[转]亿级网关服务的落地
自从微服务概念以来,众多的软件架构在践行着这一优秀的设计理念。各自的系统在这一指导思想下收获了优雅的可维护性,但一方面也给接口调用提出了新的要求。比如众多的API调用急需一个统一的入口来支持客户端的调用。在这种情况下API GATEWAY诞生,我们将接入、路由、限流等功能统一由网关负责,各自的服务提供方专注于业务逻辑的实现,从而给客户端调用提供了一个稳健的服务调用环境。之后,我们在网关大调用量的情况下,还要保证网关的可降级、可限流、可隔离等等一系列容错能力。
1. 一、网关
这里说的网关是指API网关,直面意思是将所有API调用统一接入到API网关层,有网关层统一接入和输出。一个网关的基本功能有:统一接入、安全防护、协议适配、流量管控、长短链接支持、容错能力。有了网关之后,各个API服务提供团队可以专注于自己的的业务逻辑处理,而API网关更专注于安全、流量、路由等问题。
1-1. 1.1、单体应用
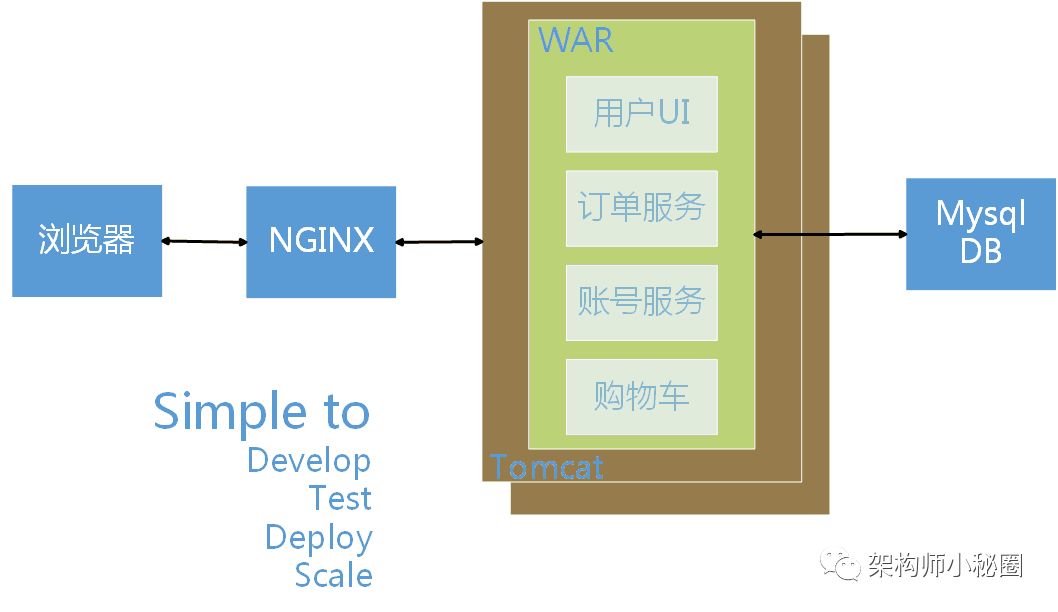
业务简单,团队组织很小的时候,我们常常把功能都集中于一个应用中,统一部署,统一测试,玩的不易乐乎。但随着业务迅速发展,组织成员日益增多。我们再将所有的功能集中到一个TOMCAT中去,每当更新一个功能模块的时候,势必要更新所有的程序。搞不好,还要牵一发动全身。实在难以维护。
1-2. 1.2、微服务
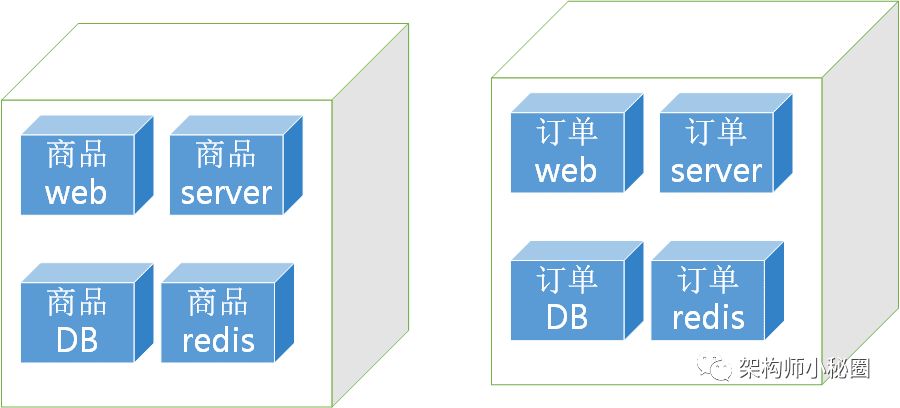
单体应用满足不了我们逐渐增长的扩展需求之后,微服务就出现了,它将原来集中于一体的比如商品功能、订单功能、用户功能拆分出去,各自有各自的自成体系的发布、运维等。这样就解决了在单体应用下弊端。
1-3. 1.3、API网关
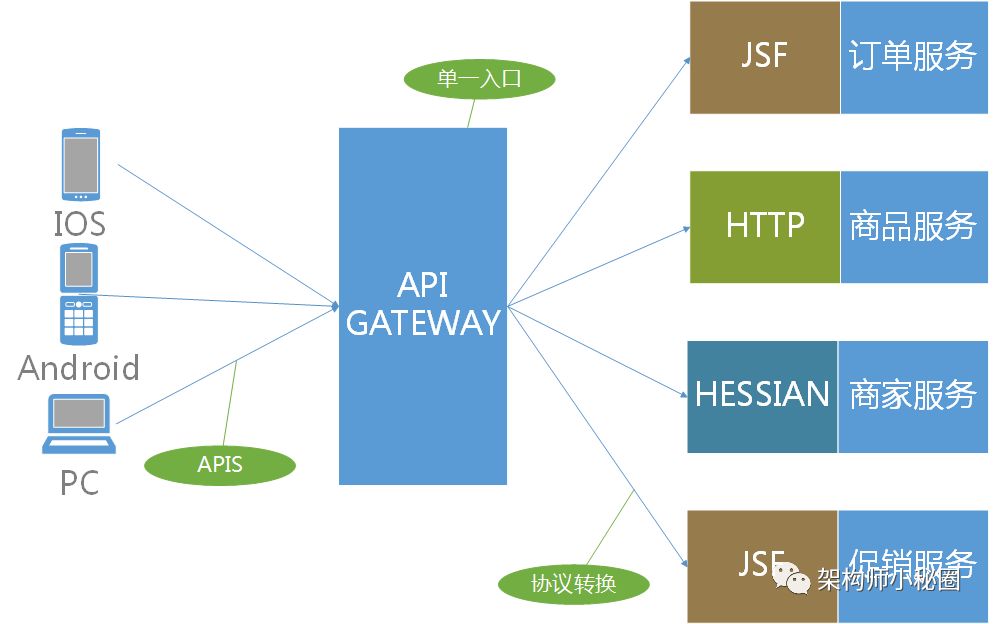
微服务后,那么原先客户端调用服务端的地方,就要有N多个URL地址,商品的、订单的、用户的。这个是就必须要有个统一的入口和出口,这种请情况下,我们的API GATEWAY就出现了。就很好的解决了微服务下客户端调用的问题。
1-4. 1.4、泛化调用
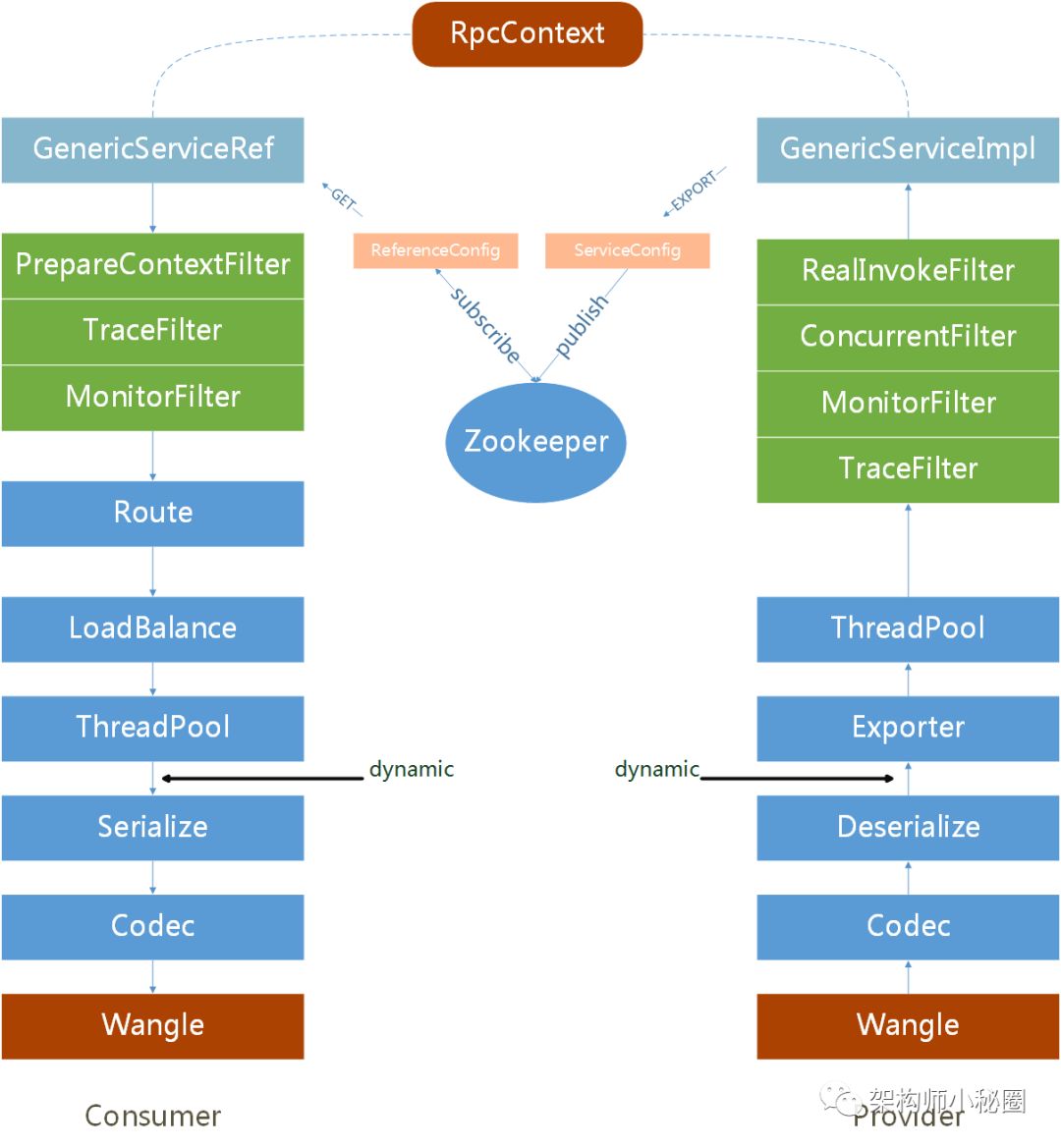
普通的RPC调用,我要拿到服务端提供的class或者jar包。但这样实在太重,更不好维护。不过,成熟的RPC框架都支持泛化调用,我们的网关就是基于这种泛化调用来实现的。服务端开放出来他们的API文档,我们拿到接口、参数、参数类型通过泛化调用到服务端程序。
public Object $invoke(String method, String[] parameterTypes, Object[] args);
2. 二、容错
容错,这个词的理解,直面意思就是可以容下错误,不让错误再次扩张,让这个错误产生的影响在一个固定的边界之内,“千里之堤毁于蚁穴”我们用容错的方式就是让这种蚁穴不要变大。那么我们常见的降级,限流,熔断器,超时重试等等都是容错的方法。
2-1. 2.1、抗量
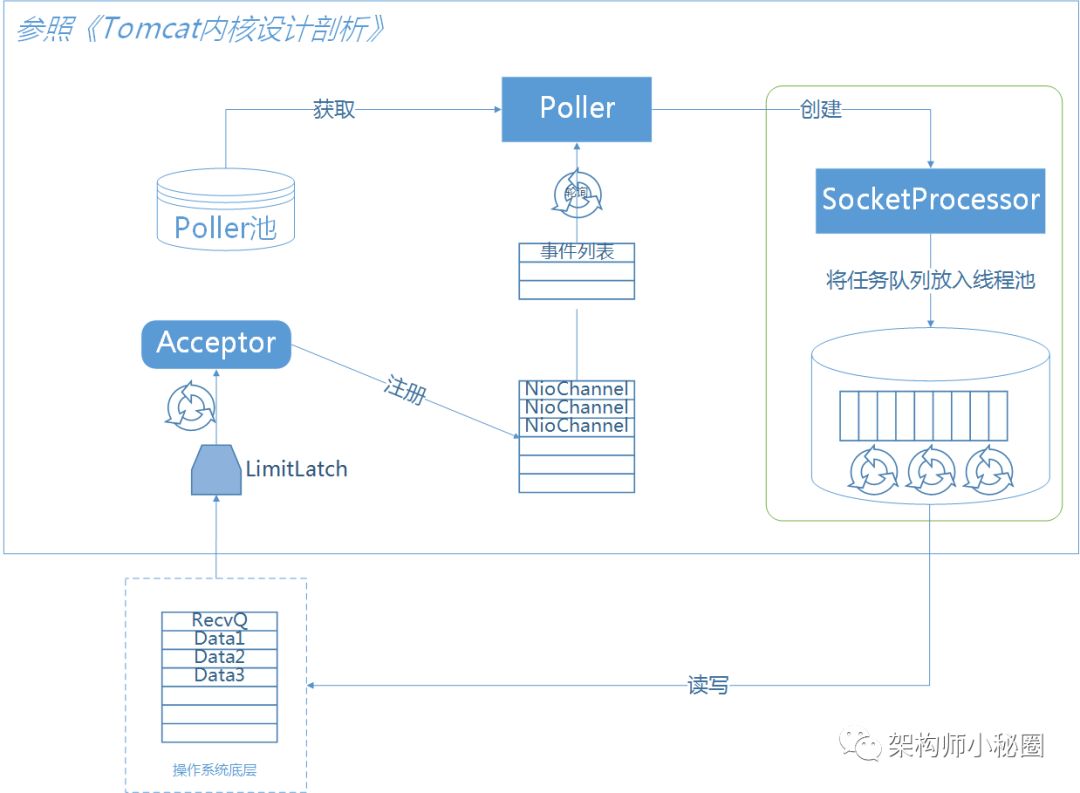
所谓抗量其实就是增大我们系统的吞吐量。所以容错的第一步就是系统要能抗量,没有量的情况下几乎用不到容错。我们的容器使用的是TOMCAT,在传统的BIO模型下,一请求一线程,在机器线程资源有限的情况下是没有办法来实现我们的目标。NIO给我们提供了这个机会,基于NIO的机制,利用较少的线程来处理更多的连接。连接多不可怕,通过调整机器的参数一台8c8g的机器,超过10w是不成问题的。tomcat的conector修改成nio之后我们再从代码层面又引入了Servlet3,他是从tomcat7以后支持的,nio是tomcat6以后就支持了。利用Servlet3的特性,所有的request和response都有tomcat的工作线程来处理,我们将业务逻辑异步到别的业务线程中去。异步环境下,可以提高单位时间内的吞吐量。所有的Servlet请求都是有tomcat的Executor线程池的线程处理的,也就是tomcat的工作线程。这些线程处理的时间越短越好,就会迅速的将线程归还给Executor线程池。现在Servlet支持异步后就能将耗时的操作比如有RPC请求的交给业务线程池来处理,使得tomcat工作线程可以立即归还给tomcat工作线程池。另外将业务异步处理之后,我们可以对业务线程池进行线程池隔离,这样避免了因一个业务性能问题影响了其它的业务。
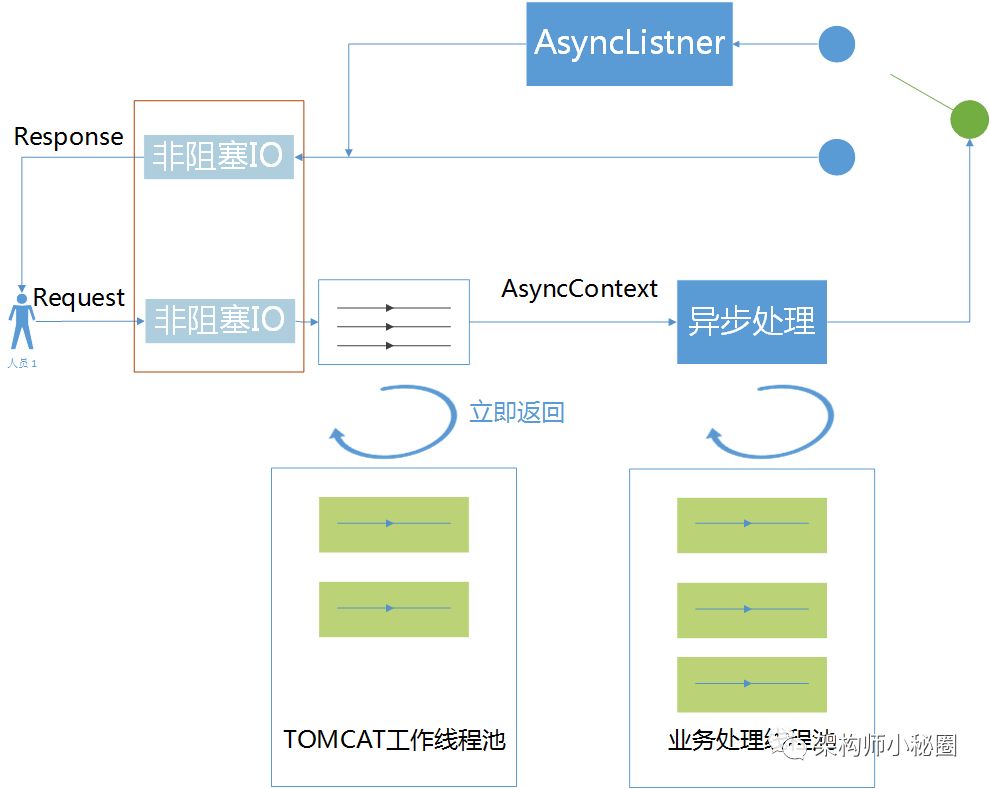
总结了一下异步的优势
1、可以用来做消息推送,通过nginx做代理,设置连接超时时间,客户端通过心跳探测。
2、提高吞吐量,就像上面说的。
3、请求线程和业务线程分开,从而可以通过业务线程池对业务线程做隔离。
关于Servlet3的异步原理与实践可以参看笔者以前写的这篇文章。http://www.jianshu.com/p/c23ca9d26f64
2-2. 2.2、脱离DB
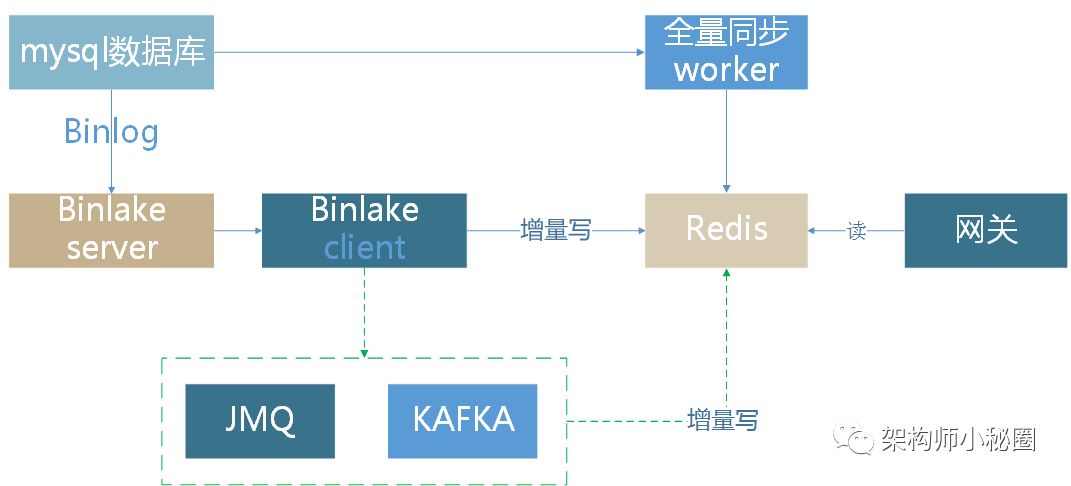
这里不是说DB的性能不行,分库分表,DB集群化之后,在一定量的情况下是没有问题的。但是,如果从抗量的角度说的话为何不使用REDIS呢,如果软件架构里面有一种银弹的话那么REDIS就是这种银弹。另外一个脱离DB的原因是,每当大促备战前夕我们一项重点的工作就是优化慢sql,但是它就像小强一样生命力是那样的顽强,杀不绝。如果有那么一个慢sql平时没有问题,比如一个查询大字段的sql,平是量小不能暴露问题,但是量一上来就是个灾难。再就是我们的网关,包括接入,分发,限流等等这些功能都应该是很轻的。所以我们就通过数据异构的方式把数据重新转载的redis中,而且是将数据持久化到redis里面去。当然使用redis的过程中也需要注意大key,大访问量下也能让集群趴下。还有一个很重要的原因,要说一下的,我们使用的DB是mysql,鉴于mysql的failover机制,生效时间总是要长于redis集群,还有就是因为DB切换的时候,常常伴随web应用服务器要重启,将原来的连接释放掉,以便使用新的数据库的连接。
2-3. 2.3、多级缓存
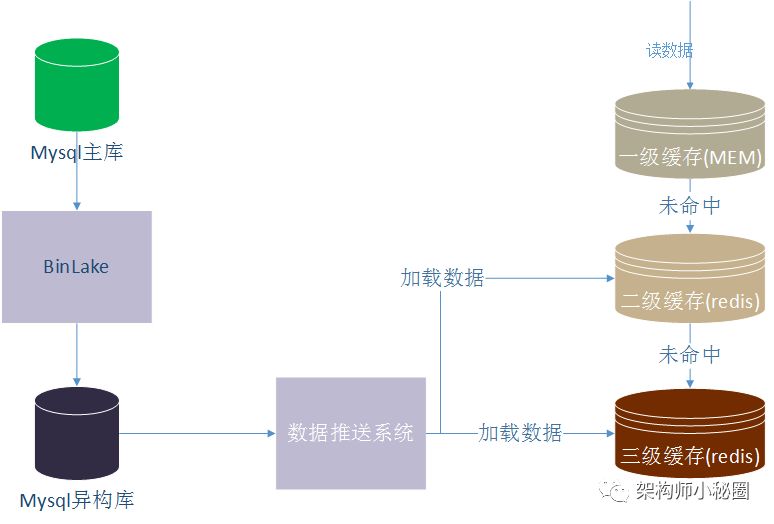
最简单的缓存就是查一次数据库然后将数据写入缓存比如redis中并设置过期时间。因为有过期失效因此我们要关注下缓存的穿透率,这个穿透率的计算公式,比如查询方法queryOrder(调用次数1000/1s)里面嵌套查询DB方法queryProductFromDb(调用次数300/s),那么redis的穿透率就是300/1000,在这种使用缓存的方式下,是要重视穿透率的,穿透率大了说明缓存的效果不好。还有一种使用缓存的方式就是将缓存持久化,也就是不设置过期时间,这个就会面临一个数据更新的问题。一般有两种办法,一个是利用时间戳,查询默认以redis为主,每次设置数据的时候放入一个时间戳,每次读取数据的时候用系统当前时间和上次设置的这个时间戳做对比,比如超过5分钟,那么就再查一次数据库。这样可以保证redis里面永远有数据,一般是对DB的一种容错方法。还有一个就是真正的让redis做为DB使用。就是图里面画的通过订阅数据库的binlog通过数据异构系统将数据推送给缓存,同时将将缓存设置为多级。可以通过使用jvmcache作为应用内的一级缓存,一般是体积小,访问频率大的更适合这种jvmcache方式,将一套redis作为二级remote缓存,另外最外层三级redis作为持久化缓存。
2-4. 2.4、超时与重试
超时与重试机制也是容错的一种方法,凡是发生RPC调用的地方,比如读取redis,db,mq等,因为网络故障或者是所依赖的服务故障,长时间不能返回结果,就会导致线程增加,加大cpu负载,甚至导致雪崩。所以对每一个RPC调用都要设置超时时间。对于强依赖RPC调用资源的情况,还要有重试机制,但是重试的次数建议1-2次,另外如果有重试,那么超时时间就要相应的调小,比如重试1次,那么一共是发生2次调用。如果超时时间配置的是2s,那么客户端就要等待4s才能返回。因此重试+超时的方式,超时时间要调小。这里也再谈一下一次PRC调用的时间都消耗在哪些环节,一次正常的调用统计的耗时主要包括:
①调用端RPC框架执行时间 + ②网络发送时间 + ③服务端RPC框架执行时间 + ④服务端业务代码时间。调用方和服务方都有各自的性能监控,比如调用方tp99是500ms,服务方tp99是100ms,找了网络组的同事确认网络没有问题。那么时间都花在什么地方了呢,两种原因,客户端调用方,还有一个原因是网络发生TCP重传。所以要注意这两点。
RPC耗时详细内容可以参看笔者写的另外一篇文章http://www.jianshu.com/p/f6e3806ae141
2-5. 2.5、熔断
熔断技术可以说是一种“智能化的容错”,当调用满足失败次数,失败比例就会触发熔断器打开,有程序自动切断当前的RPC调用,来防止错误进一步扩大。实现一个熔断器主要是考虑三种模式,关闭,打开,半开。各个状态的转换如下图。
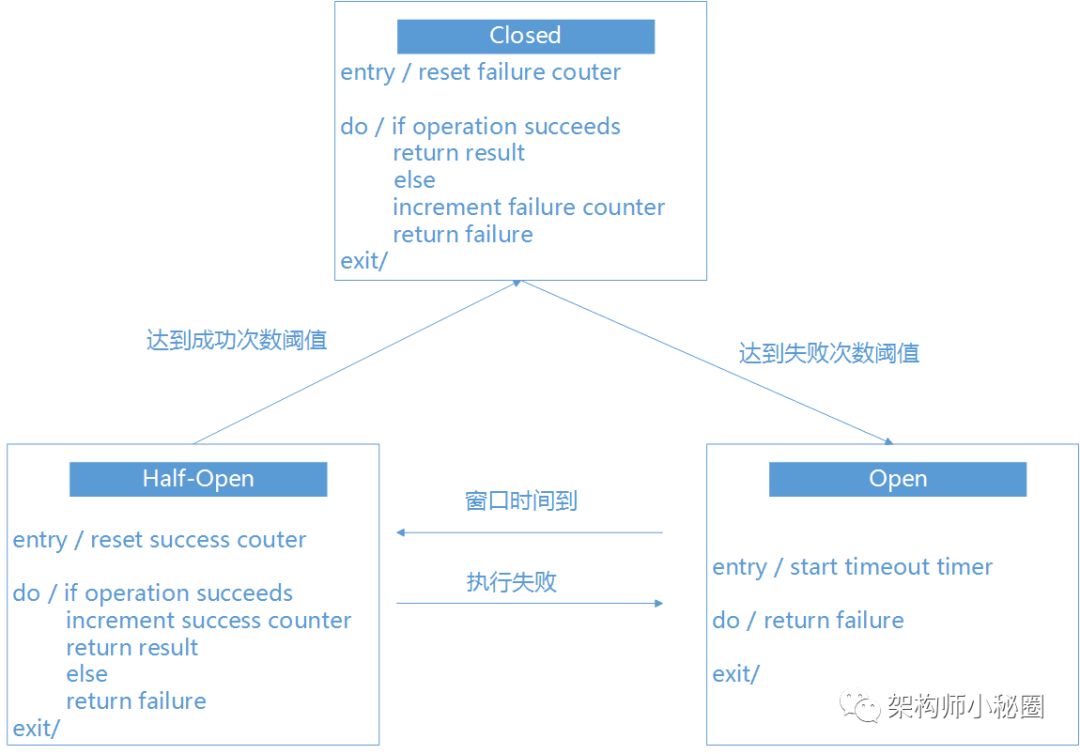
那么了解了熔断器的状态机制,我们可以自己来实现一个熔断器。当然也可以使用开源的解决方案比如Hystrix中的breaker。下图是一个熔断器打开关闭的示意图。
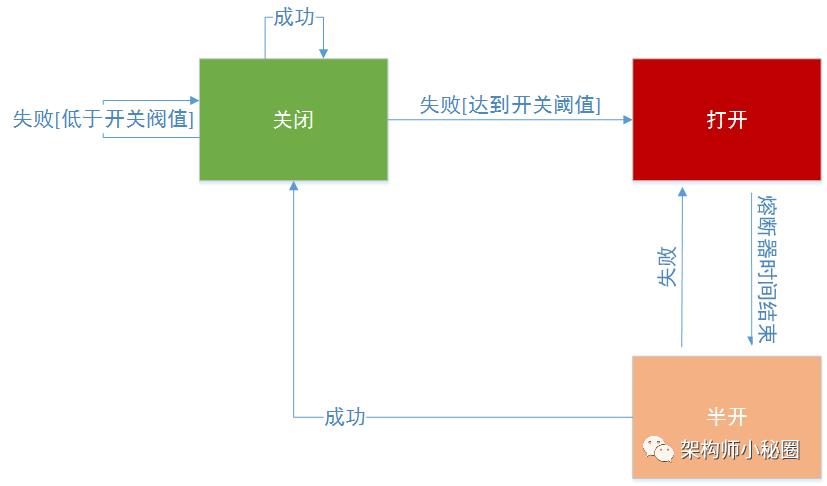
这里要谈的是熔断器的使用注意项。我们在处理异常的时候,要根据具体的业务情况来决定处理方式,比如我们调用商品接口,对方只是临时做了降级处理,那么作为网关调用就要切到可替换的服务上来执行或者获取托底数据,给用户友好提示。还有要区分异常的类型,比如依赖的服务崩溃了,这个可能需要花费比较久的时间来解决。也可能是由于服务器负载临时过高导致超时。作为熔断器应该能够甄别这种异常类型,从而根据具体的错误类型调整熔断策略。增加手动设置,在失败的服务恢复时间不确定的情况下,管理员可以手动强制切换熔断状态。最后,熔断器的使用场景是调用可能失败的远程服务程序或者共享资源。如果是本地缓存本地私有资源,使用熔断器则会增加系统的额外开销。还要注意,熔断器不能作为应用程序中业务逻辑的异常处理替代品。
关于熔断的原理与实践可以参照这篇文章http://www.jianshu.com/p/14958039fd15
2-6. 2.6、线程池隔离
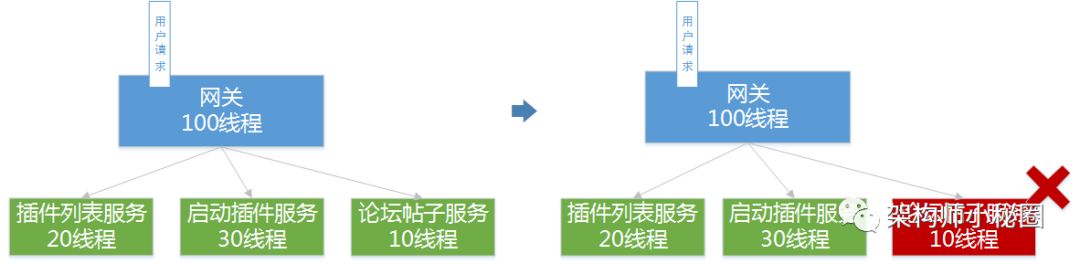
在抗量这个环节,Servlet3异步的时候,有提到过线程隔离。线程隔离的之间优势就是防止级联故障,甚至是雪崩。当网关调用N多个接口服务的时候,我们要对每个接口进行线程隔离。比如,我们有调用订单、商品、用户。那么订单的业务不能够影响到商品和用户的请求处理。如果不做线程隔离,当访问订单服务出现网络故障导致延时,线程积压最终导致整个服务CPU负载满。就是我们说的服务全部不可用了,有多少机器都会被此刻的请求塞满。那么有了线程隔离就会使得我们的网关能保证局部问题不会影响全局。
2-7. 2.7、降级、限流
关于降级限流的方法业界都已经有很成熟的方法了,比如FAILBACK机制,限流的方法令牌桶,漏桶,信号量等。这里谈一下我们的一些经验,降级一般都是由统一配置中心的降级开关来实现的,那么当有很多个接口来自同一个提供方,这个提供方的系统或这机器所在机房网络出现了问题,我们就要有一个统一的降级开关,不然就要一个接口一个接口的来降级。也就是要对业务类型有一个大闸刀。还有就是 降级切记暴力降级,什么是暴力降级的,比如把论坛功能降调,结果用户显示一个大白板,我们要实现缓存住一些数据,也就是有托底数据。限流一般分为分布式限流和单机限流,如果实现分布式限流的话就要一个公共的后端存储服务比如redis,在大nginx节点上利用lua读取redis配置信息。我们现在的限流都是单机限流,并没有实施分布式限流。
2-8. 2.8、网关监控与统计
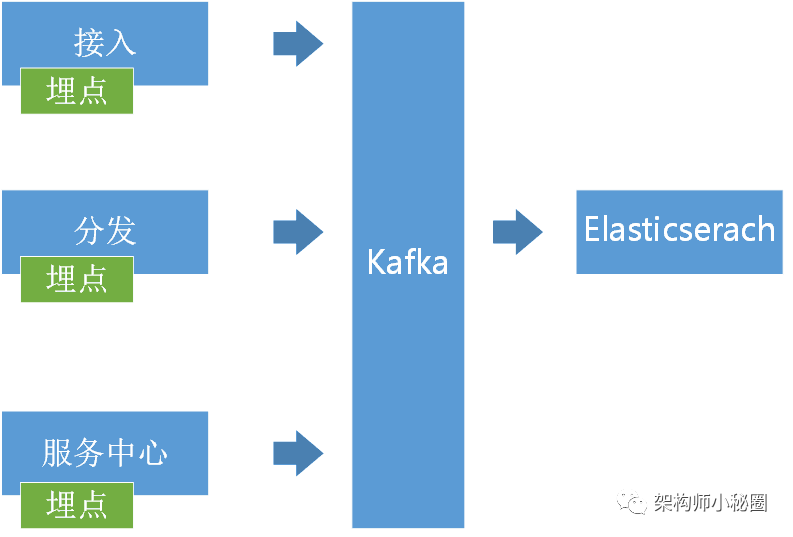
API网关是一个串行的调用,那么每一步发生的异常要记录下来,统一存储到一个地方比如elasticserach中,便于后续对调用异常的分析。鉴于公司docker申请都是统一分配,而且分配之前docker上已经存在3个agnet了,不再允许增加。我们自己实现了一个agnet程序,来负责采集服务器上面的日志输出,然后发送到kafka集群,再消费到elasticserach中,通过web查询。现在做的追踪功能还比较简单,这块还需要继续丰富。
3. 三、总结
网关基本功能有统一接入、安全防护、协议适配等。这篇文章里面我们并没有讲如何来实现这些基本的功能,因为现在有很多成熟的解决方案可以直接拿过来使用,比如spring cloud这种全家桶里面的很多组件,Mashape的API层Kong等等。我们更关注的是实现了这些网关的基本功能之后,如何保证一个网关的运行,在大访问量的情况下如何能更好的支持客户端的调用,在突发情况下又是如何及时的响应这种突然的异常,如何将错误最小化,防止级联故障。我们的重点关注的是网关容错方面的经验与实践。
参考资料
https://martinfowler.com/articles/microservices.html
https://tomcat.apache.org/tomcat-7.0-doc/config/http.html
http://www.cnblogs.com/davenkin/p/async-servlet.html
《Tomcat内核设计剖析》
[resource]亿级网关服务的落地
![[汇总]网关Gateway经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
