[转]如何用Intel Analytics Zoo/BigDL为已有客服平台添加AI功能?

1. 背 景
在如今商业高度发达的社会,客户支持服务平台已被广泛使用在售前和售后为客户提供技术或业务支持,例如银行的电话客服,淘宝京东等电商的在线客服等等。传统的客户支持服务平台仅仅是一个简单的沟通工具,实际的服务和问题解答都是靠大量的人工客服和客户直接交互。后来随着机器智能和自动化技术的提升,越来越多的商家开始为客服系统添加智能模块,节省人力,提升顾客的交互体验。
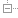
我们有一个试验中的智能客服平台。它主要基于在线的文字对话,客户在对话界面中提出问题,平台从支持文档和预先存储的常用答案中搜寻答案回复客户。如果客户觉得答案给的不合适,可以主动寻求转人工帮助,后台的支持人员会在线和客户对话,提供帮助。基础的客服系统问答给用户自动提供的答案主要来自于预先编辑好的对话流和基于 Information-retrieval 的文档搜索、索引和权重计算。在陆陆续续有了一些真实的问答交互之后,我们希望改进初版的系统,利用机器学习和人工智能实现基于不断累积的真实数据的自动学习和进化。一方面,利用自然语言意图识别和 QA 问答相关技术来提高答案的准确性;另一方面,利用对话内容和其他客户特征进一步提升效率和用户体验——例如对对话进行情感分析,对包含负面情绪的客户进行特殊处理;根据对话内容进行分类,为转接人工对应团队提高服务效率;根据用户画像选择更相关的问题答案。
作为初步尝试,我们在原有的系统中添加了两个新的智能模块(使用 Intel Analytics Zoo 实现):文本分类模块,和 QA 排序模块。文本分类模块的作用是对对话的服务类型进行分类,以使得转接对应人工团队的时候更加高效,这个模块以后经过一些简单的修改还可用于情感分析。QA 排序模块则用来对现在搜索引擎得到的答案进行再排序。
目前我们已经做了一些实验,效果还不错,后续的实验和部署还在进行中。在这个系列博客里,我们会逐步把我们在搭建这个客服平台的流程和经验分享出来,供大家参考借鉴。
在本篇博客中,我们主要介绍基于 Analytics Zoo 0.2.0 版本(https://analytics-zoo.github.io/0.2.0/)为客服平台添加“文本分类”模块的大致流程及实践经验。
2. 为什么采用 Analytics Zoo
Analytics Zoo(https://github.com/intel-analytics/analytics-zoo) 是 Intel 开发的一个开源大数据分析 +AI 平台。项目包含 Scala 和 Python 两套 API,提供了一系列方便实用的封装和工具(包括 Pipeline API 以及更 high-level 的 API,预定义的模型,在公共数据集上预训练的模型,以及参考的实用案例等等),使用户能更容易地使用 Spark 和 Intel BigDL(Intel 开源的一个基于 Spark 的分布式深度学习框架)进行深度学习应用的开发。
客服平台的对话数据量会随着系统投入使用逐渐变得庞大,将数据存放在 Hadoop 集群上可以满足集中管理、分享和可扩展性的需要。而使用 Analytics Zoo 读取和处理存放在 Hadoop/Spark 集群上的数据是非常方便的事情。Analytics Zoo 在标准的 Spark 集群上面使用 Scala API 训练和预测并不需要对云有特殊的改动或配置,还有很多预定义的模型可以开箱即用。在预测的时候,可以使用 Analytics Zoo 提供的 POJO 风格的 service API(本地运行无需 Spark 集群)来做低延迟的预测。如果是对吞吐量要求较高的话,则建议使用 Analytics Zoo 提供的标准 prediction API(可以运行在 Spark 集群上)。这两套 API 都可以很方便地被添加到基于 java 的 service 中。
3. 文本分类概述
文本分类是一种常见自然语言处理任务,主要的目的是将输入的文字片段分配到一个或者多个类别中。例如,垃圾邮件分类就是把邮件的内容片段分配到是否垃圾邮件的类别中。而我们这里的应用场景则是将一段对话归类到一种服务类别中。
训练一个文本分类模型的过程一般包括几个步骤:采集和准备训练数据集和验证数据的文本集,数据清洗和预处理预处理,在训练数据集上训练模型,在验证数据集上评估的指标,如果验证集上的指标不够好,则继续优化模型(包括添加新数据,调整参数,算法等)。
Analytics Zoo 提供了一系列预定义好的文本分类模型(如 CNN, LSTM 和 GRU)。我们直接选择了其中基于 CNN 的分类模型作为基础进行开发(以下训练过程中使用的 API 均以 python API 为例)。

在上面的接口定义中,class_num 是指该文本分类问题包含类的数量,token_length 是指每个词对应词向量的大小,sequence_length 是指每个文本所包含的词的数目,encoder 是指对输入的词向量序列的编码器(可以是 cnn, lstm 或者 gru),encoder_output_dim 是指编码器的输出维度。这个模型接收的输入的是一段文字的词向量的序列,输出是一个类别标签数字。
如果对这个模型内部包含的具体神经网络结构感兴趣,可以查看这段源代码(https://github.com/intel-analytics/analytics-zoo/blob/branch-0.2/pyzoo/zoo/models/textclassification/text_classifier.py#L58-L72 )。
4. 数据采集和预处理
训练数据中的每一条记录包含两个字段:对话历史和对应的服务类别标签。我们采集了几千条这样的记录,并用半自动和人工的方法进行了类标签的标注。拿到原始训练数据以后,首先对对话文本进行了清洗,去掉文本中无意义的 tag 和乱码,并转化成每一条记录都是(text, label)的 text RDD。然后我们对 text RDD 做了预处理,生成文本分类模型可以接收的输入。要注意,数据清洗和预处理的部分,对于训练数据和对将来应用预测中的新数据都要一致。

清洗之后的 text RDD 记录示例 (每条记录都是一对对话文本和类标)
清洗过程这里不再赘述,下面主要介绍预处理主要包含的常用步骤:
1. 中文分词 (Tokenization)
和英文不同,中文文本由连续的字序列组成,每句话的词与词之间没有特定的分隔符,需要通过语义和词典进行分词。我们采用的是 jieba(https://github.com/isuhao/jieba) 对原始文本内容进行分词。经过分词之后,原文本被转化成了一个由词构成的数组。

2. 去掉停用词 (Stopwords Removal)
停用词是在文本检索过程中出现频率很高但又不涉及具体内容的单词,这些词的存在通常对于文本分类的帮助不大。可以选择使用中文常用的停用词表(比如“只要”、“无论”等)或者用户自己指定停用词,将这些词从分词的结果中去除。

3. 统一长度(Sequence Aligning)
不同的文本通常会有不同的长度,但对于一个深度学习模型而言,则需要统一规格的输入,因此我们要把文本对应的词数组转换成相同的长度。对于给定的长度 sequence_length(比如 500),如果文本包含的词数目大于该长度,可以选择从文本开头或者从结尾截取该文本中该长度数量的词。如果文本的词数目不足该长度,则可以在原本的词之前或之后加上虚拟的词来补足(比如“##”)。
![]()
4. 转换为词向量 (Word2Vec)
处理到目前为止每个文本转换成的仍然是词的数组,但要放入模型进行训练,需要的是数值的输入,因此我们需要把每个词转化为相同维度的词向量。我们采用的是 Facebook 开源的词向量工具 FastText (https://github.com/facebookresearch/fastText), FastText 提供预先训练好的中文词向量,每个词对应一个 300 维的空间向量。在词向量的空间中,任意两个向量的之间的距离能体现对应的两个词之间的语义联系,两个语义上很相似或者有很强关联的词对应的词向量会有很近的距离。对于不在预先训练好的 FastText 中的词,我们用一个 300 维的零向量来代替。

5. 转换为 Sample
经过以上的处理之后,每个文本转换为形状是(sequence_length, 300)的多维向量。对于文本所属的类别,我们则转换为整数来表示。把多维向量作为 feature,类别作为 label,每条文本数据生成一个 BigDL Sample (https://bigdl-project.github.io/0.6.0/#APIGuide/Data/#sample )。 最终整个数据集转化成 Sample RDD 用于模型基于 Spark 的分布式训练。
![]()
5. 模型训练,测试,评估和优化
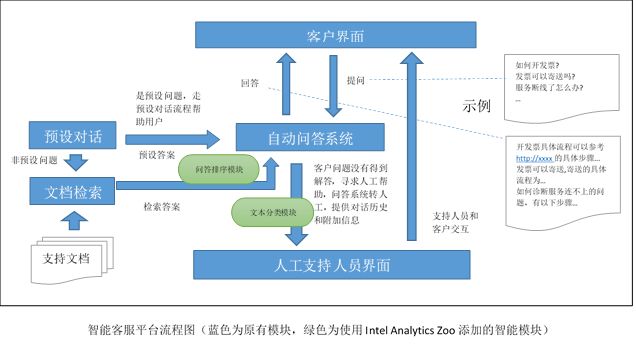
在准备好 RDD 格式的训练集(train_rdd)和验证集(val_rdd),并按照例子实例化好一个模型(text_classifier)之后,我们创建一个 BigDL Optimizer 对模型进行分布式训练。这是一个类别用整数表示的多分类问题,损失函数我们选择的是稀疏分类交叉熵损失 (Sparse Categorical Cross Entropy)。
在创建 Optimizer 的时候可以指定让模型在训练集上进行多少次迭代训练(epochs),每次训练使用的批大小(batch_size),采用的优化方法以及它的学习率(learning rate) 等参数。
可以在训练的过程中,在验证集上输出指定的性能指标 (比如 Top1 accuracy) ,这样能了解到模型在训练的过程中是否已经过拟合。同时 BigDL 也支持在训练过程中阶段性保存快照可用于之后恢复训练。更详细的 Optimizer 的参数和使用方法请参考文档(Analytics-zoo 同时支持 BigDL 0.5 和 0.6 版本,Python pip install 默认同时安装的是 BigDL 0.6 版本):https://bigdl-project.github.io/0.6.0/#ProgrammingGuide/optimization/
如果不选择在训练的过程中验证,也可以在训练完成后,用训练好的模型对验证数据进行预测并检查准确率。要保证验证集也经过了和训练集同样的预处理过程。模型会返回对应的概率分布或者所预测的分类编号。

如果验证集上结果不好,就要对模型进行优化,这个过程基本是重复调参 / 调数据 / 训练 / 测试验证的过程,直到准确率可以满足实用要求。我们这个模型一开始几次的准确率是不够好的,我们之后对学习率进行了调整,并添加了新的训练数据,增加了停用词词典,后来准确率有了大幅提升 。
以上的训练过程在单机上和集群上都可以运行。如何操作可以参考文档:https://analytics-zoo.github.io/0.2.0/#PythonUserGuide/run/
另外,Analytics Zoo 提供了完整的文本分类的指南和实例供用户参考:
https://analytics-zoo.github.io/0.2.0/#ProgrammingGuide/text-classification/ 。
https://github.com/intel-analytics/analytics-zoo/tree/branch-0.2/pyzoo/zoo/examples/textclassification。
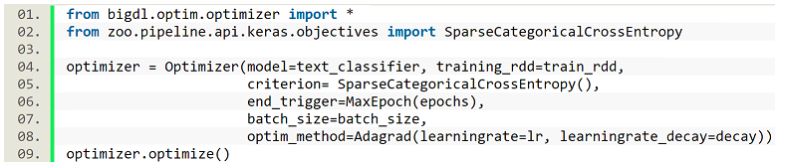
6. 将模型预测部分与 service 集成
拿到训练好的模型之后,接下来要做的就是把新输入的文本经过同样的预处理之后喂给模型,然后模型会输出一个分类的标签。由于我们的微服务是用 Java 实现的,考虑到效率,我们没有直接用 python 代码进行预测,而是用 Analytics Zoo 提供的 POJO 风格的 Java Inference API (用法和接口参考文档 https://analytics-zoo.github.io/0.2.0/#ProgrammingGuide/inference/ ) 实现了预测部分的代码(Java API 可以直接 load python code 训练好的模型来做预测),示意如下。另外 Analytics Zoo 也提供了文本分类的完整的 web service 示例可参考:https://github.com/intel-analytics/analytics-zoo/tree/master/apps/web-service-sample
7. 模型的持续更新和发布
数据是随着时间不断累积的,因此在实际使用中经常会定期使用全量或增量数据重新训练模型,并把模型更新到预测服务中。要实现这一点,只需定期运行训练程序得到新的模型,然后利用上面示例过的 model.load API 重新加载更新过的新模型就可以了。另外,我们的 service 用基于 Kubernetes 的方案进行持续更新和集成。Analytics Zoo 也提供了 docker 的 image (https://github.com/intel-analytics/analytics-zoo/tree/branch-0.2/docker) 供下载安装。
8. 结 语
相信大家看了以上的介绍,已经对如何使用文本分类,以及如何将类似模块添加到自己的应用中有了大致的了解。我们将在这个系列后续的博客中介绍其他方面的内容和实践进展。
如果需要更多信息,请访问 Analytics Zoo 在 Github 上的项目地址(https://github.com/intel-analytics/analytics-zoo) , 并且可以从 Market place 上面下载使用已经准备好的预装 Analytics Zoo 和 BigDL 的镜像(https://market.azure.cn/zh-cn/marketplace/apps/intel.bigdlstandard )。
![[汇总]深度学习文献](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)