[转]Twitter的Kafka迁移历程有哪些经验可以借鉴
1. Kafka 是什么?
Apache Kafka 是一个开源的分布式流式处理平台,可以高吞吐和低延迟地传输数据。Kafka 最初是在 LinkedIn 诞生,并于 2011 年开源,从那时起开始被社区广泛采用,包括很多其他公司在内,使其成为业界首选的事实上的实时消息系统。
Kafka 的核心就是一个基于分布式提交日志构建的 Pub/Sub 系统,提供了很多非常好的特性,例如水平可伸缩性和容错性。从那以后,Kafka 已经从消息系统发展成为一个成熟的流式处理平台。
2. 为什么要迁移?
你可能想知道为什么 Twitter 需要自己构建内部的消息传递系统。几年前,Twitter 也曾经使用过 Kafka(0.7 版本),但我们发现在某些方面它无法满足我们的要求——主要是在读取期间进行的 I/O 操作数量,而且缺乏持久化特性和复制机制。然而,随着时间推移,硬件和 Kafka 都已经走过了漫长的道路,这些问题现在都已经得到了解决。硬件的改进已经使 SSD 的价格足够便宜,这解决了我们之前在 HDD 上看到的随机读取的 I/O 问题,而且服务器 NIC 具有更多的带宽,就没有那么必要分离服务和存储层(EventBus 会这么做)。此外,较新版本的 Kafka 现在支持数据复制,提供了我们想要的持久性保证。
将 Twitter 的所有 Pub/Sub 用例迁移到一个全新的系统将是一个非常耗费成本的过程。所以,迁移到 Kafka 的决定绝对不是自然发生的,而是经过精心策划的,并且是由数据驱动的。迁移到 Kafka 的动机可归纳为两个方面:成本和社区。
3. 成 本
在向整个公司宣布迁移到 Kafka 之前,我们的团队花了几个月时间评估了 Kafka 在与 EventBus 类似的工作负载下的表现——持久写入、尾部读取、追赶读取和高扇出读取,以及一些灰色故障情况(例如减慢集群中的特定 Kafka 代理)。
在性能方面,我们看到 Kafka 的延迟显著降低,无论是根据消息创建时间戳来衡量吞吐量,还是根据消费者读取消息时间戳来衡量吞吐量。
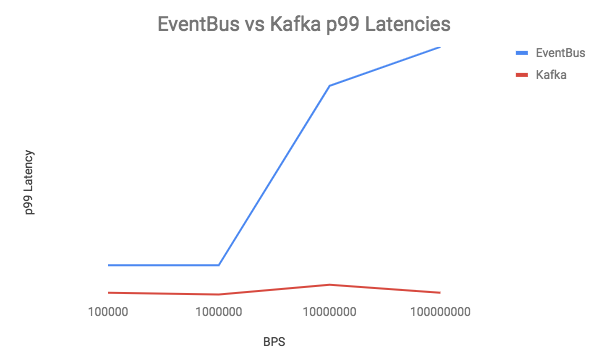 不同吞吐量下 EventBus 和 Kafka 之间的 P99 延迟比较
不同吞吐量下 EventBus 和 Kafka 之间的 P99 延迟比较这可以归因于几个因素,可能包括但不限于:
- 在 EventBus 中,服务层和存储层是分离的,这引入了额外的跳转(网络时间和通过 JVM 代理层的时间),而在 Kafka 中只有一个进程处理存储和请求服务(参见下图)。
- EventBus 在通过 fsync() 调用进行写入时会阻塞,而 Kafka 在后台依赖操作系统进行 fsync()。
- Kafka 使用零拷贝。
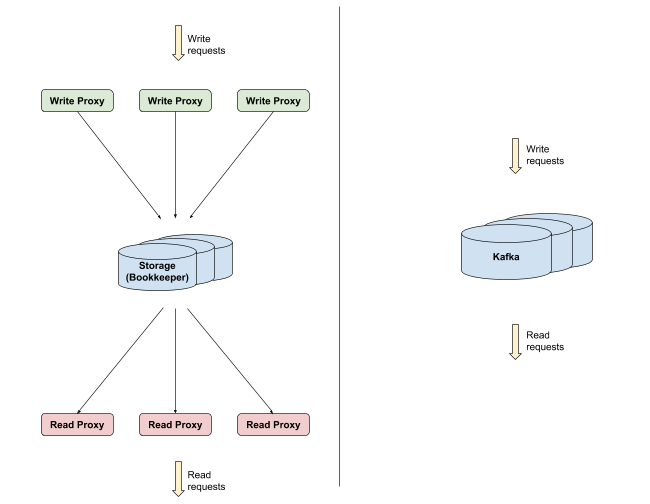 EventBus(左)和 Kafka(右)之间的架构比较
EventBus(左)和 Kafka(右)之间的架构比较从成本的角度来看,EventBus 需要服务层(针对高网络吞吐量进行了优化)和存储层(针对磁盘进行了优化)的硬件,而 Kafka 使用单台主机就可以提供这两者。因此,EventBus 需要更多的机器来提供与 Kafka 相同的工作负载。对于单个消费者,我们节省了 68%的资源,对于拥有多个消费者的案例,我们节省了 75%的资源。但有一个问题是,对于严重依赖带宽的工作负载(非常高的扇出读取),EventBus 理论上可能更有效,因为我们可以独立地扩展服务层。但是,我们在实践中发现,我们的扇出没有那么极端,分离服务层是不值得的。
4. 社 区
如上所述,Kafka 已经得到了广泛采用。我们可以利用数百名开发人员为 Kafka 项目所做出的贡献,他们修复错误、改进和添加新功能,这比 EventBus/DistributedLog 的八名工程师所做的要好得多。此外,Twitter 内部用户在 EventBus 中想要的很多功能已经在 Kafka 中提供了,例如流式处理库、至少一次 HDFS 管道,以及恰好一次性处理。
此外,当我们遇到客户端或服务器问题时,我们可以通过搜索网络轻松快速地找到解决方案,因为很可能其他人之前也遇到了同样的问题。另外,相比不太受欢迎的项目,受欢迎的项目的文档通常更加详尽。
采用 Kafka 等热门项目,并向这些项目回馈我们的贡献,这样做的另一个重要原因是为了招聘。一方面,通过向 Kafka 社区回馈贡献,可以让人们了解 Twitter 的工程。另一方面,由于新工程师已经熟悉了这些技术,因此为团队招聘工程师要容易得多。
5. 挑 战
尽管迁移到 Kafka 看起来非常棒,但过程并不是一帆风顺的。我们在这个过程中遇到了很多技术挑战和适应性挑战。
从技术角度来看,我们遇到的一些挑战包括配置调优和 Kafka Streams 库。与很多分布式系统一样,为了支持 Twitter 的实时性用例,需要对大量配置进行微调。在运行 Kafka Streams 时,我们发现 Kafka Streams 库中的元数据大小存在一些问题,这些问题是由于老版本的客户端在关闭后仍然保留元数据造成的。
另一方面,Kafka 与 EventBus 存在架构差异,我们不得不以不同的方式配置系统和调试问题。例如,如何在 EventBus(仲裁写入)和 Kafka(主从复制)中完成复制。写请求在 EventBus 中并行发送,而 Kafka 要求从节点仅在主节点收到写请求后才复制写请求。此外,两个系统之间的持久性模型是非常不同的—— EventBus 仅在数据持久化到磁盘时确认写入成功,而 Kafka 复制本身就具有持久性保证,并在将数据持久存储在磁盘上之前确认写入请求。我们不得不重新考虑我们对数据持久性的定义:数据的所有三个副本同时失败是不太可能的,因此没有必要在每个副本中同步数据来提供我们想要的持久性保证。
6. 前 行
在接下来的几个月里,我们计划将我们的用户从 EventBus 迁移到 Kafka,这将有助于降低运营 Twitter Pub/Sub 系统的成本,并使我们的用户能够使用 Kafka 提供的其他功能。我们将持续关注生态系统中的不同消息传递和流式处理系统,并确保我们的团队为我们的用户和 Twitter 做出正确的决策,即使这些决策很艰难。
https://blog.twitter.com/engineering/en_us/topics/insights/2018/twitters-kafka-adoption-story.html
[source]Twitter的Kafka迁移历程有哪些经验可以借鉴
![[转]Kafka 2.0升级实战!携程的经验有何可借鉴之处](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






