[转]缓存构架经验总结 – 5.1. 究竟先操作缓存,还是数据库?
缓存存储,也是数据的冗余。
(1)数据库访问数据,磁盘IO,慢;
(2)缓存里访问数据,存操作,快;
(3)数据库里的热数据,可在缓存冗余一份;
(4)先访问缓存,如果命中,能大大的提升访问速度,降低数据库压力;
这些,是缓存的核心读加速原理。
但是,一旦没有命中缓存,或者一旦涉及写操作,流程会比没有缓存更加复杂,这些是今天要分享的话题。
读操作,如果没有命中缓存,流程是怎么样的?
答:如下图所示
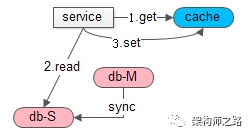
(1)尝试从缓存get数据,结果没有命中;
(2)从数据库获取数据,读从库,读写分离;
(3)把数据set到缓存,未来能够命中缓存;
读操作的流程应该没有歧义。
写操作,流程是怎么样的?
答:写操作,既要操作数据库中的数据,又要操作缓存里的数据。
这里,有两个方案:
(1)先操作数据库,再操作缓存;
(2)先操作缓存,再操作数据库;
并且,希望保证两个操作的原子性,要么同时成功,要么同时失败。
这演变为一个分布式事务的问题,保证原子性十分困难,很有可能出现一半成功,一半失败,接下来看下,当原子性被破坏的时候,分别会发生什么。
一、先操作数据库,再操作缓存
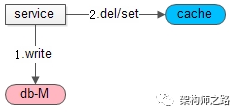
如上图,正常情况下:
(1)先操作数据库,成功;
(2)再操作缓存(delete或者set),也成功;
但如果这两个动作原子性被破坏:第一步成功,第二步失败,会导致,数据库里是新数据,而缓存里是旧数据,业务无法接受。
画外音:如果第一步就失败,可以返回调用方50X,不会出现数据不一致。
二、先操作缓存,再操作数据库
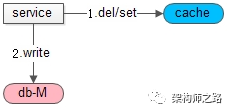
如上图,正常情况下:
(1)先操作缓存(delete或者set),成功;
(2)再操作数据库,也成功;
画外音:如果第一步就失败,也可以返回调用方50X,不会出现数据不一致。
如果原子性被破坏,会发生什么呢?
这里又分了两种情况:
(1)操作缓存使用set
(2)操作缓存使用delete
使用set的情况:第一步成功,第二步失败,会导致,缓存里是set后的数据,数据库里是之前的数据,数据不一致,业务无法接受。
并且,一般来说,数据最终以数据库为准,写缓存成功,其实并不算成功。
使用delete的情况:第一步成功,第二步失败,会导致,缓存里没有数据,数据库里是之前的数据,数据没有不一致,对业务无影响。只是下一次读取,会多一次cache miss。
画外音:此时可以返回调用方50X。
最终,先操作缓存,还是先操作数据库?
答:
(1)读请求,先读缓存,如果没有命中,读数据库,再set回缓存
(2)写请求
(2.1)先数据库,再缓存
(2.2)缓存,使用delete,而不是set
画外音:《 4. 缓存,究竟是淘汰,还是修改?》也提到了,淘汰缓存还是修改缓存的建议。
希望大家有收获,有不同方案欢迎讨论。
末了,挖个坑:
在缓存读取流程中,如果主从没有同步完成,步骤二读取到一个旧数据,可能导致缓存里set一个旧数据,最终导致数据库和缓存数据不一致。
1. 补充:
1-1. 缓存维护方案四
这个是方案三的改进方案,都是先操作数据库再操作缓存,我们来看一下流程图:
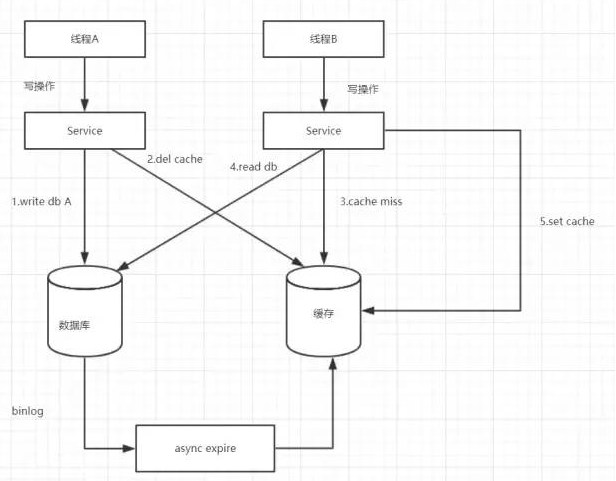
通过数据库的binlog来异步淘汰key,以mysql为例,可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK机制确认处理 这条更新消息,删除缓存,保证数据缓存一致性。
但是呢还有个问题,如果是主从数据库呢?
1-2. 缓存维护方案五
主从DB问题:因为主从DB同步存在同时延时时间如果删除缓存之后,数据同步到备库之前已经有请求过来时,会从备库中读到脏数据,如何解决呢?
解决方案如下流程图:
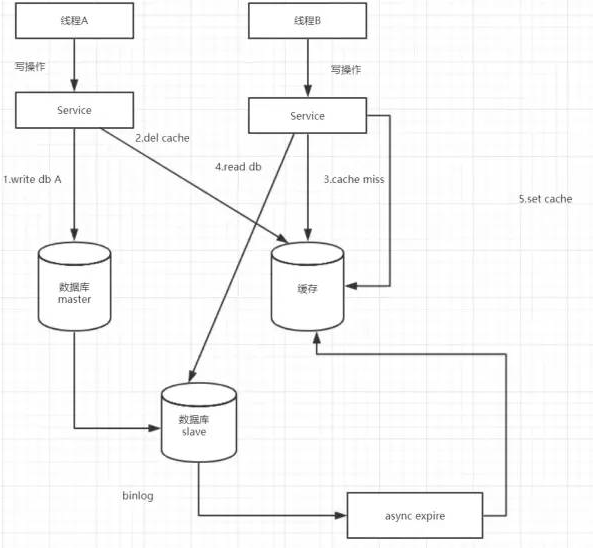
2. 缓存维护总结
综上所述,在分布式系统中,缓存和数据库同时存在时,如果有写操作的时候,先操作数据库,再操作缓存。如下:
(1)读取缓存中是否有相关数据
(2)如果缓存中有相关数据value,则返回
(3)如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中key->value,再返回
(4)如果有更新数据,则先更新数据,再删除缓存
(5)为了保证第四步删除缓存成功,使用binlog异步删除
(6)如果是主从数据库,binglog取自于从库
(7)如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存
[source]究竟先操作缓存,还是数据库?



![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






