[转]缓存构架经验总结 – 3.1. 服务通过缓存传递数据,绝不推荐
《服务通过缓存传递数据,是否可行》一文引发一个服务之间“通过缓存传递数据”设计合理性的讨论。
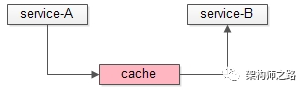
如上图:
- service-A将数据放入cache
- service-B从cache里读取数据
这种架构设计好还是不好,网友进行了激烈的讨论,感兴趣的同学可以看下《服务通过缓存传递数据,是否可行》的评论,看到这么多互联网技术人对一个技术方案问题进行思考与探讨,很是开心。这里,分享下个人的观点。
先说结论
楼主旗帜鲜明的反对“服务之间通过缓存传递数据”。
核心理由
一、数据管道场景,MQ比cache更加适合
如果只是单纯的将cache作为两个服务数据通讯的管道,service-A生产数据,service-B(当然,可能有service-C/service-D等)订阅数据,MQ比cache更加合适:
- MQ是互联网常见的逻辑解耦,物理解耦组件,支持1对1,1对多各种模式,非常成熟的数据通道
画外音:详见《MQ,互联网架构解耦神器》
- 而cache反而会将service-A/B/C/D耦合在一起,大家要彼此协同约定key的格式,ip地址等
- MQ能够支持push,而cache只能拉取,不实时,有时延
- MQ天然支持集群,支持高可用,而cache未必
- MQ能支持数据落地,cache具备将数据存在内存里,具有“易失”性,当然,有些cache支持落地,但互联网技术选型的原则是,让专业的软件干专业的事情:nginx做反向代理,db做固化,cache做缓存,mq做通道
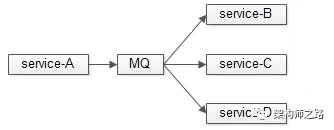
综上,数据管道场景,MQ比cache更加适合。
二、数据共管场景,两个(多个)service同时读写一个cache实例会导致耦合
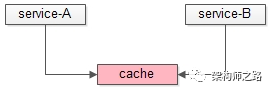
如果不是数据管道,是两个(多个)service对一个cache进行数据共管,同时读写,也是不推荐的,这些service会因为这个cache耦合在一起:
- 大家要彼此协同约定key的格式,ip地址等,耦合
- 约定好同一个key,可能会产生数据覆盖,导致数据不一致
- 不同服务业务模式,数据量,并发量不一样,会因为一个cache相互影响,例如service-A数据量大,占用了cache的绝大部分内存,会导致service-B的热数据全部被挤出cache,导致cache失效;又例如service-A并发量高,占用了cache的绝大部分连接,会导致service-B拿不到cache的连接,从而服务异常
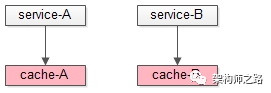
综上,数据共管场景,多个service耦合在一个cache实例里,也是不推荐的,需要垂直拆分,实例解耦。
三、数据访问场景,两个(多个)service有读写一份数据的需求
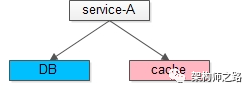
根据服务化的原则,数据是私有的(本质也是解耦):
- service层会向数据的需求方屏蔽下层存储引擎,分库,chace的复杂性
- 任何需求方不能绕过service读写其后端的数据
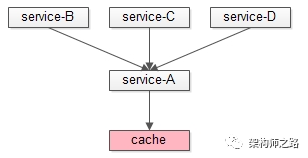
假设有其他service要有数据获取的需求,应该通过service提供的RPC接口来访问,而不是直接读写后端的数据,无论是cache还是db。
综上
- 数据管道,MQ比cache更合适
- 多个服务不应该公用一个cache实例,应该垂直拆分解耦
- 服务化架构,不应该绕过service读取其后端的cache/db,而应该通过RPC接口访问
希望逻辑是清晰的,供大伙参考,欢迎不同的声音共同探讨。
[source]服务通过缓存传递数据,绝不推荐
![[汇总]Distributed Cache经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






