[Repost] Netflix Tips for High Availability, 125 Million subscribers

Over the past four years, Netflix has gone from less than 50 Million subscribers to 125 Million subscribers. While this kind of growth has caused us no shortage of scaling challenges, we actually managed to improve the overall availability of our service in that time frame. Along the way, we have learned a lot and now have a much better understanding of what it takes to make our system more highly available. But the news is not all good. The truth is that we learned many of our lessons the hard way: through heroics, through mad scrambles when things went wrong, and sometimes unfortunately through customer-facing incidents. Even though we haven’t figured everything out and still have many opportunities to improve our systems, we want to share some of the experience we have gained and the tips or best practices we derived. Hopefully some of you will take something away that will save you a wake-up call at 3am for a customer-facing incident.
At Netflix, we have built and use Spinnaker as a platform for continuous integration and delivery. Many of the best practices discussed here have been encoded into Spinnaker, so that they are easy to follow. While in this article we show how we internally encode the best practices in Spinnaker, the tips and best practices are more general and will help anyone make their systems be highly available.
1. Prefer regional deploys over global ones
Our goal is to provide the best customer experience possible. As a result, we aim to limit the blast radius of any change to our systems, validate the change, and then roll it out to a broader set of customers. More specifically, we roll out deployments to one AWS region at a time. This gives us an extra layer of safety in our production deployments. It also gives us the ability to quickly shift traffic away from affected customers, which is one of our most important remediation tools.
We also recommend verifying application functionality between each regional deployment, and avoid publishing during peak hours in the targeted region.
In Spinnaker, it’s straightforward to specify the region a deploy is targeted for.
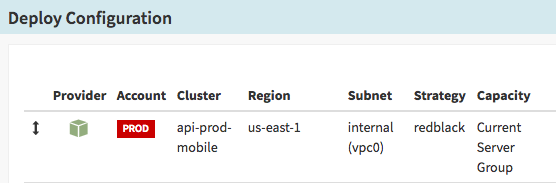
2. Use Red/Black deployment strategy for production deploys
In a Red/Black (also called Blue/Green) deployment a new version of an app (red) will start to receive traffic as soon as it passes health checks. Once the red version is healthy, the previous (black) version is disabled and receives no traffic. If a rollback is needed, making a change is as simple as enabling the previous version. For our services, this is a model that allows us to move fast and get back to a known good state if something goes wrong.
To accomplish a Red/Black deployment with Spinnaker, our engineers simply have to specify the strategy in their pipeline (and optionally set parameters on the strategy), and Spinnaker will take care of the rollout.
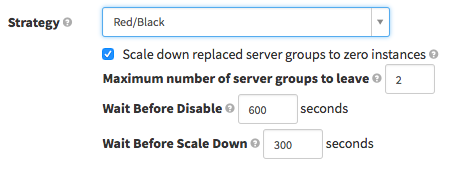
3. Use deployment windows
Whenever you deploy a new version of your app, there are two things to keep in mind: first, are you (and/or your colleagues) able to watch the impacts of the deployment and available to remediate if need be? And second, should there be a problem with your rollout, are you limiting the blast radius to the fewest customers possible?
Both of these reasons point to being mindful about when you deploy new software or new versions. In our case, our streaming traffic follows a relatively predictable pattern where most people stream in the evenings wherever they live. We recommend choosing deployment windows during working hours and at off-peak times for a selected region.
Spinnaker provides an interface to this through its pipeline UI. This makes it easy for you to specify the days and hours this pipeline can run.
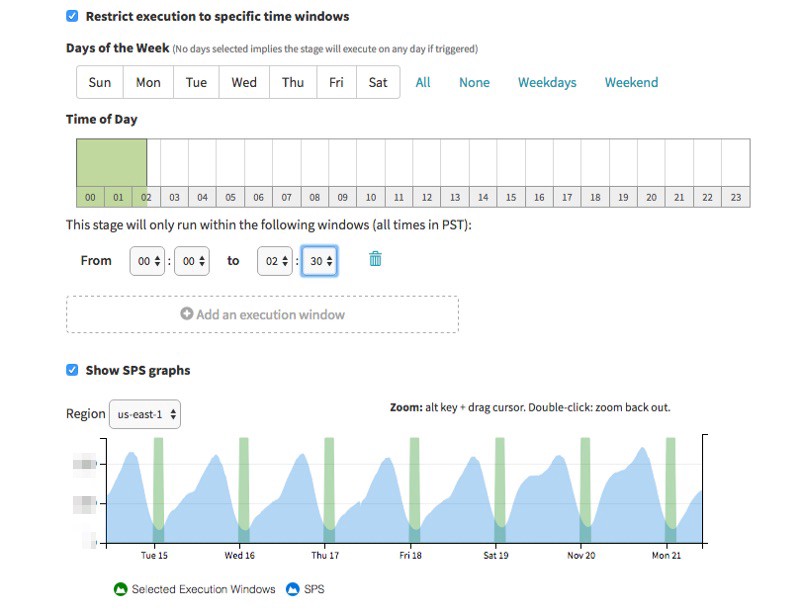
4. Ensure automatically triggered deploys are not executed during off-hours or weekends
Deployment windows also apply to automatically triggered events. Spinnaker permits cron expressions as pipeline triggers. This can be useful in reducing the hand-holding our users have to do and reduces mental overhead. But this can also be a risky strategy: it’s easy to fashion an aggressive cron expression that’ll execute a pipeline during off-hours or weekends, which may not be what was expected. No matter what kind of automation you use, ensure that any pipeline triggered automatically (e.g., by cron) can be run unattended.

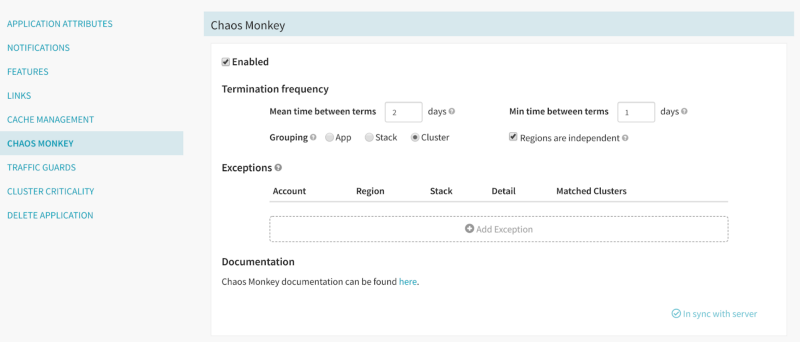
5. Enable Chaos Monkey
Chaos Monkey is built and open-sourced by Netflix and is part of our Chaos engineering suite of tools. Chaos Monkey unpredictably and automatically terminates instances in production. This serves as a forcing function to design services in a way that are resilient to single-instance failures. If they are not, Chaos Monkey will expose this vulnerability, so that service owners can fix it before it turns into a widespread customer-facing incident. At Netflix, our best practice is that all services in production should have Chaos Monkey enabled and owners of these services should detect no issues with Chaos Monkey terminating application instances.
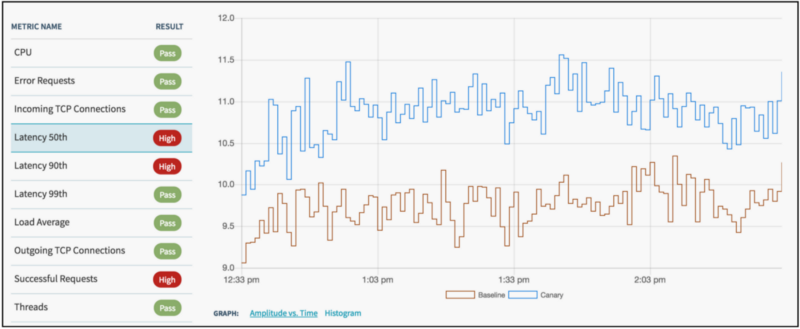
6. Use (unit, integration, smoke) testing and canary analysis to validate code before it is pushed to production
The key to moving fast is automatically validating new versions of software before they are deployed. Ideally, running all necessary suites of tests can be done without any manual intervention.
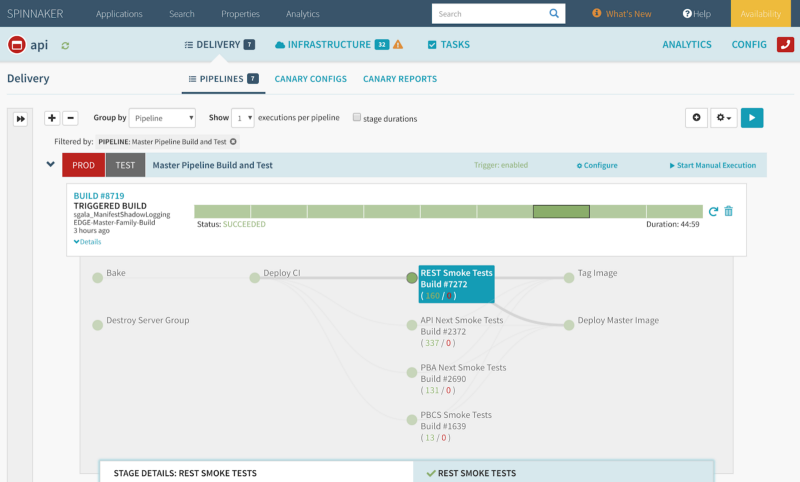
In addition, we recommend the use of canary analysis. Canary analysis is an effective means to validate live traffic against new changes to a service. We have built a tool internally at Netflix, Kayenta, which we have recently open-sourced. Kayenta easily integrates within Spinnaker; in combination with manual judgement, Kayenta is a final gate before full fledged production traffic.
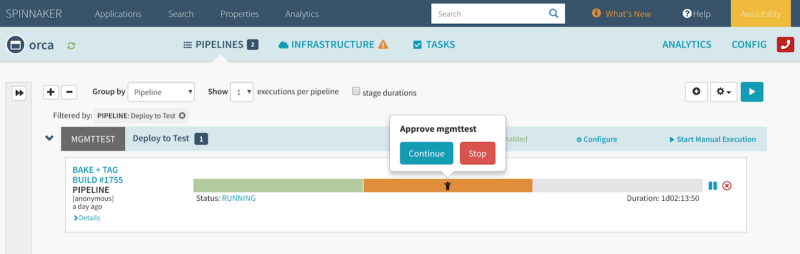
7. Use your judgement about manual intervention
Automate where possible, but use manual intervention where appropriate. For instance, it may be appropriate to check the results of a canary run before pushing a new version to production.
8. Where possible, deploy exactly what you tested to production
Now that you’ve done a lot of testing and validation of your new version, we highly recommend that you deploy to production exactly what you tested. In our case this means that we prefer to copy a validated image from a test environment rather than baking a new image in a production environment.
9. Regularly Review paging settings
Sometimes, the best thing you can do for the availability of your app is simple, but not obvious. When something goes wrong with your app, and more than likely it will at some point, it’s important that the people who can fix it will be paged. So review your paging settings, and do so regularly. This will help ensure that the right people will be called quickly in the case of an incident.
Internally, Spinnaker has a handy “Page owner” button, so it’s especially important that this information is up-to-date, so that we do not get a false sense of security of being able to reach the app owner but then finding out that the configuration is outdated when we most need it.
10. Know how to roll back your deploy quickly
Many of you will agree that even with solid testing, canaries, and other validation, sometimes something will be deployed to production that causes problems. Maybe it’s a rare bug exposed by a race condition that only gets triggered at scale. Whatever the case may be, it’s important that you know how to roll back to a good known state quickly if need be.
In Spinnaker, in the event of a production issue with a new version of your app, rollbacks are possible via the Rollback option under Server Group actions. Rollback will enable the ASG of your choice (usually the previous) and disable the faulty ASG. Spinnaker also supports creating rollback pipelines that can be executed upon pipeline failure or even triggered manually.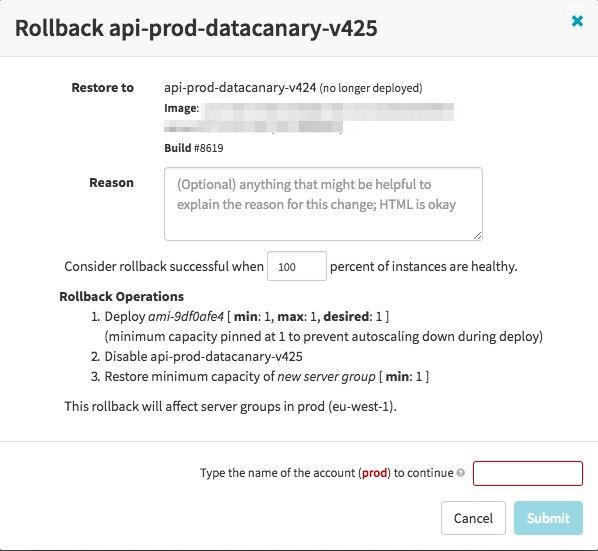
11. Fail a deployment when instances are not coming up healthy
Over the years, a few times we fell into a bad state when a deployment succeeded, and instances came up, but they weren’t healthy and were not in fact able to handle traffic appropriately. The “successful” deployment gave us a false sense of security which quickly vanished when a critical service wasn’t actually healthy, and requests were quickly stacking up and failing, sometimes causing a retry storm and all kinds of havoc. From these experiences, we learned how important it is to fail a deployment when instances come up, but aren’t healthy.
Spinnaker has a flexible means for associating instance health. When an instance is unhealthy, Spinnaker will note it accordingly; what’s more, unhealthy instances won’t receive traffic. In the event of all instances in an ASG being unhealthy, Spinnaker will fail a deployment. To make it easier for operators, Spinnaker also clearly marks instance state as coming up, starting, waiting for discovery, unhealthy, and healthy with different colors, as can be seen below.

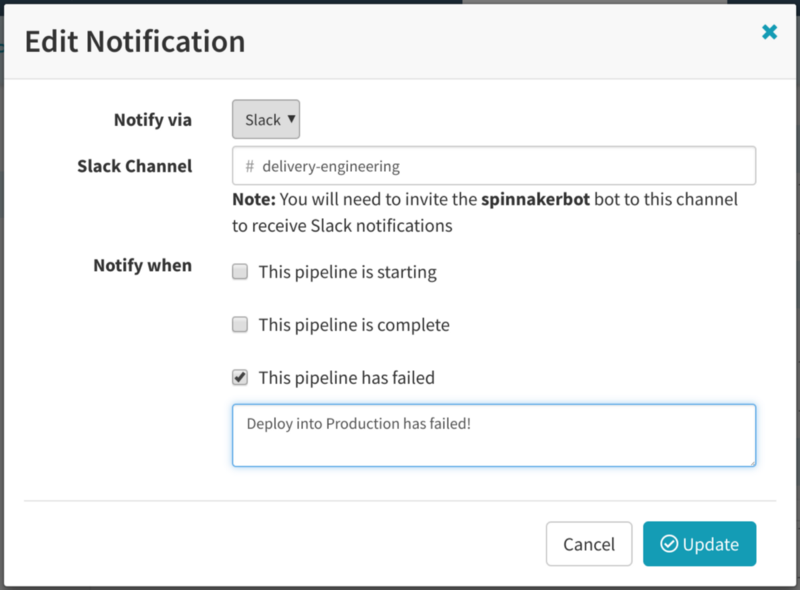
12. For automated deployments, notify the team of impending and completed deployments
Letting people know that a deployment has successfully gone into production is also recommended. This is critical for us operating successfully. Our best practice is to always watch your systems when changes are deployed. When something goes wrong, it’s important to know what has changed and when. For automated deployments, then, it is particularly important to notify the team so that they know to keep an eye on service health. We use Slack channels internally for notifications. In Spinnaker, Pipelines can notify any channel upon completion that operators want to notify.
13. Automate non-typical deployment situations rather than doing one-off manual work
Every engineer has written one-off scripts for non-typical situations. And many have had situations where those “one-off” situations happen again, and now the rest of the team doesn’t know what the one engineer did in their script that was intended to run once and be thrown away!
Pipelines are an effective means for automating any series of steps, even those steps not executed day-to-day. One example is fashioning a pipeline for an emergency push where parameters are provided to control conditional execution such as skipping deployment windows.
Don’t forget to regularly test your non-typical (and typical) deployment pipelines in non-critical situations!
14. Use preconditions to verify expected state
We all operate in a world where systems change around us frequently. At Netflix, our hundreds of microservices change on an ongoing basis. Making assumptions, for instance about the state of other systems, can be dangerous. Learning from our own mistakes, we now use preconditions to ensure that assumptions are still valid when we deploy new code or make other changes. This is particularly important for pipelines that execute of long periods of time (possibly from a delay in manual judgement and/or deployment windows). Using precondition stages can verify expected state before potentially destructive actions.
15. Conclusion
This post summarizes a variety of tips and best practices that we have accumulated over the years at Netflix, often learning from our own mistakes. Our approach is to build tooling around these best practices whenever possible, because we have found that best practices are often followed when it’s easy to “fall into the pit of success” — when manual toil, which is brittle and unpleasant, is kept to a minimum.
Our goal is to always improve the availability of our service. For us, this means keeping the human in the loop when manual judgement is really needed, but not otherwise. By doing this, we target our engineers’ time towards those tasks that improve availability, while also freeing them up to focus on other things when their involvement is not needed.
![[汇总]高可用经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






