[转]聊聊Chaos Engineering的历史、原则和最佳实践

随着微服务和分布式云架构的崛起,Web 变得日趋复杂,“随机性”的故障因此变得越来越难以预测,而我们对这些系统的依赖却与日俱增。
这些故障给公司造成巨大损失,也给用户带来很大的麻烦,影响他们进行在线购物、交易或打断他们的工作。即使是一些简单的故障也会触及公司的底线,因此,宕机时间就成为很多工程团队的 KPI。2017 年,有 98% 的企业表示,一小时的宕机时间将给他们带来超过 10 万美元的损失。一次服务中断有可能让一个公司损失数百万美元。最近,英国航空的 CEO 透露,2017 年 5 月发生的一次技术故障造成数千名乘客滞留机场,给公司造成 8000 万英镑的损失。
企业需要想办法解决这些问题,因为等到下一次事故发生就为时已晚。为此,混沌工程(Chaos Engineering)应运而生。
混沌工程(Chaos Engineering)旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。
混沌工程将预想的事情与实际发生的事情进行对比,通过“有意识地搞破坏”来提升系统的弹性。
1. 混沌工程简史
混沌工程最先出现在互联网巨头公司中,这些公司拥有大规模的分布式系统,因为这些系统太过复杂,他们需要一些新的手段来测试它们。
2010 年
Netflix Eng Tools 团队开发出了 Chaos Monkey。当时,Netflix 从物理基础设施迁移到 AWS 上,为了保证 AWS 实例的故障不会给 Netflix 的用户体验造成影响,他们开发了这个工具,用来测试系统。
2011 年
Simian Army 诞生,在 Chaos Monkey 的基础上增加了故障注入模式,可以测试更多的故障场景。Netflix 认为,云的特点是冗余和容错,但没有哪个组件能够保证 100% 的可用性,所以他们必须设计出一种云架构,在这种架构里,个体组件的故障不会影响到整个系统。
2012 年
Netflix 在 GitHub 上开源了 Chaos Monkey,并声称他们“已经找到了应对主要非预期故障的解决方案。通过经常性地制造故障,我们的服务因此变得更有弹性。”
2014 年
Netflix 团队创建了一种新的角色,叫作混沌工程师。Bruce Wong 发明了这个角色,并由 Dan Woods 在 Twitter 上向广大的工程社区推广。Dan Woods 解释说,“我从 Kolton Andrus 那里学到了更多有关混沌工程的知识,他把它叫作故障注入测试”。
2014 年 10 月,当时 Gremlin 的联合创始人 Kolton Andrus 还在 Netflix,他们在 Simian Army 的基础上提出了故障注入测试(FIT)概念,开发者可以更灵活地控制注入故障的“杀伤力范围”。因为 Simian Army 有时候会造成非常严重的故障,所以 Netflix 的开发者对它抱有疑虑,而 FIT 可以更好地控制故障粒度,于是他们就由此想出了混沌工程这个概念。
2. 混沌工程的原则
混沌工程通过运行经过仔细计划的试验来了解系统在发生故障时的行为,一般分为三个步骤:

先是假设系统在出现故障时的行为。
然后,设计针对性的试验来测试系统。
最后,在每一步评估故障产生的影响,看看有哪些正面或负面的征兆。在完成试验之后,就可以更好地了解系统的真实行为。
3. 哪些公司在实践混沌工程?
因为微服务架构的普及,很多大型的技术公司都在采用混沌工程,如 Twilio、Netflix、领英、Facebook、谷歌、微软和亚马逊。
混沌工程在银行和金融行业也有所应用。2014 年,澳大利亚国家银行从物理基础设施迁移到 AWS,通过混沌工程显著减少了事故数量。
4. 为什么要有目的地搞破坏?
就像打疫苗可以预防疾病一样,我们可以通过混沌工程来提升系统的免疫能力。我们向系统注入故障(比如延迟、CPU 故障、网络黑洞),找出系统潜在的弱点。
这些试验增强了我们应对故障的能力,就像防火演习一样。通过有目的地搞破坏,可以识别出未知的问题。
5. 混沌工程在分布式系统中的角色
分布式系统要比单体系统复杂得多,因此,它们的故障是很难预测的。Peter Deutsch 提出的分布式系统八大谬论概括了程序员新手可能对分布式系统做出的错误假设:
- 网络是可靠的
- 延迟是零
- 带宽是无限的
- 网络是安全的
- 拓扑结构不会变
- 存在管理员这样的角色
- 传输成本是零
- 网络是同质的
这些谬论当中有几项正是混沌工程的关注点,比如“数据包攻击”和“延迟攻击”。网络中断可能造成大面积的应用程序故障,严重影响用户体验。应用程序可能会因为无限期地等待一个数据包而停止响应,或者持续不断地消耗系统资源。即使网络从中断中恢复,应用程序可能仍然无法重试挂起的操作,需要手动重启才行。这些情况都需要进行测试和预防。
6. 混沌工程给客户、业务和技术带来的好处
- 客户:增强的服务可用性和持久性意味着他们的日常生活不会受到影响。
- 业务:混沌工程有助于避免公司的利润受到损失,降低维护成本,提升工程师的愉悦感和参与度,改进整个公司的事故处理流程。
- 技术:混沌工程旨在减少事故和轮班待命的负担,更好地了解系统的故障模式,改进系统设计,更快地检测到事故,减少类似事故的发生。
7. 服务团队的混沌工程
包括 Netflix 和 Stitch Fix 在内的很多技术公司都有自己的混沌工程团队,它们的规模一般都很小,由 2 到 5 个人组成。这些团队负责整个组织的混沌工程实施,不过,他们不一定就是唯一在组织内实施混沌工程的团队。实际上,他们还可以推动其他团队参与到混沌工程中来。
其他参与实施混沌工程的团队包括:
- 流量团队(比如 Nginx、Apache、DNS)
- 流团队(比如 Kafka)
- 存储团队(比如 S3)
- 数据团队(比如 Hadoop/HDFS)
- 数据库团队(比如 MySQL、Amazon RDS、PostgreSQL)
有些公司(比如 Remind)将混沌工程集成到他们的发布流程当中,就像将测试作为确保功能质量的关键环节一样。
8. 混沌测试的执行顺序
我们建议按照以下的顺序来执行混沌工程试验:
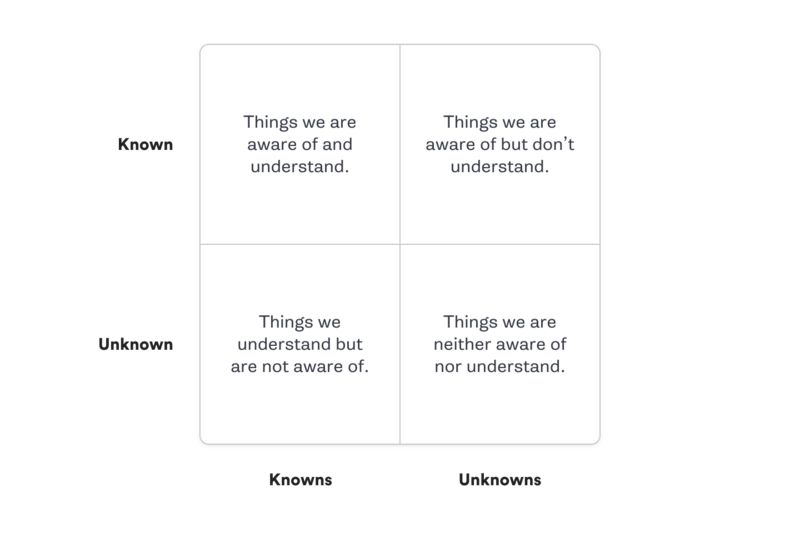
- Known Known:已经了解并注意到的。
- Known Unknown:注意到但不了解的。
- Unknown Known:了解但没有注意到的。
- Unknown Unknown:既没有注意到也不了解的。
下图解释了这一概念:
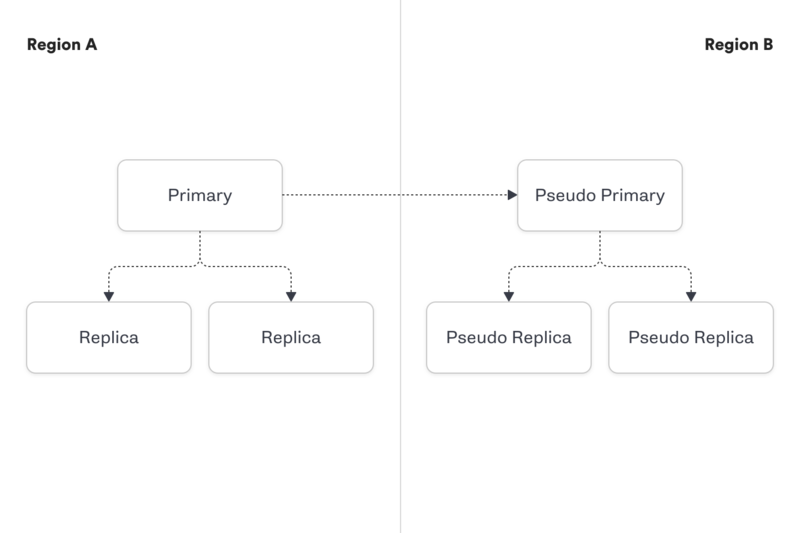
为演示这一过程,我们以一个分片的 MySQL 数据库为例。假设我们有一个包含了 100 个 MySQL 主机的集群,其中的每个主机包含了多个分片。
在其中的一个区域中,我们一个主数据库,它有两个副本,并启用了半同步复制。在另一个区域,我们有一个伪主数据库和两个伪副本。
Known Known
我们知道,副本如果发生宕机,就会从集群中移除。我们也知道,一个新的副本会从主数据库复制数据,然后加入到集群中。
Known Unknown
- 我们知道会发生数据复制,因为我们可以查看日志,但并不知道从发生故障到数据复制完毕并将副本加入到集群中需要花多少时间。
- 我们知道在一个副本发生宕机 5 分钟后会收到一个告警,但并不知道是否有必要调大告警的频率,以便检测到更多的故障。
Unknown Known
如果同时关闭集群的两个副本,我们不知道从主数据库那里复制数据平均需要花多少时间,但我们知道我们有一个伪主数据库和两个伪副本,它们也持有交易数据。
Unknown Unknown
我们不知道如果关闭主区域的整个集群将会发生什么,也不知道另一个区域是否能够有效地接管服务,因为我们还没有测试过这种场景。
我们将按如下的顺序执行混沌测试:
- Known Known:关闭其中的一个副本,并计算从检测到关闭、移除副本、完成数据复制到新副本加入集群平均花费的时间。在开始这步测试之前,可以将副本增加到三个。这一步可以常规性地执行,但注意不要让可用的副本数量降到零。
- Known Unknown:通过上一步的数据了解到哪些是“Known Unknown”的,也就知道了从副本发生故障到新副本加入集群需要的平均时间,而且也知道了 5 分钟是不是个合适的告警阈值。
- Unknown Known:在执行这一步时,先将副本数量增加到四个,然后同时关闭其中的两个副本,计算复制两个副本所需要的平均时间。这一步可能会检查出未知的问题,比如,主数据库可能无法承担同时多个副本复制数据的负载,所以需要调整副本的数量。
- Unknown Unknown:关闭整个集群(包括主数据库和两个副本),或许这一步会造成不可预期的结果,让人措手不及,所以在执行这一步之前要调动所有的工程力量,做好应对准备。
9. 如何规划第一个混沌测试?
混沌工程中最有用的一个问题是:“哪里可能出问题?”通过这种方式不断质疑我们的服务和运行环境,可以帮助我们发现潜在的弱点,并讨论出预期的结果。与风险管理类似,我们因此可以知道哪些场景更有可能发生,以及需要优先测试哪些场景。大家坐下来,在白板上画出服务、依赖和数据存储组件,围绕“哪里可能出问题”的思路展开讨论。对哪里有质疑,就在这个地方注入一个故障。
在知道哪里可能出问题后,在相应的地方注入故障。那么接下来呢?通过对场景展开讨论,可以对预期的结果有一个假设。比如,这将会给客户、服务或依赖带来哪些影响?
要了解系统在压力下运行时的行为,需要对系统的可用性和持久性进行评估。可以使用与客户相关的度量指标来评估,比如每分钟的订单量。从经验来看,如果这些指标出现异常,必须立即停止测试。接下来要评估故障本身,以便验证之前的假设。被影响到的有可能是延迟、每秒的请求数或系统资源。最后,查看仪表盘和告警,看看有没有出现非预期的副作用。
制定回退计划是很有必要的,而且要接受回退计划也可能失效的事实。告诉大家将以怎样的方式进行回退,如果是通过手动执行命令的方式,注意不要让与服务实例连接的 ssh 或控制面板出现问题。
在运行了第一个测试之后,应该能够得到一两个有用的结果。最起码已经验证了系统在出现这些故障时是否具备弹性,或者找到了修复问题的方式。这些都是好的产出结果。一方面,我们对系统的行为更有信心,另一方面,我们找到了一个潜在的问题。
10. 更多的一些资料
- https://www.infoq.com/interviews/kolton-andrus-on-breaking-things-at-netflix
- https://www.youtube.com/watch?v=rgfww8tLM0A
- https://www.youtube.com/watch?v=hRwfLEc-0p4
- https://www.youtube.com/watch?v=qHykK5pFRW4
- https://www.youtube.com/watch?v=h_-shm0SL08
- https://github.com/dastergon/awesome-chaos-engineering
- https://www.gremlin.com/community/tutorials/4-chaos-experiments-to-start-with/
- http://meetup.com/pro/chaos
[source]聊聊Chaos Engineering的历史、原则和最佳实践
![[转]10 个角度分析软件工程师应该知道的 100 件事](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






