[转]大规模集群任务调度

随着分布式计算集群规模的不断扩张,任务调度系统的稳定性成为了整个集群稳定的关键因素。随着容器技术的快速兴起,基于容器的计算平台被大量应用,任务调度的规模及频率快速上升,这对任务调度系统提出了更为严苛的挑战。
常见的调度系统往往兼顾了准确度却牺牲了性能,容器调度的复杂性使得很难在准确和效率之间找到平衡点,尤其是在交互式调度的场景下,可取的解决方案更是捉襟见肘。本篇文章就以此为背景,介绍大规模调度场景下分布式任务调度的难点、解决策略及现有的一些方案。
1. 任务调度框架的设计目标
计算任务通常分为两个大的类别,即以守护进程形式运行的长任务和以批处理形式运行的短任务,前者资源的使用率变化幅度小,而后者资源使用率变化大。本篇我们讨论的主要是针对计算密集型的场景,即以批处理形式运行的数据处理任务。
调度系统的核心目标: 快速准确地位为任务匹配合适的计算资源。但快速 (Low Placement latency) 和准确 (High Quality Placement) 这两个目标会产生矛盾,即必须在二者间权衡。尤其是在交互式调度场景下,只追求准确度而忽视效率会使得调度失去意义。
调度系统的本质是为计算任务匹配合适的资源,使其能够稳定高效地运行,而影响应用运行的因素非常多,比如 CPU、内存、网络、端口等等一系列因素都会影响应用运行的表现。于此同时,整个计算集群的资源使用情况是动态变化的,大量的应用被创建、销毁和迁移,调度决策的过程如果不够快,那么实际运行时面对的资源情况可能与决策时千差万别。
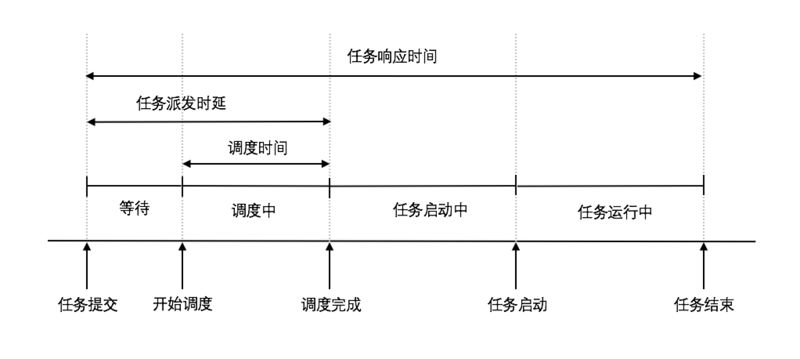
计算任务的调度不仅仅要考虑资源本身的状况,而且还要结合任务本身的优先级来考虑抢占式调度的情景。比如系统出现异常,临时增加诊断性任务,就必须以高于其他任务的优先级来运行。有资源抢占就涉及到任务驱逐、重调度等情况,这里面会涉及驱逐相关的算法策略、调度流程的复用等。
2. 目前的主流任务调度框架
从目前常用的任务调度框架来看,Apache Mesos 是面向数据中心资源管理的典型代表。Hadoop YARN 调度器是面向计算任务的,与 Mesos 相似之处在于也是两层调度机制,不同在于考虑了资源抢占机制,能够处理任务的优先级对调度结果的影响。这些年发展迅速的 Kubernetes 也包含调度器,其本质上还是面向应用运行层面,默认调度器的策略比较丰富,扩展性也比较好,但在面对大规模的调度时,吞吐性能表现不是那么完美。
2-1. Apache Mesos
Apache Mesos 将 CPU、内存、存储和其他计算资源从机器 (物理或虚拟) 中抽象出来,使容错和弹性分布式系统能够轻松构建并有效运行。Mesos 采用的Resource Offer使得任务框架能够自行决定是否接受 Mesos Master 的Offer,在实际使用过程中,资源框架中的调度机制需要用户自行实现,还是略微有些工作量的。
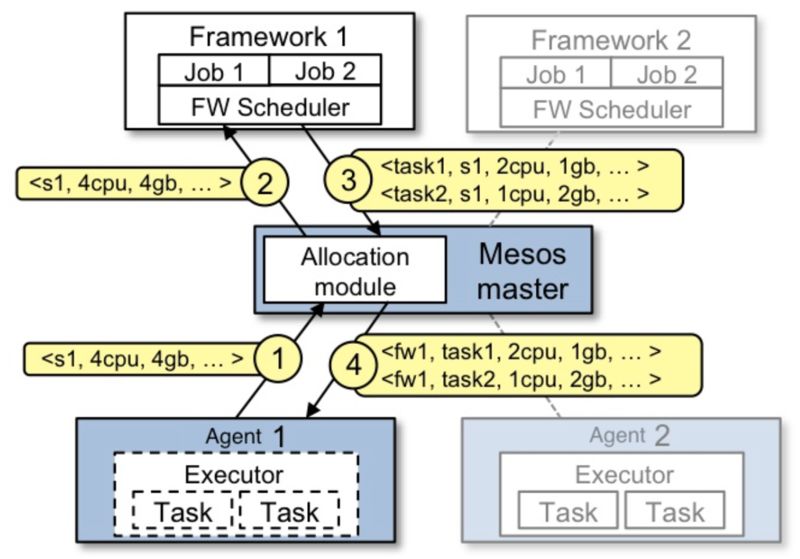
上述调度过程分为四个步骤:
- Agent1 向 Master 汇报节点当前的资源情况,Master 根据某种策略决定将 Resource Offer 给 Framework1。
- Master 将 Resource Offer 给 Framework1,即将 Agent1 的所有资源分配给 Framework1 使用。
- Agent1 回复 Master 的 Resource Offer,告诉 Master 将有两个任务运行在 Agent1 上,及各任务需要的资源情况。
- 最后,Master 将任务发给 Agent1,Agent1 会为 Framework 的 executor 分配合适的资源,Framework 的 executor 随即会启动两个任务。剩下的资源 Master 的 Allocation Module 会发 Resource Offer 给 Framework2。
这里着重需要关注两个问题:
- Mesos Master 发送 Resource Offer 的时候,并不知道 Framework 的资源需求,如何知道该把 Resource Offer 发给哪个 Framework?
- 在任务量比较大的时候,Framework 与 Master 通信的性能如何保证?
对于第一个问题,Mesos 提供了”reject offer”的机制,允许 Framework 暂时拒绝不满足其资源需求的 Resource Offer,具体拒绝的策略由各个框架自行决定。
因此在 Master 与 Framework 通信的问题上,Mesos 提供了”filter”和”rescinds”机制,前者可以只接收剩余资源量大于 L 的 Resource Offer,从而屏蔽掉部分流量,后者则允许某个 Framework 在一定的时间内没有为分配的资源返回对应的任务,则 Mesos 会回收其资源量,并将这些资源分配给其他 framework。
Mesos 调度采用 Dominant Resource Fairness(DRF) 策略,是一种支持多资源的 max-min fair 资源分配机制。在调度时先找出用户 (这里指具体的 Framework) 的支配性资源,DRF 将均衡所有用户的支配性资源,确保每个用户获取了最大比例的支配性资源。
2-2. Hadoop YARN 调度
Hadoop 的 YARN 模块也具有为计算任务分配资源的能力,相应地也具有调度能力。YARN 将应用的资源请求抽象为一个容器 (Container),具体的 Application Master 会接收容器,然后在容器中启动这个任务。对于 Hadoop 来说,任务注意分为两类: Map 和 Reduce。
注意: 这里的容器不是云计算中所说的具体容器技术,而是 Hadoop YARN 中一个抽象的资源的集合的概念。
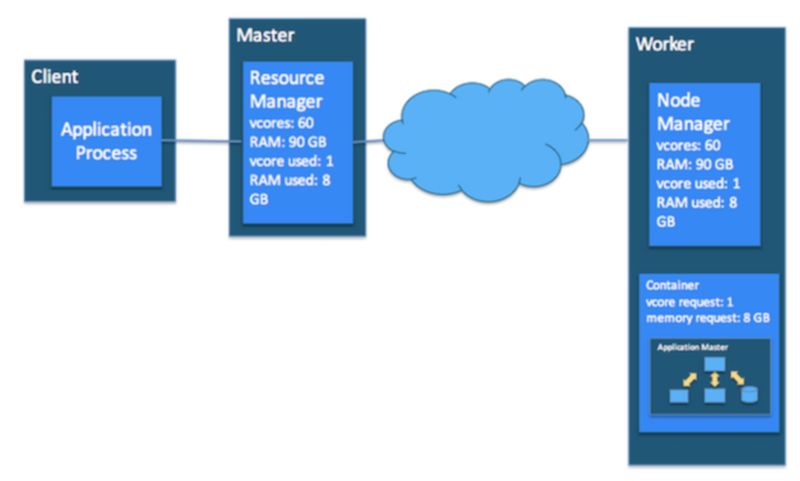
在 MapReduce 应用程序中,有多个 map 任务,每个任务都在集群中某个工作主机上的容器中运行。同样,还有多个 reduce 任务,每个还在运行主机上的容器中运行。
同时在 YARN 端,ResourceManager,NodeManager 和 ApplicationMaster 一起工作以管理集群的资源,并确保任务以及相应的应用程序完整地完成。
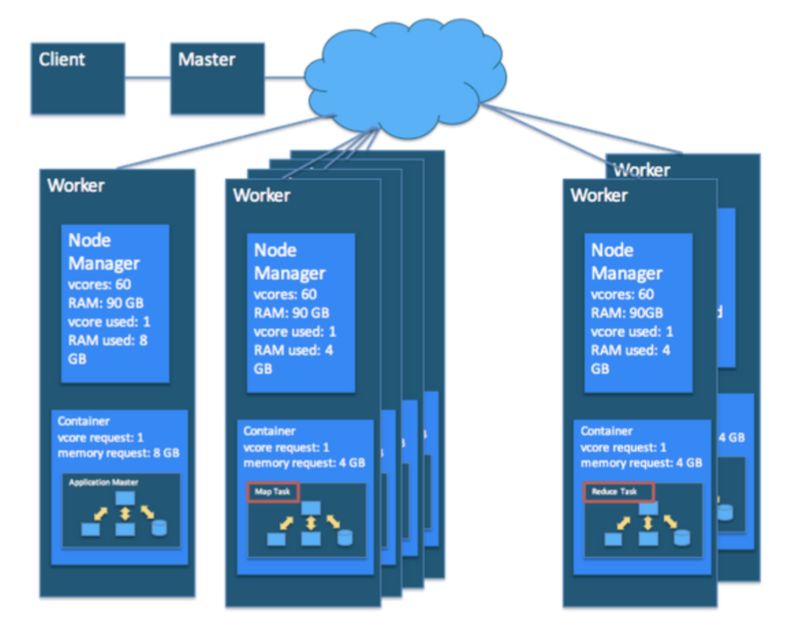
调度本身并不是一个新的概念,个人计算机可以有多个 CPU 核,每个核运行一个进程,但同时运行多达几百个进程。调度程序是操作系统的一部分,它将进程分配给 CPU 内核以在短时间内运行。
对于大规模的计算集群也一样,应用程序由群集上的多个任务 (通常在不同的主机上) 组成。集群调度程序基本上必须解决:
- 多租户: 在群集上,许多用户代表多个组织启动了许多不同的应用程序。 集群调度程序允许不同的工作负载同时运行。即调度时必须考虑应用发起者的身份,根据身份将任务分发到与用户身份对应的资源上。
- 可伸缩性: 集群调度程序需要扩展到运行许多应用程序的大型集群。这意味着增加群集的大小应该可以提高整体性能,而不会对系统延迟产生负面影响。调度程序需要确保在计算集群规模非常大的时候,依然可以高效地提供调度服务。
YARN 使用队列 (Queue) 在多个租户之间共享资源。当应用程序提交给 YARN 时,调度程序会将它们分配给队列。根队列是所有队列的父级。所有其他队列都是根队列或另一个队列 (也称为分层队列) 的子节点。队列通常与用户,部门或优先级相对应。Application Master 跟踪每个任务的资源需求并协调容器请求。这种方式允许更好的扩展,因为 RM/ 调度程序不需要跟踪在集群上运行的所有容器。
在 YARN 支持的调度程序中,公平调度 (Fair Scheduler) 是一个受欢迎的方式。在最简单的形式中,它在集群上运行的所有作业中公平地共享资源。

在实际的复杂调度场景中,还会有水平队列的形式出现,其实是上述队列的一种嵌套形式,即在队列的中还包含子队列,不同的子队列在父队列的权重的基础上有各自的权重设置,这里不再赘述。
2-3. Firmament 调度
Firmament 通过对调度算法的优化使得大规模计算集群的任务调度可以很好地在性能和准确之间找到平衡。Firmament 的设计出发点主要有如下两个:
- 良好的决策很重要: 对于关键服务应用程序,单个糟糕的调度决策可能会产生重大影响。
- 灵活的策略是关键: 不同的用户和应用程序具有不同的调度需求,因此根据工作负载定制调度策略非常重要。
既要保证单个决策的准确性,又要保证调度策略的灵活性,这对于调度程序的性能提出了很高的要求,而 Firmament 的基于流图的决策模式能够有效解决这个问题。这个调度程序的核心来自于 Google 的开发者,开发语言为 C++,目前作为一个开源项目,大家都可以共享自己的代码。Firmament 主要有以下三个特性:
- 通过对图进行最小成本优化,Firmament 根据调度策略为每个任务或容器找到最佳位置。
- 通过自定义底层图形并通过回调接口设置其边缘成本,用户可以自定义 Firmament 以应用自己的策略。
- Firmament 的增量最小成本,最大流量解算器甚至可以在 Google 规模 (12k 机器) 上做出快速的亚秒级调度决策。
- 最重要一点: Firmament 是全开源的。
Firmament 既可以独立工作,也可以在集群管理器中工作,如 Kubernetes 这样的容器管理集群,开源项目 Poseidon 正是出于这样的目的,将 Firmament 引入容器管理集群。
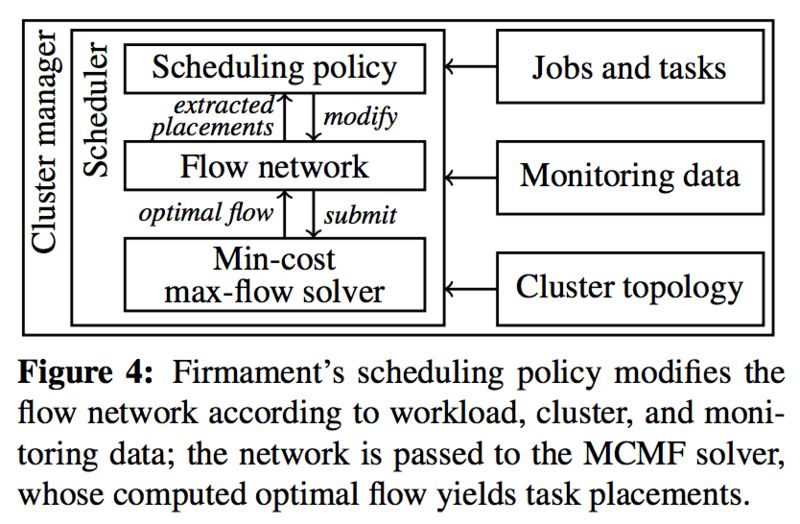
目前 Firmament 通过与容器管理集群结合,大幅度提升容器应用的调度管理能力,解决像 Kubernetes 原生调度器在 10K 节点时,性能急剧下降且对批处理作业任务支持不够完善的情况。Kubernetes 原生调度器采用的基于队列的模型,需要依赖于队列的性能,而在任务调度失败后,又再次回到队列等待继续调度,在对于计算密集型的任务调度时,对优先级、资源状态的共享支持都有待提升。
Firmament 采用的流图的机制,综合考虑了很多种影响调度结果的因素,比如 Rack,AZ,Region 等,甚至包括 SSD 硬件属性,综合这些因素考虑最小的成本,最大的流量来决定最终的调度结果。
2-4. Poseidon 主流应用场景
Posedion 会充当 Firmament 与 Kubernetes 之间的桥梁,即通过 Kubernetes API 获取对象的事件 (Event),然后结合资源使用状况,调用 Firmament 获取调度的结果,最终完成 Pod 调度的过程。
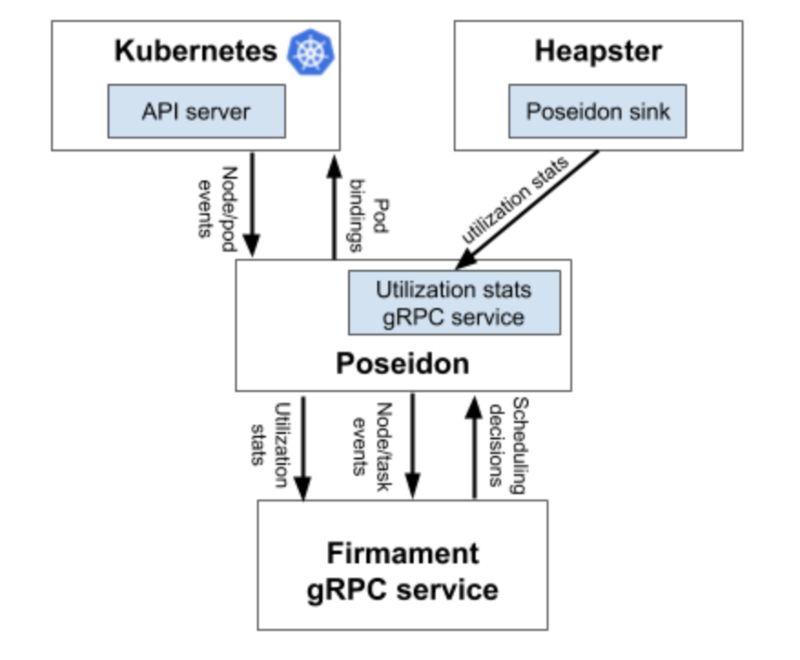
Firmament 可以理解为独立的核心算法模块,功能与原来的默认 scheduler 相同,都是根据目前资源情况,给出最佳的调度结果。Firmament 本身由一系列的复杂算法组成,但对于 Posedion 来说,这些细节可以不必关系,只需要了解输入和输出的标准数据结构就好。
在具体使用的时候,Firmament、Poseidon 及 heapster 等模块都是以 Deployment 形式部署在 Kubernetes 集群中的。在部署 Pod 的时候,我们知道 Kubernetes 支持多调度器机制,可以在 Pod 的定义中指定使用哪个调度器,具体示例如下:
我们在这里选择 posedion 作为其调度器,那么就可以通过 Firmament 算法来更高效、精细地决策 Pod 在哪个节点运行更合适,值得一提的是,其他的 Pod 如果不适合这些调度机制,完全可以选择默认调度器、甚至自定义的调度器,从而保证了平台的灵活性。
3. 任务调度框架的未来趋势
任务调度框架其实已经有很多,集中式和分布式的都有,一时间难以决定孰优孰劣,毕竟调度跟具体的业务场景息息相关。在未来,调度会更加精细化、更灵活,根据用户角色、业务类型、资源需求等等一系列复杂的因素,结合历史调度情况综合给出最终的结论。有些类似梯度递减形式的机器学习模型可以开始应用在调度上,已经有一些公司在做相关的探索,相信在未来大规模分布式调度会变得越来越重要。
[转]大规模集群任务调度

![[转]亿级流量架构系列专栏总结[2]架构可扩展性](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






