[repost]Introducing AthenaX, Uber Engineering’s Open Source Streaming Analytics Platform
Uber facilitates seamless and more enjoyable user experiences by channeling data from a variety of real-time sources. These insights range from in-the-moment traffic conditions that provide guidance on trip routes to the Estimated Time of Delivery (ETD) of an UberEATS order—and every metric in between.
The sheer growth of Uber’s business required an data analytics infrastructure capable of streaming a wide range of insights captured from across the world and at all times, such as city-specific market conditions to global financial estimations. With more than one trillion real-time messages passing through our Kafka infrastructure every single day, the platform needed to be (1) easily navigable by all users regardless of technical expertise, (2) scalable and efficient enough to analyze real-time events, and (3) robust enough to continuously support hundreds if not thousands of critical jobs.
We built and open sourced AthenaX, our in-house streaming analytics platform, to satisfy these needs and bring accessible streaming analytics to everyone. AthenaX empowers our users, both technical and non-technical, to run comprehensive, production-quality streaming analytics using Structured Query Language (SQL). SQL makes event stream processing easy—SQL describes what data to analyze and AthenaX determines how to analyze the data (e.g., by locating it or scaling out its computations). Our real-world experience shows that AthenaX enables users to bring large-scale streaming analytic workloads in production within a matter of hours compared to weeks.
In this article, we discuss why we built AthenaX, outline its infrastructure, and detail the various features of its platform that we have contributed back to the open source community.
1. The evolution of Uber’s streaming analytics platform
To better serve our users with actionable insights, Uber must be able to gauge app activity and the various external factors (e.g., traffic, weather, and major events) that affect it. In 2013, we built our first generation streaming analytics pipeline on top of Apache Storm. While effective, this pipeline only computed specific sets of metrics; at a very high level, this solution consumed real-time events, aggregated the results for multiple dimensions (e.g., geographical region, time range), and published them on a web page.
As we expanded our offerings, our need to stream analytics quickly and effectively became ever more important. In the case of UberEATS, real-time metrics such as customer satisfaction rates and sales enable restaurants to better understand the health of their business and the satisfaction of their customers, allowing them to optimize potential earnings. To compute these metrics, our engineers implemented their streaming analytics applications on top of Apache Storm or Apache Samza. More specifically, the applications projected, filtered, or joined multiple Kafka topics together to compute results, with the capability of scaling up to hundreds of containers.
These solutions, however, were not yet ideal. Users were either forced to implement, manage, and monitor their own streaming analytics applications, or were limited to fetching answers for a pre-defined sets of questions.
AthenaX sets out to address this dilemma and brings the best of both worlds by enabling users to build customized, production-ready streaming analytics using SQL. To meet the needs of Uber’s scale, AthenaX compiles and optimizes SQL queries down to distributed streaming applications that can process up to several million messages per second using only eight YARN containers. AthenaX also manages the applications end-to-end, including continuously monitoring their health, scaling them automatically based on the size of inputs, and gracefully recovering them from node failures or data center failovers.
In the next section, we detail how we built AthenaX’s robust, but flexible architecture.
2. Building streaming analytic applications with SQL
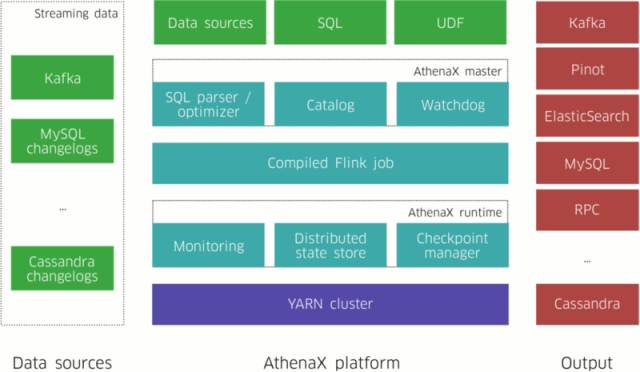
The lessons we learned in this evolution led us to AthenaX, the current generation of Uber’s streaming analytic platform. The key feature of AthenaX is that users can specify their streaming analytics using only SQL, and then AthenaX executes them efficiently. AthenaX compiles queries down to reliable, efficient, distributed applications, and manages the full lifecycle of the application, allowing users to focus solely on their business logic. As a result, users of all technical levels can run their streaming analytics applications in production in span of mere hours regardless of scale.
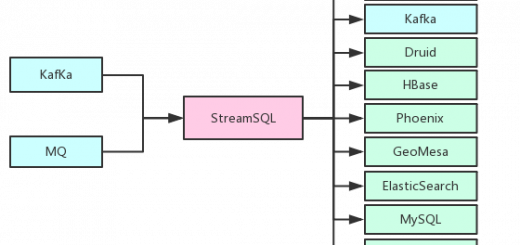
As depicted in Figure 1, above, an AthenaX job takes in various data sources as input, performs the required processing and analysis, and produces outputs to different types of end points. AthenaX’s workflow follows the steps below:
- Users specify a job in SQL and submit it to the AthenaX master.
- The AthenaX master validates the query and compiles it down to a Flink job.
- The AthenaX master packages, deploys, and executes the job in the YARN cluster. The master also recovers the jobs in the case of a failure.
- The job starts processing the data and produces results to external systems (e.g., Kafka).
In our experience, SQL is fairly expressive for specifying streaming applications. Take Restaurant Manager for example; in this use case, the following query counts the number of orders that a restaurant receives in the previous 15 minutes, depicted below:
Essentially the query scans through the ubereats_workflow Kafka topic, filters out irrelevant events, and aggregates the number of events over a 15-minute sliding window at a frequency of every one minute.
AthenaX also supports user-defined functions (UDFs) in the queries, thereby enriching their functionalities. For example, the following query showcasing trips to a specific airport uses the UDF to convert the longitudes and latitudes to the ID of the airport, described below:
A more complicated example is to compute the potential earnings of a given restaurant, as exemplified by Restaurant Manager:
The query joins the real-time events that comprise an order’s status and their details to calculate potential earnings.
Our experience has shown that more than 70 percent of streaming applications in production can be expressed in SQL. AthenaX applications can also exhibit different levels of data consistency guarantees—an AthenaX job can process real-time events at most once, at least once, or exactly once.
Next, we discuss the AthenaX query compilation workflow.
3. Compiling queries for distributed data flow programs
AthenaX leverages Apache Flink to implement the classic Volcano approach for compiling queries, all the way down to distributed data flow programs. Figure 2, below, depicts Restaurant Manager’s compilation process workflow:
- AthenaX parses the query and converts it into a logical plan (Figure 2(a)). A logical plan is a direct acyclic graph (DAG) that describes the semantics of the query.
- AthenaX optimizes the logical plan (Figure 2(b)). In this example, the optimizer bundles the projection and filtering with the tasks of scanning the streams. That way it minimizes the amount of data needed to be joined.
- The logical plan is translated to the corresponding physical plan. A physical plan is a DAG that consists of details such as locality and parallelism. These details describe how the query should be executed on physical machines. With this information, the physical plan is directly mapped to the final distributed data flow program (Figure 2(c)).
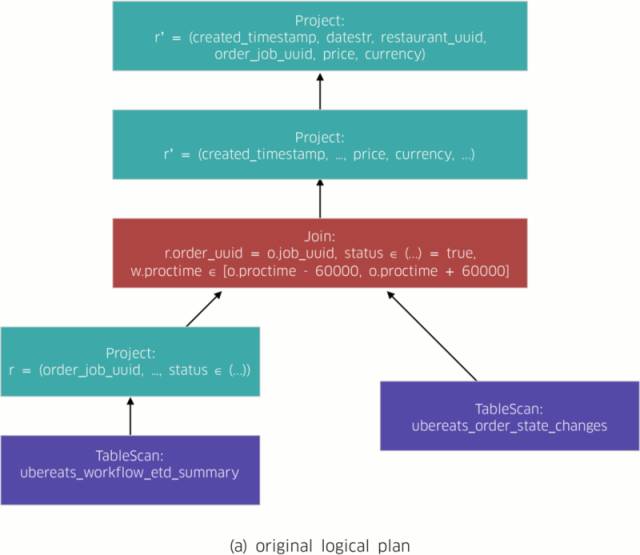
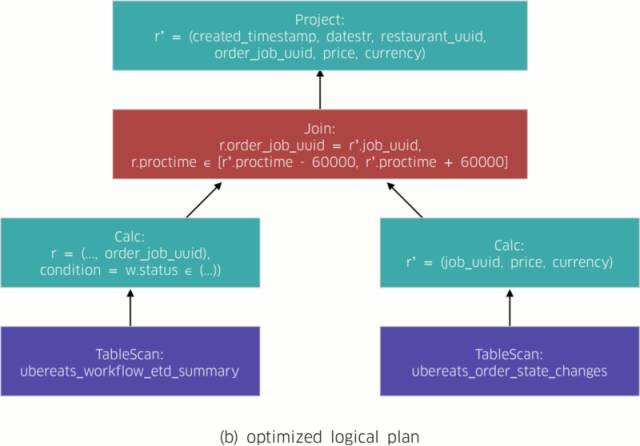
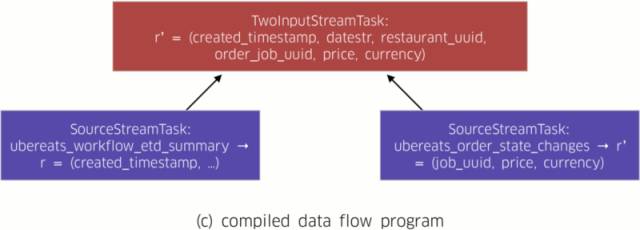
Once the compilation process is complete, AthenaX executes the compiled data flow program on a Flink cluster. The applications can process up to several millions of messages per seconds using eight YARN containers in production. The speed and scope of AthenaX’s processing capabilities ensures that the most up-to-date insights are gleaned, thereby facilitating better experiences for our users.
4. Using AthenaX in production at Uber
In production for six months, the current version of AthenaX runs more than 220 applications across multiple data centers, processing billions of messages per day. AthenaX serves multiple platforms and products including Michelangelo, UberEATS’ Restaurant Manager, and UberPOOL.
We have also implemented the following features to better scale the platform:
- Resource estimation and auto scaling. AthenaX estimates the number of vcores and memory based on the query and the throughput of input data. We also observed that the loads of the jobs varies during peak and off-peak hours. To maximize the cluster utilization, the AthenaX master continuously monitors the watermarks and garbage collection statistics of each job and restarts them if necessary. The fault tolerance model of Flink ensures that jobs will still produce the correct results.
- Monitoring and automatic failure recovery. Many AthenaX jobs serve as critical building blocks of the pipeline, and as a result, require 99.99 percent availability. The AthenaX master continuously monitors the health of all AthenaX jobs and recovers them gracefully in case of node failures, network failures, or even data center failovers.
[source]Introducing AthenaX, Uber Engineering’s Open Source Streaming Analytics Platform
![[汇总]日志系统](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






