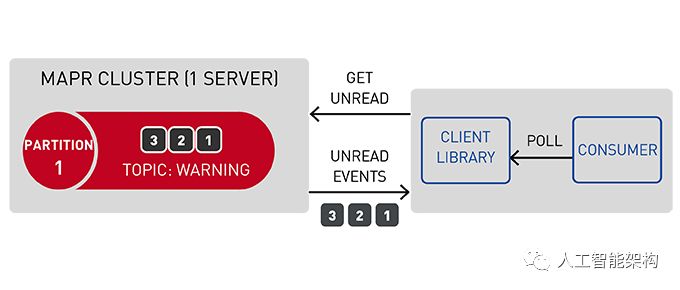
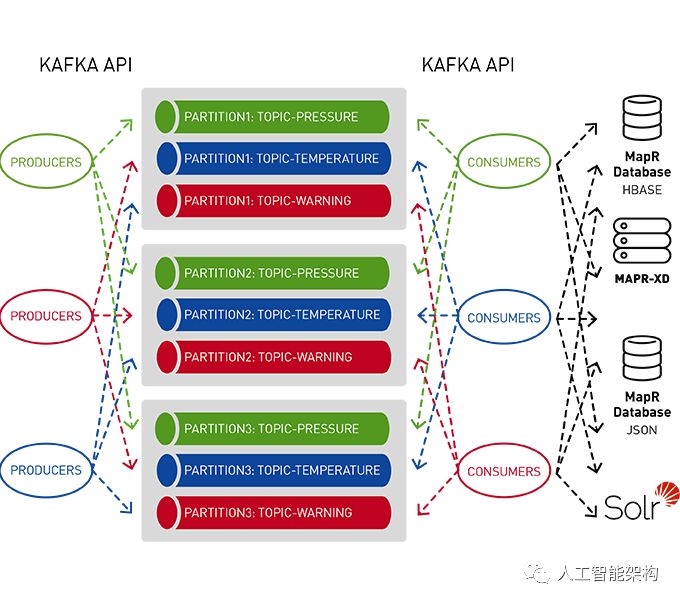
使用适用于Apache Kafka的MapR事件存储发布-订阅事件流
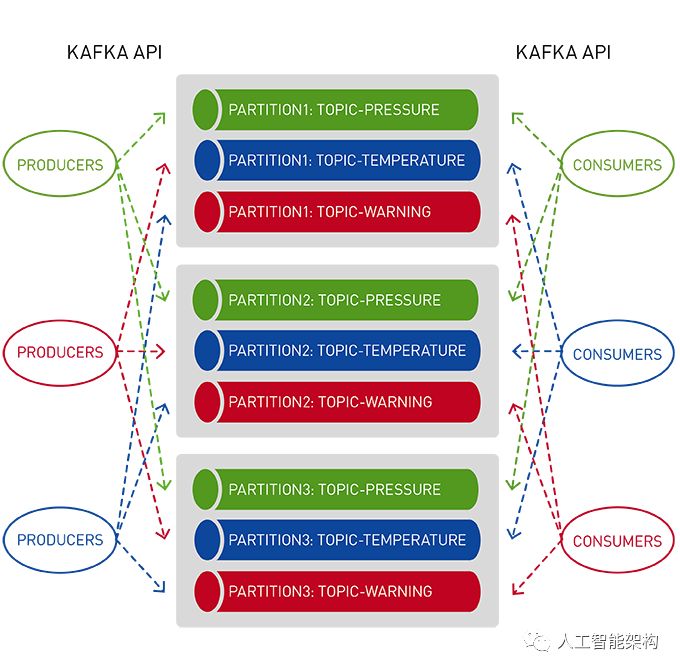
Apache Kafka的MapR事件存储是一个分布式发布-订阅事件流系统,它使生产者和消费者能够通过Apache Kafka API以并行和容错的方式实时交换事件。
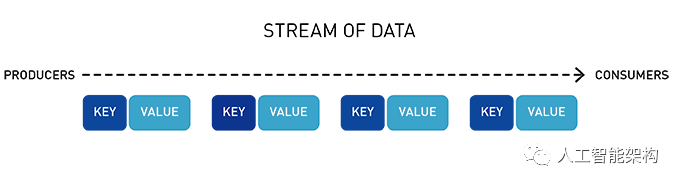
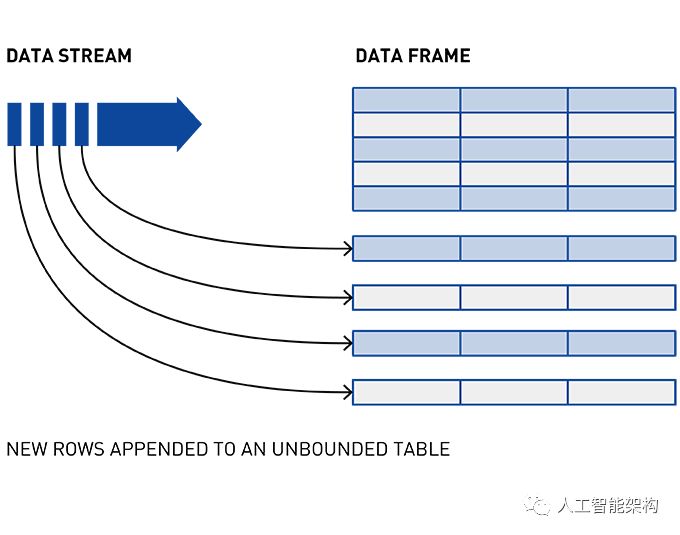
流表示从生产者到消费者的连续事件序列,其中事件被定义为键值对。
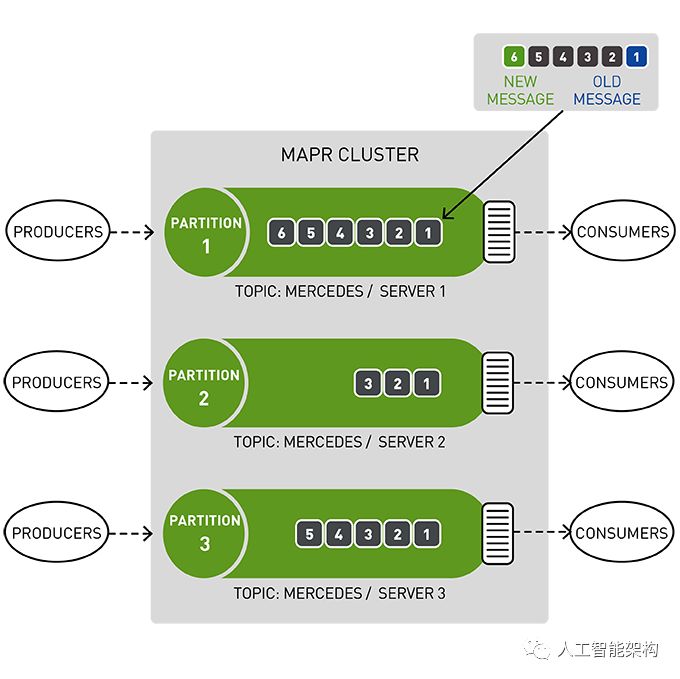
主题是一个逻辑事件流。主题将事件组织成类别,并将生产者与消费者分离。主题按吞吐量和可伸缩性进行分区。MapR事件存储可以扩展到非常高的吞吐量级别,使用非常适中的硬件可以轻松地每秒传输百万条消息。
你可以将分区看作是事件日志:将新事件附加到末尾,并为其分配一个称为偏移的顺序ID号。
与队列一样,事件按照接收顺序传递。
但是,与队列不同,读取时不会删除消息。它们保留在其他消费者可用的分区上。消息一旦发布,就是不可变的,可以永久保留。
在读取消息时不删除消息允许大规模的高性能以及不同消费者针对不同目的(如,具有多语言持久性的多个视图)处理相同消息。
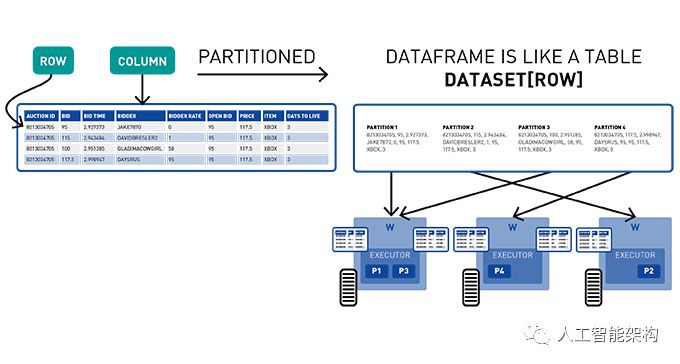
3. Spark数据集、DataFrame、SQL
Spark数据集是分布在集群中多个节点上的类型化对象的分布式集合。可以使用功能转换(map、flatMap、filter等)和(或)Spark SQL来操纵数据集。DataFrame是Row对象的数据集,表示包含行和列的数据表。
4. Spark结构化流媒体
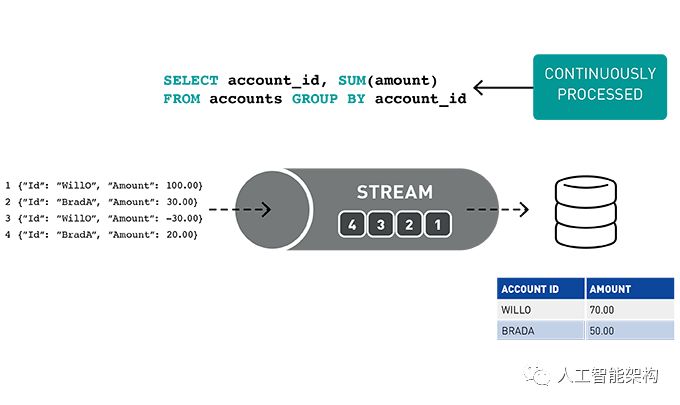
结构化流媒体是一种基于Spark SQL引擎的可扩展且容错的流处理引擎。通过Structured Streaming,你可以将发布到Kafka的数据视为无界DataFrame,并使用与批处理相同的DataFrame、Dataset和SQL API处理此数据。
随着流数据的不断传播,Spark SQL引擎会逐步并持续地处理它并更新最终结果。
事件的流处理对于实时ETL,过滤、转换、创建计数器和聚合,关联值,丰富其他数据源或机器学习,持久化到文件或数据库以及发布到管道的不同主题非常有用。
5. Spark结构化流示例代码
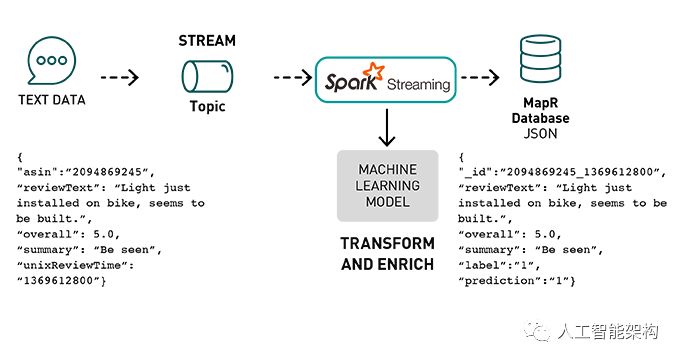
以下是亚马逊产品评论数据的情绪分析用例的数据处理管道,以检测正面和负面评论。
Amazon产品评论使用Kafka API将 JSON格式的事件发布到MapR事件存储主题。
Spark Streaming应用程序订阅了该主题:
获取产品评论事件流
使用部署的机器学习模型,通过正面或负面的情绪预测来丰富评论事件
以JSON格式将转换和丰富的数据存储在MapR数据库中。
6. 用例数据示例
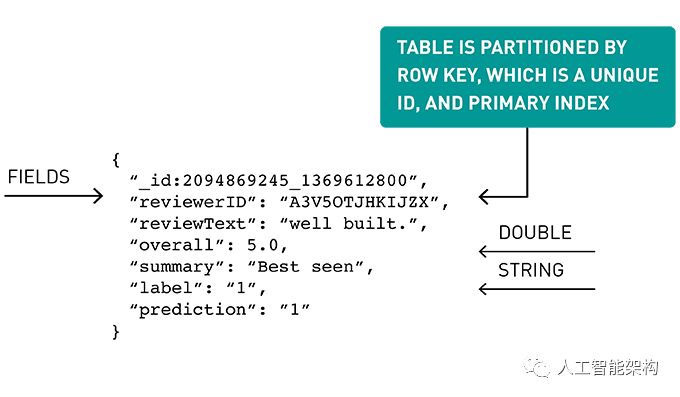
示例数据集是来自之前文章的亚马逊产品评论数据(插入链接)。传入的数据采用JSON格式,示例如下:
{ "reviewerID" : "A3V52OTJHKIJZX" , "asin" : "2094869245" , "reviewText" : "Light just installed on bike, seems to be well built." , "overall" : 5.0 , "summary" : "Be seen" , "unixReviewTime" : 1369612800 }
我们使用情绪预测来丰富这些数据,删除一些列,然后将其转换为以下JSON对象:
{ "reviewerID" : "A3V52OTJHKIJZX" , "_id" : "2094869245_1369612800" , "reviewText" : "Light just installed on bike, seems to be well built." , "overall" : 5.0 , "summary" : "Be seen" , "label" : "1" , "prediction" : "1" }
7. 加载Spark Pipeline模型
Spark PipelineModel类用于加载管道模型,该模型安装在历史产品评审数据上,然后保存到MapR-XD文件系统。
// Directory to read the saved ML model from
var modeldirectory ="/user/mapr/sentmodel/"
// load the saved model from the distributed file system
val model = PipelineModel . load ( modeldirectory )
8. 从Kafka主题中读取数据
为了从Kafka读取,我们必须首先指定流格式,主题和偏移选项。
var topic : String = "/user/mapr/stream:reviews"
val df1 = spark . readStream . format ( "kafka" )
. option ( "kafka.bootstrap.servers" , "maprdemo:9092" )
. option ( "subscribe" , topic )
. option ( "group.id" , "testgroup" )
. option ( "startingOffsets" , "earliest" )
. option ( "failOnDataLoss" , false )
. option ( "maxOffsetsPerTrigger" , 1000 )
. load ( )
这将返回具有以下架构的DataFrame:
df1 . printSchema ( )
result :
root
| -- key : binary ( nullable = true )
| -- value : binary ( nullable = true )
| -- topic : string ( nullable = true )
| -- partition : integer ( nullable = true )
| -- offset : long ( nullable = true )
| -- timestamp : timestamp ( nullable = true )
| -- timestampType : integer ( nullable = true )
9. 将消息值解析为DataFrame
下一步是使用产品评审模式将二进制值列解析并转换为DataFrame。我们将使用Spark from_json从上面看到的Kafka DataFrame值字段中提取JSON数据。Spark SQL from_json( )函数使用指定的输入模式将输入JSON字符串转换为Spark结构。
首先,我们使用Spark Structype来定义与传入的JSON消息值对应的模式,
val schema = StructType ( Array (
StructField ( "asin" , StringType , true ) ,
StructField ( "helpful" , ArrayType ( StringType ) , true ) ,
StructField ( "overall" , DoubleType , true ) ,
StructField ( "reviewText" , StringType , true ) ,
StructField ( "reviewTime" , StringType , true ) ,
StructField ( "reviewerID" , StringType , true ) ,
StructField ( "reviewerName" , StringType , true ) ,
StructField ( "summary" , StringType , true ) ,
StructField ( "unixReviewTime" , LongType , true )
) )
在下面的代码中,select表达式中使用from_json() Spark SQL函数,该表达式具有df1列值的字符串,其返回指定模式的DataFrame。
import spark . implicits . _
val df2 = df1 . select ( $ "value" cast "string" as "json" )
. select ( from_json ( $ "json" , schema ) as "data" )
. select ( "data.*" )
返回具有以下架构的DataFrame:
df2 . printSchema ( )
result :
root
| -- asin : string ( nullable = true )
| -- helpful : array ( nullable = true )
| | -- element : string ( containsNull = true )
| -- overall : double ( nullable = true )
| -- reviewText : string ( nullable = true )
| -- reviewTime : string ( nullable = true )
| -- reviewerID : string ( nullable = true )
| -- reviewerName : string ( nullable = true )
| -- summary : string ( nullable = true )
| -- unixReviewTime : long ( nullable = true )
在下面的代码中:
使用withColumn方法添加一个将审阅摘要与审阅文本相结合的列。
过滤去除中性评级(= 3)
Spark Bucketizer用于将标签0/1列添加到数据集中以获得Positive(总体评级> = 4)而不是正数(总评级<4)评论。(注意标签用于测试预测)
// combine summary reviewText into one column
val df3 = df2 . withColumn ( "reviewTS" ,
concat ( $ "summary" , lit ( " " ) , $ "reviewText" ) )
// remove neutral ratings
val df4 = df3 . filter ( "overall !=3" )
// add label column
val bucketizer = new Bucketizer ( )
. setInputCol ( "overall" )
. setOutputCol ( "label" )
. setSplits ( Array ( Double . NegativeInfinity , 3.0 , Double . PositiveInfinity ) )
val df5 = bucketizer . transform ( df4 )
10. 用情感预测丰富评论的数据框架
接下来,使用模型管道转换DataFrame,模型管道将根据管道转换要素、预测,然后在新DataFrame的列中返回预测。
// transform the DataFrame with the model pipeline
val predictions = model . transform ( df5 )
返回具有以下架构的DataFrame:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
predictions . printSchema ( )
result :
root
| -- asin : string ( nullable = true )
| -- helpful : array ( nullable = true )
| | -- element : string ( containsNull = true )
| -- overall : double ( nullable = true )
| -- reviewText : string ( nullable = true )
| -- reviewTime : string ( nullable = true )
| -- reviewerID : string ( nullable = true )
| -- reviewerName : string ( nullable = true )
| -- summary : string ( nullable = true )
| -- unixReviewTime : long ( nullable = true )
| -- reviewTS : string ( nullable = true )
| -- label : double ( nullable = true )
| -- reviewTokensUf : array ( nullable = true )
| | -- element : string ( containsNull = true )
| -- reviewTokens : array ( nullable = true )
| | -- element : string ( containsNull = true )
| -- cv : vector ( nullable = true )
| -- features : vector ( nullable = true )
| -- rawPrediction : vector ( nullable = true )
| -- probability : vector ( nullable = true )
| -- prediction : double ( nullable = false )
11. 为MapR数据库添加唯一ID
在下面的代码中:
删除我们不想存储的列
创建一个由产品ID和审核时间戳组成的唯一ID“_id”,作为用于存储在MapR数据库中的行键。
// drop the columns that we do not want to store
val df6 = predictions . drop ( "cv" , "probability" , "features" , "reviewTokens" , "helpful" , "reviewTokensUf" , "rawPrediction" )
// create column with unique id for MapR Database
val df7 = df6 . withColumn ( "_id" , concat ( $ "asin" , lit ( "_" ) , $ "unixReviewTime" ) )
返回具有以下架构的DataFrame:
df7 . printSchema ( )
Result :
root
| -- asin : string ( nullable = true )
| -- overall : double ( nullable = true )
| -- reviewText : string ( nullable = true )
| -- reviewTime : string ( nullable = true )
| -- reviewerID : string ( nullable = true )
| -- reviewerName : string ( nullable = true )
| -- summary : string ( nullable = true )
| -- unixReviewTime : long ( nullable = true )
| -- label : double ( nullable = true )
| -- reviewTokens : array ( nullable = true )
| | -- element : string ( containsNull = true )
| -- prediction : double ( nullable = false )
| -- _id : string ( nullable = true )
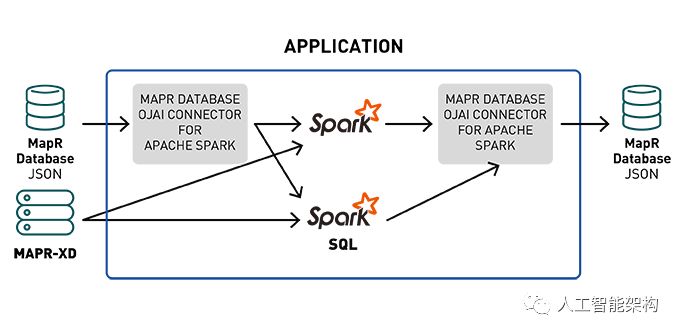
12. Spark Streaming写入MapR数据库
Apache Spark的MapR数据库连接器可以将MapR数据库用作
Spark Structure Streaming或Spark Streaming的接收器。
当处理大量流数据时,其中一个挑战是:想在哪里存储它?对于此应用程序,选择MapR数据库(一种高性能NoSQL数据库),因为它具有JSON的可扩展性和灵活易用性。
13. JSON模式灵活性
MapR数据库支持JSON文档作为本机数据存储。MapR数据库使用JSON文档轻松存储,查询和构建应用程序。Spark连接器可以轻松地在JSON数据和MapR数据库之间构建实时或批处理管道,并在管道中利用Spark。
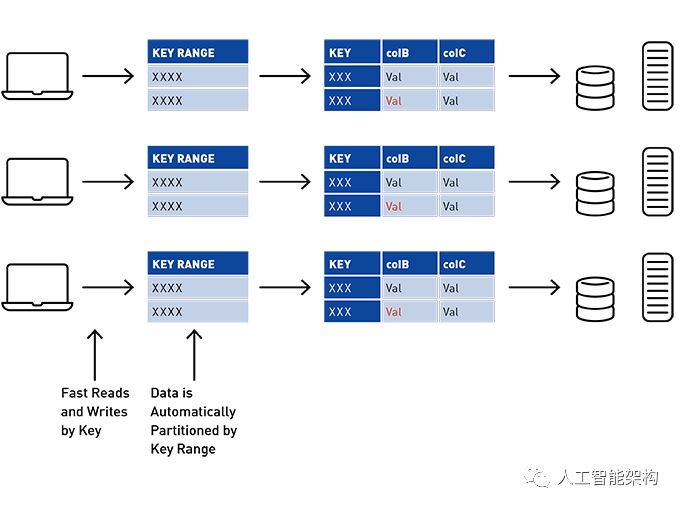
使用MapR数据库,表按键范围自动按群集分区为平板电脑,提供按行键可扩展和快速读写。在此示例中,行健_id由群集ID和反向时间戳组成,因此表将自动分区,并按最新的第一个群集ID进行排序。
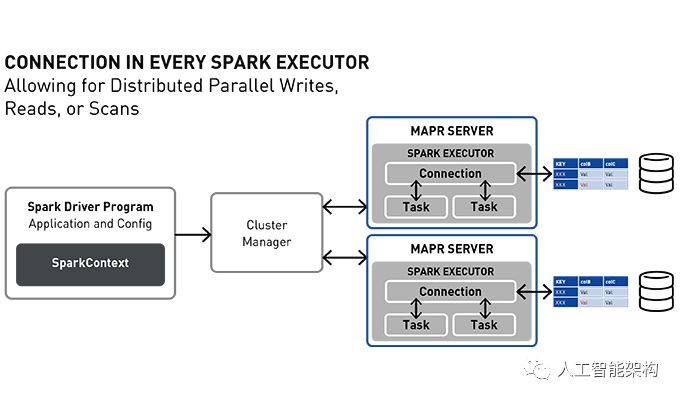
Spark MapR数据库连接器体系结构在每个Spark Executor中都有一个连接对象,允许使用MapR数据库平板电脑(分区)进行分布并行写入、读取和扫描。
14. 写入MapR数据库接收器
要将Spark Stream写入MapR数据库,请使用tablePath,idFieldPath,createTable,bulkMode和sampleSize参数指定格式。以下示例将df7 DataFrame写出到MapR数据库并启动流。
import com . mapr . db . spark . impl . _
import com . mapr . db . spark . streaming . _
import com . mapr . db . spark . sql . _
import com . mapr . db . spark . streaming . MapRDBSourceConfig
var tableName : String = "/user/mapr/reviewtable"
val writedb = df7 . writeStream
. format ( MapRDBSourceConfig . Format )
. option ( MapRDBSourceConfig . TablePathOption , tableName )
. option ( MapRDBSourceConfig . IdFieldPathOption , "_id" )
. option ( MapRDBSourceConfig . CreateTableOption , false )
. option ( "checkpointLocation" , "/tmp/reviewdb" )
. option ( MapRDBSourceConfig . BulkModeOption , true )
. option ( MapRDBSourceConfig . SampleSizeOption , 1000 )
writedb . start ( )
15. 使用Spark SQL查询MapR数据库JSON
Spark MapR数据库连接器使用户能够使用Spark数据集在MapR数据库之上执行复杂的SQL查询和更新,同时,应用投影和过滤器, 自定义分区和数据位置等关键技术。
16. 将数据从MapR数据库加载到Spark数据集
要将MapR数据库JSON表中的数据加载到Apache Spark数据集中,我们在SparkSession对象上调用loadFromMapRDB方法,提供tableName、schema和case类。将返回带有产品评论模式的数据集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
val schema = StructType ( Array (
StructField ( "_id" , StringType , true ) ,
StructField ( "asin" , StringType , true ) ,
StructField ( "overall" , DoubleType , true ) ,
StructField ( "reviewText" , StringType , true ) ,
StructField ( "reviewTime" , StringType , true ) ,
StructField ( "reviewerID" , StringType , true ) ,
StructField ( "reviewerName" , StringType , true ) ,
StructField ( "summary" , StringType , true ) ,
StructField ( "label" , StringType , true ) ,
StructField ( "prediction" , StringType , true ) ,
StructField ( "unixReviewTime" , LongType , true )
) )
var tableName : String = "/user/mapr/reviewtable"
val df = spark
. loadFromMapRDB ( tableName , schema )
df . createOrReplaceTempView ( "reviews" )
17. 使用Spark SQL探索和查询产品评论数据
现在,我们可以直接查询连续流入MapR数据库的数据,以使用Spark DataFrame特定于域的语言或使用Spark SQL来提问。
下面,我们使用DataFrame select和show方法以表格的格式显示前5行评论摘要、总体评级、标签和预测
df . select ( "summary" , "overall" , "label" , "prediction" ) . show ( 5 )
result :
+--------------------+-------+-----+----------+
| summary | overall | label | prediction |
+--------------------+-------+-----+----------+
| Excellent Ammo Can | 5.0 | 1.0 | 1.0 |
| Glad I bought it | 5.0 | 1.0 | 1.0 |
| WILL BUY FROM AGA . . . | 5.0 | 1.0 | 1.0 |
| looked brand new . . . | 5.0 | 1.0 | 1.0 |
| I LOVE THIS THING | 5.0 | 1.0 | 1.0 |
+--------------------+-------+-----+----------+
什么是评级最高的产品?
df . filter ( $ "overall" === 5.0 )
. groupBy ( "overall" , "asin" )
. count
. orderBy ( desc ( "count" ) ) . show ( 2 )
result :
+-------+----------+-----+
| overall | asin | count |
+-------+----------+-----+
| 5.0 | B004TNWD40 | 242 |
| 5.0 | B004U8CP88 | 201 |
+-------+----------+-----+
在SQL中评分最高的产品是什么?
% sql
SELECT asin , overall , count ( overall )
FROM reviews where overall =5.0
GROUP BY asin , overall
order by count ( overall ) desc limit 2
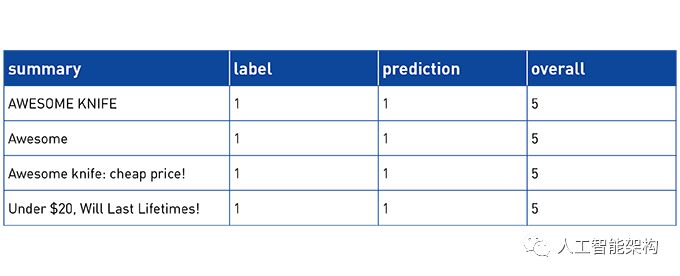
显示评分最高的产品评论文字:
df . select ( "summary" , "reviewText" , "overall" , "label" , "prediction" ) . filter ( "asin='B004TNWD40'" ) . show ( 5 )
result :
+--------------------+--------------------+-------+-----+----------+
| summary | reviewText | overall | label | prediction |
+--------------------+--------------------+-------+-----+----------+
| Awesome | This is the perfe . . . | 5.0 | 1.0 | 1.0 |
| for the price you . . . | Great first knife . . . | 5.0 | 1.0 | 1.0 |
| Great Mora qualit . . . | I have extensive . . . | 4.0 | 1.0 | 1.0 |
| Amazing knife | All I can say is . . . | 5.0 | 1.0 | 1.0 |
| Swedish Mil . Mora . . . | Overall a nice kn . . . | 4.0 | 1.0 | 1.0 |
+--------------------+--------------------+-------+-----+----------+
或者在SQL中:
% sql
select summary , label , prediction , overall
from reviews
where asin ='B004TNWD40'
order by overall desc
什么是评级最低的产品?
df . filter ( $ "overall" === 1.0 )
. groupBy ( "overall" , "asin" )
. count . orderBy ( desc ( "count" ) ) . show ( 2 )
result :
+-------+----------+-----+
| overall | asin | count |
+-------+----------+-----+
| 1.0 | B00A17I99Q | 18 |
| 1.0 | B00BGO0Q9O | 17 |
+-------+----------+-----+
显示评级最低的产品评论文本:
df . select ( "summary" , "reviewText" , "overall" , "label" , "prediction" )
. filter ( "asin='B00A17I99Q'" )
. orderBy ( "overall" ) . show ( 8 )
result :
+--------------------+--------------------+-------+-----+----------+
| summary | reviewText | overall | label | prediction |
+--------------------+--------------------+-------+-----+----------+
| DO NOT BUY ! | Do your research . . . | 1.0 | 0.0 | 0.0 |
| Returned it | I could not get t . . . | 1.0 | 0.0 | 0.0 |
| didn 't do it for me|didn' t like it . . . . | 1.0 | 0.0 | 0.0 |
| Fragile , just lik . . . | Update My second . . . . | 1.0 | 0.0 | 0.0 |
下面,我们计算连续存储在MapR数据库中的流数据的一些预测评估指标。真/假的数量:
真正的积极因素是模型正确的积极情绪
误报是模型错误积极情绪的频率
真实的否定表明模型正常负面情绪的频率
假阴性表示模型错误负面情绪的频率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
val lp = predictions . select ( "label" , "prediction" )
val counttotal = predictions . count ( )
val correct = lp . filter ( $ "label" === $ "prediction" ) . count ( )
val wrong = lp . filter ( not ( $ "label" === $ "prediction" ) ) . count ( )
val ratioWrong = wrong . toDouble / counttotal . toDouble
val lp = predictions . select ( "prediction" , "label" )
val counttotal = predictions . count ( ) . toDouble
val correct = lp . filter ( $ "label" === $ "prediction" )
. count ( )
val wrong = lp . filter ( "label != prediction" )
. count ( )
val ratioWrong =wrong /counttotal
val ratioCorrect =correct /counttotal
val truen =( lp . filter ( $ "label" === 0.0 )
. filter ( $ "label" === $ "prediction" )
. count ( ) ) /counttotal
val truep = ( lp . filter ( $ "label" === 1.0 )
. filter ( $ "label" === $ "prediction" )
. count ( ) ) /counttotal
val falsen = ( lp . filter ( $ "label" === 0.0 )
. filter ( not ( $ "label" === $ "prediction" ) )
. count ( ) ) /counttotal
val falsep = ( lp . filter ( $ "label" === 1.0 )
. filter ( not ( $ "label" === $ "prediction" ) )
. count ( ) ) /counttotal
val precision = truep / ( truep + falsep )
val recall = truep / ( truep + falsen )
val fmeasure = 2 * precision * recall / ( precision + recall )
val accuracy =( truep + truen ) / ( truep + truen + falsep + falsen )
results :
counttotal : Double = 84160.0
correct : Double = 76925.0
wrong : Double = 7235.0
truep : Double = 0.8582461977186312
truen : Double = 0.05578659695817491
falsep : Double = 0.014543726235741445
falsen : Double = 0.07142347908745247
ratioWrong : Double = 0.08596720532319392
ratioCorrect : Double = 0.9140327946768061
18. 投影和过滤器下推到MapR数据库
可以通过调用以下显示的explain方法来查看DataFrame查询的物理计划。在红色中,我们看到投影和过滤器下推,这意味着整个列和总结列的扫描以及整个列上的过滤器被下推到MapR数据库中,这意味着在将数据返回给Spark之前,扫描和过滤将在MapR数据库中进行。
通过胜率表扫描中不必要的字段,投影下推可最大限度的减少MapR数据库和Spark引擎之间的数据传输。当表包含许多列时,他尤为有用。过滤器下推通过减少过滤数据是MapR数据库和Spark引擎之间传递的数据量来提高性能。
// notice projection of selected fields [summary]
// notice PushedFilters: overall
df . filter ( "overall > 3" ) . select ( "summary" ) . explain
result :
== Physical Plan ==
*( 1 ) Project [ summary #7]
+- *( 1 ) Filter ( isnotnull ( overall #2) && (overall#2 > 3.0))
+- *( 1 ) Scan MapRDBRelation MapRDBTableScanRDD [ summary #7,overall#2]
PushedFilters : [ IsNotNull ( overall ) , GreaterThan ( overall , 3.0 ) ] ,
ReadSchema : struct < summary : string , overall : double >
使用Apache Drill查询数据
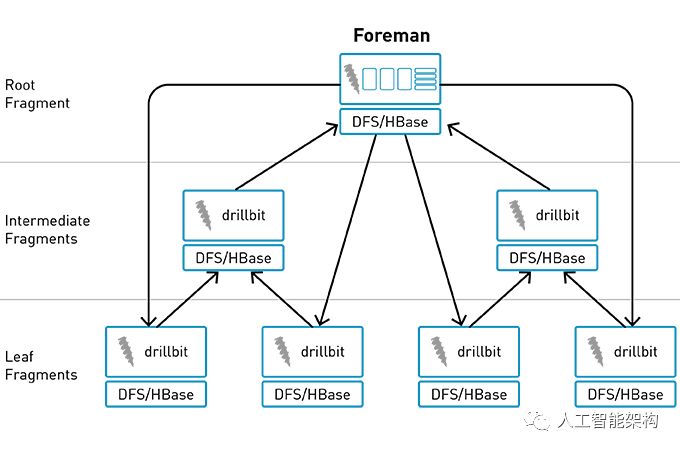
Apache Drill是一个开源,低延迟的大数据查询引擎,可提供PB级的交互式SQL分析。Drill提供了一个大规模并行处理执行引擎,用于跨集群中的各个节点执行分布式查询处理。
使用Drill,可以使用SQL以交互式方式查询和连接JSON,Parquet或CSV格式的文件,Hive和NoSQL存储中的数据,包括HBase,MapR-DB和Mongo,而不需要定义模式。MapR提供了一个Drill JDBC驱动程序,可用于将Java应用程序,BI工具(如SquirreL和Spotfire)连接到Drill。
以下是使用Drill shell的示例SQL查询:
使用命令启动Drill shell:
sqlline -u jdbc : drill : zk =localhost : 5181 -n mapr -p mapr
MapR数据库中存储了多少个流式产品评论?
select count ( _id ) as totalreviews from dfs . ` /user /mapr /reviewtable ` ;
result :
+---------------+
| totalreviews |
+---------------+
| 84160 |
+---------------+
每个评级有多少评论?
select overall , count ( overall ) as countoverall from dfs . ` /user /mapr /reviewtable ` group by overall order by overall desc ;
result :
+----------+---------------+
| overall | countoverall |
+----------+---------------+
| 5.0 | 57827 |
| 4.0 | 20414 |
| 2.0 | 3166 |
| 1.0 | 2753 |
+----------+---------------+
哪个是评价最高的产品?
select overall , asin , count ( *) as ratingcount , sum ( overall ) as ratingsum
from dfs . ` /user /mapr /reviewtable `
group by overall , asin
order by sum ( overall ) desc limit 5 ;
result :
+----------+-------------+--------------+------------+
| overall | asin | ratingcount | ratingsum |
+----------+-------------+--------------+------------+
| 5.0 | B004TNWD40 | 242 | 1210.0 |
| 5.0 | B004U8CP88 | 201 | 1005.0 |
| 5.0 | B006QF3TW4 | 186 | 930.0 |
| 5.0 | B006X9DLQM | 183 | 915.0 |
| 5.0 | B004RR0N8Q | 165 | 825.0 |
+----------+-------------+--------------+------------+
哪些产品具有最积极的评价预测?
select prediction , asin , count ( *) as predictioncount , sum ( prediction ) as predictionsum
from dfs . ` /user /mapr /reviewtable `
group by prediction , asin
order by sum ( prediction ) desc limit 5 ;
result :
+-------------+-------------+------------------+----------------+
| prediction | asin | predictioncount | predictionsum |
+-------------+-------------+------------------+----------------+
| 1.0 | B004TNWD40 | 263 | 263.0 |
| 1.0 | B004U8CP88 | 252 | 252.0 |
| 1.0 | B006X9DLQM | 218 | 218.0 |
| 1.0 | B006QF3TW4 | 217 | 217.0 |
| 1.0 | B004RR0N8Q | 193 | 193.0 |
+-------------+-------------+------------------+----------------+
显示评价最高的产品评论摘要:
select summary , prediction
from dfs . ` /user /mapr /reviewtable `
where asin ='B004TNWD40' limit 5 ;
result :
+---------------------------------------------------+-------------+
| summary | prediction |
+---------------------------------------------------+-------------+
| Awesome | 1.0 |
| for the price you cant go wrong with this knife | 1.0 |
| Great Mora quality and economy | 1.0 |
| Amazing knife | 1.0 |
| Swedish Mil . Mora Knife | 1.0 |
+---------------------------------------------------+-------------+
按照最积极的评价显示产品的评论标记:
select reviewTokens from dfs . ` /user /mapr /reviewtable ` where asin ='B004TNWD40' limit 1 ;
[ "awesome" , "perfect" , "belt/pocket/neck" , "knife" ,
"carbon" , "steel" , "blade" , "last" , "life" , "time!" , "handle" , "sheath" ,
"plastic" , "cheap" , "kind" , "plastic" , "durable" , "also" , "last" , "life" ,
"time" , "everyone" , "loves" , "doors" , "this!" , "yes" , "ones" , "bone" ,
"handles" , "leather" , "sheaths" , "$100+" ]
什么是评价最低的产品?
SELECT asin , overall , count ( overall ) as rcount
FROM dfs . ` /user /mapr /reviewtable `
where overall =1.0
GROUP BY asin , overall
order by count ( overall ) desc limit 2
result :
+-------------+----------+---------+
| asin | overall | rcount |
+-------------+----------+---------+
| B00A17I99Q | 1.0 | 18 |
| B008VS8M58 | 1.0 | 17 |
+-------------+----------+---------+
什么是负面评论预测最多的产品?
select prediction , asin , count ( *) as predictioncount , sum ( prediction ) as predictionsum from dfs . ` /user /mapr /reviewtable ` group by prediction , asin order by sum ( prediction ) limit 2 ;
result :
+-------------+-------------+------------------+----------------+
| prediction | asin | predictioncount | predictionsum |
+-------------+-------------+------------------+----------------+
| 0.0 | B007QEUWSI | 4 | 0.0 |
| 0.0 | B007QTHPX8 | 4 | 0.0 |
+-------------+-------------+------------------+--------------+
显示评价最低的产品的评论摘要
select summary
from dfs . ` /user /mapr /reviewtable `
where asin ='B00A17I99Q' and prediction =0.0 limit 5 ;
result :
+---------------------------------------------------------+
| summary |
+---------------------------------------------------------+
| A comparison to Fitbit One -- The Holistic Wrist |
| Fragile , just like the first Jawbone UP ! Overpriced |
| Great concept , STILL horrible for daily use |
| Excellent idea , bad ergonomics , worse manufacturing . . . |
| get size larger |
+---------------------------------------------------------+
19. 使用MapR数据库Shell查询数据
mapr dbshell是一个工具,可以创建和执行JSON表和文档的基本操作。在登录到MapR集群中的节点后,通过在命令行上键入mapr dbshell来运行dbshell。以下是使用MapR dbshell的一些示例查询:
显示评价最高的产品的评论摘要、ID、预测(_id以B004TNWD40开头)。
find /user /mapr /reviewtable --where '{"$and":[{"$eq":{"overall":5.0}}, { "$like" : {"_id":"%B004TNWD40%"} }]}' --f _id , prediction , summary --limit 5
result :
{ "_id" : "B004TNWD40_1256083200" , "prediction" : 1 , "summary" : "Awesome" }
{ "_id" : "B004TNWD40_1257120000" , "prediction" : 1 , "summary" : "for the price you cant go wrong with this knife" }
{ "_id" : "B004TNWD40_1279065600" , "prediction" : 1 , "summary" : "Amazing knife" }
{ "_id" : "B004TNWD40_1302393600" , "prediction" : 1 , "summary" : "Great little knife" }
{ "_id" : "B004TNWD40_1303257600" , "prediction" : 1 , "summary" : "AWESOME KNIFE" }
显示带有负面情绪预测和标签的10种产品的评论摘要ID
find /user /mapr /reviewtable --where '{"$and":[{"$eq":{"prediction":0.0}},{"$eq":{"label":0.0}} ]}' --f _id , summary --limit 10
result :
{ "_id" : "B003Y64RBA_1312243200" , "summary" : "A $3.55 rubber band!" }
{ "_id" : "B003Y64RBA_1399334400" , "summary" : "cheap not worthy" }
{ "_id" : "B003Y71V2C_1359244800" , "summary" : "Couple of Problems" }
{ "_id" : "B003Y73EPY_1349740800" , "summary" : "Short Term Pedals - Eggbeaters 1" }
{ "_id" : "B003Y9CMGY_1306886400" , "summary" : "Expensive batteries." }
{ "_id" : "B003YCWFRM_1336089600" , "summary" : "Poor design" }
{ "_id" : "B003YCWFRM_1377043200" , "summary" : "Great while it lasted" }
{ "_id" : "B003YD0KZU_1321920000" , "summary" : "No belt clip!!! Just like the other reviewer..." }
{ "_id" : "B003YD0KZU_1338768000" , "summary" : "Useless" }
{ "_id" : "B003YD1M5M_1354665600" , "summary" : "Can't recomend this knife." }
20. 结语
在本文中,学习了如何使用以下内容:
Spark结构化流应用程序中的Spark机器学习模型
Spark结构化流与MapR事件存储使用Kafka API来摄取消息
Spark Structured Streaming可以持久保存到MapR数据库,以便持续快速地进行SQL分析
刚讨论过的用例体系结构的所有组件都可以与MapR数据平台在同一个集群上运行。该MAPR数据平台继承了全球性的活动流,实时数据库的功能和可扩展的企业级存储和Spark 、Drill和机器学习库权限的下一代智能应用,内部搭载现代计算范式的发展优势基础设施。
[source]基于大数据的情绪分析(二)


![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






