[总结]分表分库时机选择及策略

1. 一. 分表
1-1. 应用场景:
对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级甚至是亿级,并且数据库面临着极高的并发访问。采用Master-Slave复制模式的MySQL架构,只能够对数据库的读进行扩展,而对数据库的写入操作还是集中在Master上,并且单个Master挂载的Slave也不可能无限制多,Slave的数量受到Master能力和负载的限制。
因此,需要对数据库的吞吐能力进行进一步的扩展,以满足高并发访问与海量数据存储的需要!
1-1-1. 设计策略
对于访问极为频繁且数据量巨大的单表来说,我们首先要做的就是减少单表的记录条数,以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表!
在分表之前,首先需要选择适当的分表策略,使得数据能够较为均衡地分不到多张表中,并且不影响正常的查询!
对于互联网企业来说,大部分数据都是与用户关联的,因此,用户id是最常用的分表字段。因为大部分查询都需要带上用户id,这样既不影响查询,又能够使数据较为均衡地分布到各个表中(当然,有的场景也可能会出现冷热数据分布不均衡的情况),如下图:
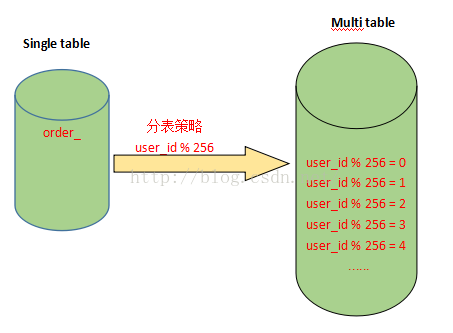
假设有一张表记录用户购买信息的订单表order,由于order表记录条数太多,将被拆分成256张表。
拆分的记录根据user_id%256取得对应的表进行存储,前台应用则根据对应的user_id%256,找到对应订单存储的表进行访问。
这样一来,user_id便成为一个必需的查询条件,否则将会由于无法定位数据存储的表而无法对数据进行访问。
注:拆分后表的数量一般为2的n次方,就是上面拆分成256张表的由来!
假设order表结构如下:
那么分表以后,假设user_id = 257,并且auction_id = 100,需要根据auction_id来查询对应的订单信息,则对应的SQL语句如下:
其中,order_1是根据257%256计算得出,表示分表之后的第一张order表。
2. 二. 分库
2-1. 应用场景:
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库!
2-1-1. 设计策略
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示:
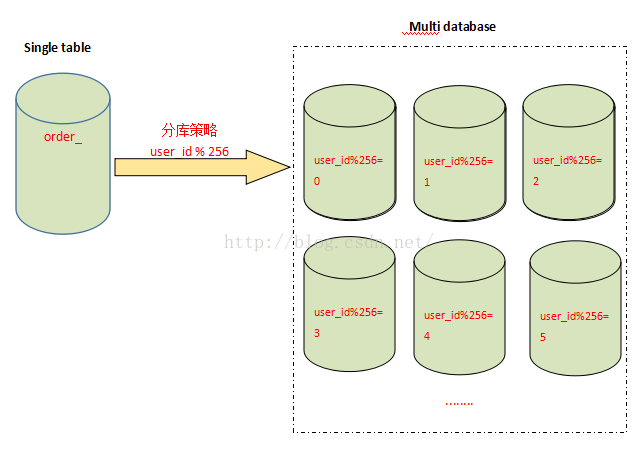
还是之前的订单表,假设user_id 字段的值为258,将原有的单库分为256个库,那么应用程序对数据库的访问请求将被路由到第二个库(258%256 = 2)。
3. 三. 分库分表
3-1. 应用场景:
有时数据库可能既面临着高并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库既采用分表策略,又采用分库策略,以便同时扩展系统的并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。
3-1-1. 设计策略
分库分表的策略比前面的仅分库或者仅分表的策略要更为复杂,一种分库分表的路由策略如下:
1. 中间变量 = user_id % (分库数量 * 每个库的表数量)
2. 库 = 取整数 (中间变量 / 每个库的表数量)
3. 表 = 中间变量 % 每个库的表数量
同样采用user_id作为路由字段,首先使用user_id 对库数量*每个库表的数量取模,得到一个中间变量;然后使用中间变量除以每个库表的数量,取整,便得到对应的库;而中间变量对每个库表的数量取模,即得到对应的表。
分库分表策略详细过程如下:
假设将原来的单库单表order拆分成256个库,每个库包含1024个表,那么按照前面所提到的路由策略,对于user_id=262145 的访问,路由的计算过程如下:
这就意味着,对于user_id=262145 的订单记录的查询和修改,将被路由到第0个库的第1个order_1表中执行!!!
4. 四.互联网公司为啥都不用分区表?
什么是分区表?
所有数据,逻辑上还在一个表中,但物理上,可以根据一定的规则放在不同的文件中。这是MySQL5.1之后支持的功能,业务代码无需改动。
分区表看上去很帅气,为什么大部分互联网公司不使用,而更多的选择分库分表来进行水平切分呢?
分区表的一些缺点,是大数据量,高并发量的业务难以接受的:
(1)如果SQL不走分区键,很容易出现全表锁;
(2)在分区表实施关联查询,就是一个灾难;
(3)分库分表,自己掌控业务场景与访问模式,可控;分区表,工程师写了一个SQL,自己无法确定MySQL是怎么玩的,不可控;
画外音:类似于,不要把业务逻辑实现在存储过程,用户自定义函数,触发器里,而要实现在业务代码里一样。
(4)DBA给OP埋坑,容易大打出手,造成同事矛盾;
当然,在数据量和并发量不太大,或者按照时间来存储冷热数据或归档数据的一些特定场景下,分区表还是有上场机会的。
画外音:例如,按照时间分区,存储日志。
5. 五. 流量与时机
5-1. 1 一个数据库
注册用户就20万,每天活跃用户就1万,每天单表数据量就1000,然后高峰期每秒钟并发请求最多就10.
5-2. 2 多台服务器分库支撑高并发读写
注册用户数达到了2000万!每天活跃用户数100万!高峰期每秒请求量达到1万。20台机器,平均每台机器每秒支撑500请求,这个还能抗住,没啥大问题。
每天单表新增50万条数据,一个月就多1500万条数据,一年下来单表会达到上亿条数据。
通常来说,假如你用普通配置的服务器来部署数据库,那也起码是16核32G的机器配置。
这种非常普通的机器配置部署的数据库,一般线上的经验是:不要让其每秒请求支撑超过2000,一般控制在2000左右。
控制在这个程度,一般数据库负载相对合理,不会带来太大的压力,没有太大的宕机风险。
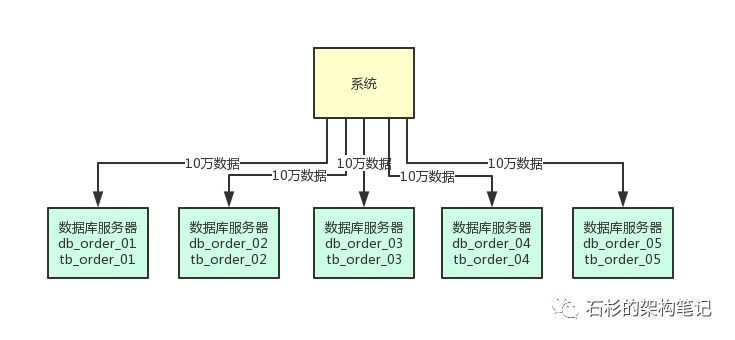
所以首先第一步,就是在上万并发请求的场景下,部署个5台服务器,每台服务器上都部署一个数据库实例。
然后每个数据库实例里,都创建一个一样的库,比如说订单库。
此时在5台服务器上都有一个订单库,名字可以类似为:db_order_01,db_order_02,等等。
然后每个订单库里,都有一个相同的表,比如说订单库里有订单信息表,那么此时5个订单库里都有一个订单信息表。
比如db_order_01库里就有一个tb_order_01表,db_order_02库里就有一个tb_order_02表。
这就实现了一个基本的分库分表的思路,原来的一台数据库服务器变成了5台数据库服务器,原来的一个库变成了5个库,原来的一张表变成了5个表。
然后你在写入数据的时候,需要借助数据库中间件,比如sharding-jdbc,或者是mycat,都可以。
你可以根据比如订单id来hash后按5取模,比如每天订单表新增50万数据,此时其中10万条数据会落入db_order_01库的tb_order_01表,另外10万条数据会落入db_order_02库的tb_order_02表,以此类推。
这样就可以把数据均匀分散在5台服务器上了,查询的时候,也可以通过订单id来hash取模,去对应的服务器上的数据库里,从对应的表里查询那条数据出来即可。
依据这个思路画出的图如下所示,大家可以看看。
做这一步有什么好处呢?
第一个好处,原来比如订单表就一张表,这个时候不就成了5张表了么,那么每个表的数据就变成1/5了。
假设订单表一年有1亿条数据,此时5张表里每张表一年就2000万数据了。
那么假设当前订单表里已经有2000万数据了,此时做了上述拆分,每个表里就只有400万数据了。
而且每天新增50万数据的话,那么每个表才新增10万数据,这样是不是初步缓解了单表数据量过大影响系统性能的问题?
另外就是每秒1万请求到5台数据库上,每台数据库就承载每秒2000的请求,是不是一下子把每台数据库服务器的并发请求降低到了安全范围内?
这样,降低了数据库的高峰期负载,同时还保证了高峰期的性能。
5-3. 3. 大量分表来保证海量数据下的查询性能
但是上述的数据库架构还有一个问题,那就是单表数据量还是过大,现在订单表才分为了5张表,那么如果订单一年有1亿条,每个表就有2000万条,这也还是太大了。
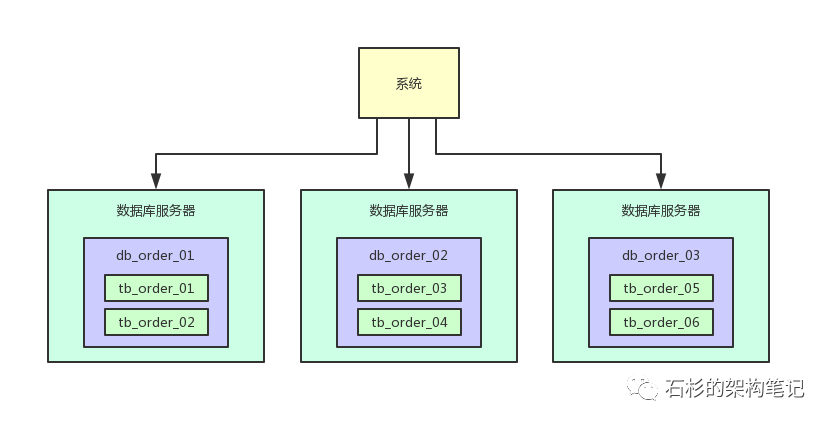
所以还应该继续分表,大量分表。
比如可以把订单表一共拆分为1024张表,这样1亿数据量的话,分散到每个表里也就才10万量级的数据量,然后这上千张表分散在5台数据库里就可以了。
在写入数据的时候,需要做两次路由,先对订单id hash后对数据库的数量取模,可以路由到一台数据库上,然后再对那台数据库上的表数量取模,就可以路由到数据库上的一个表里了。
通过这个步骤,就可以让每个表里的数据量非常小,每年1亿数据增长,但是到每个表里才10万条数据增长,这个系统运行10年,每个表里可能才百万级的数据量。
这样可以一次性为系统未来的运行做好充足的准备,看下面的图,一起来感受一下:
5-4. 4. 读写分离来支撑按需扩容以及性能提升
这个时候整体效果已经挺不错了,大量分表的策略保证可能未来10年,每个表的数据量都不会太大,这可以保证单表内的SQL执行效率和性能。
然后多台数据库的拆分方式,可以保证每台数据库服务器承载一部分的读写请求,降低每台服务器的负载。
但是此时还有一个问题,假如说每台数据库服务器承载每秒2000的请求,然后其中400请求是写入,1600请求是查询。
也就是说,增删改的SQL才占到了20%的比例,80%的请求是查询。
此时假如说随着用户量越来越大,假如说又变成每台服务器承载4000请求了。
那么其中800请求是写入,3200请求是查询,如果说你按照目前的情况来扩容,就需要增加一台数据库服务器.
但是此时可能就会涉及到表的迁移,因为需要迁移一部分表到新的数据库服务器上去,是不是很麻烦?
其实完全没必要,数据库一般都支持读写分离,也就是做主从架构。
写入的时候写入主数据库服务器,查询的时候读取从数据库服务器,就可以让一个表的读写请求分开落地到不同的数据库上去执行。
这样的话,假如写入主库的请求是每秒400,查询从库的请求是每秒1600,那么图大概如下所示。
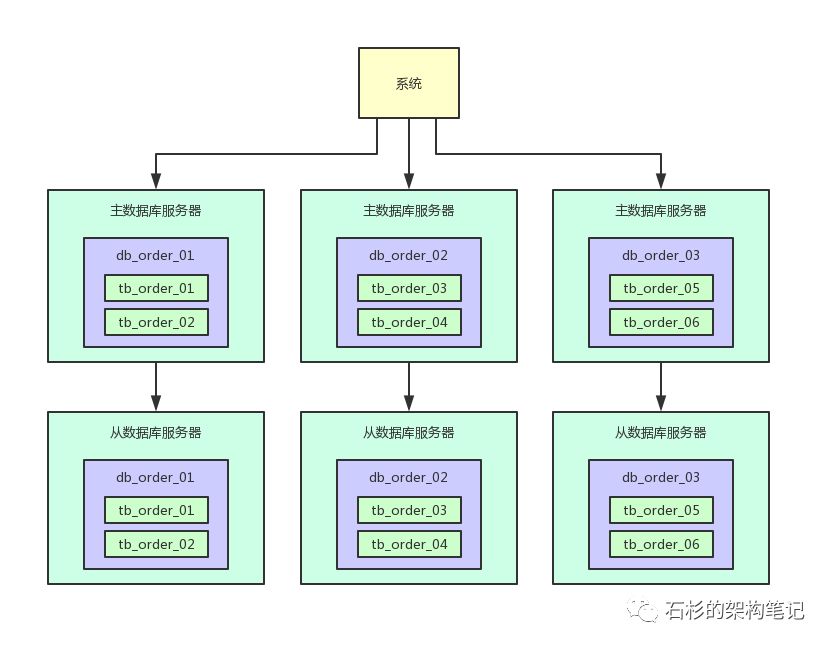
写入主库的时候,会自动同步数据到从库上去,保证主库和从库数据一致。
然后查询的时候都是走从库去查询的,这就通过数据库的主从架构实现了读写分离的效果了。
现在的好处就是,假如说现在主库写请求增加到800,这个无所谓,不需要扩容。然后从库的读请求增加到了3200,需要扩容了。
这时,你直接给主库再挂载一个新的从库就可以了,两个从库,每个从库支撑1600的读请求,不需要因为读请求增长来扩容主库。
实际上线上生产你会发现,读请求的增长速度远远高于写请求,所以读写分离之后,大部分时候就是扩容从库支撑更高的读请求就可以了。
而且另外一点,对同一个表,如果你既写入数据(涉及加锁),还从该表查询数据,可能会牵扯到锁冲突等问题,无论是写性能还是读性能,都会有影响。
所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响他,对从库的表就仅仅是查询。
5-5. 4. 小结
- 数据库16核32G, 控制QPS <2000
- 每个分表最好百万以内
- 然后读写分离,分隔QPS,只读从库可以无限扩展降低QPS
[source]分表分库时机选择及策略
![[转]工行日均7亿交易量高可用的MySQL架构](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






