[总结]数据库解耦和拆分
随着业务越来越复杂,数据量越来越大,并发量越来越大,数据库的性能越来越低。好不容易找运维申请了两台机器,让DBA部署了几个实例,想把一些业务库拆分出来,却发现拆不出来,扩不了容,尴尬!
因为数据库强关联在一起,无法通过增加数据库实例扩容,就是一个耦合的典型案例。
1. 数据库解耦
场景还原
有一个公共用户数据库DB_USER,里面table_user存放了通用的用户数据:
在数据量比较小,并发量比较小,业务还没有这么复杂的时候,为了提高资源利用率(程序员才没有考虑什么资源利用率,更多的是图方便),业务A把用户个性化的数据也放在这个库里:
table_A(uid, A业务的个性化属性)
业务A有一个需求,即要展现用户公共属性,又要展现业务A个性化属性,程序员经常这么实现的:
初期关联查询没有任何问题,单条记录访问,命中索引,一次查询所有数据,简单高效。
如何产生各业务数据耦合?
通过join实现业务,导致通用表table_user和业务表table_A必须存在于一个数据库实例里。
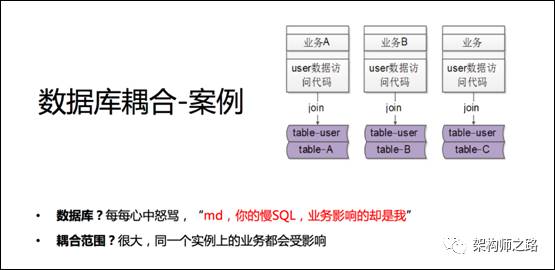
如果业务B也这么做,业务C也这么做,会导致公用业务,业务A,业务B,业务C都必须存在于一个数据库实例里。
会产生什么潜在问题呢?
假如A业务线上线了一个新功能,不小心进行了全表扫描,导致数据库CPU100%,数据库实例性能下降,由于实例共用,通用业务,业务B和业务C都会受影响。
即某个业务线的数据库性能急剧下降导致所有业务都受影响,这种耦合,历史总是惊人的相似:
- 业务B的大boss在群里首先发飙:“技术都干啥了,怎么系统挂了”
- 业务B的rd一脸无辜:“业务A上线了,所以我们挂了”
额,然而,这个理由,好像在大boss那解释不通…
- 业务B的大boss:“赶紧加几台机器,拆分开”
- 业务B的rd一脸无奈:“加机器加实例也扩容不了”
- 业务B的大boss对业务2的rd吼道“还想甩锅,拖出去祭天”
…
唉,加了几台机器,加了几个实例,然而并没有什么卵用,都耦合在一个实例里,完全扩不了容。
那,如何解除公共数据库与业务数据库的耦合?
第一步:公共数据访问下沉服务化
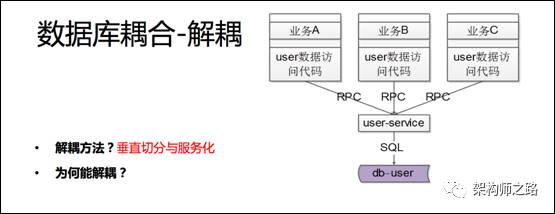
还是上面的例子,当公共的user数据访问服务化之后,依据服务化的原则:
- 业务层只能通过服务RPC接口访问数据
- 底层user库属于user服务私有
- 任何上游不允许跨过服务访问底层的user库
第二步:垂直拆分,个性化数据访问上浮
原来业务方:
- 通过join一次性获取通用的数据和个性化的业务数据数据
服务化+垂直拆分后,变成两次访问:
- 一次取得业务数据(业务可以直接调用自己的数据库,也可以自己做业务服务调用RPC接口)
- 一次取得共性数据(调用通用的RPC接口)
两种方式相比:
- 之前的方式其实业务代码可能会更简单一些,因为它是将这个业务逻辑放在了SQL语句中,但是导致数据库耦合在了一起
- 后面这种方式就是业务的代码会更复杂,会变成多次访问,将原来在SQL中进行的逻辑计算变成业务代码中的逻辑计算,但是数据库解耦了
业务复杂,数据量大,并发老大,对扩展性要求更高的架构,一定是后者。
此时各业务有自己的库,公共有公共的库:
- 早期:可以放在一个数据库实例里
- 后期:可以很容易地通过新增数据库实例,把user库或者业务A/B/C的库拆分出来,实现增加机器增加实例就实现扩容
个性业务数据访问垂直拆分,共性数据访问服务化下沉,只是一个很小的优化点,但对于数据库解耦却是非常的有效。
2. 数据库垂直拆分
一、缘起
当数据库的数据量非常大时,水平切分和垂直拆分是两种常见的降低数据库大小,提升性能的方法。假设有用户表:
水平切分是指,以某个字段为依据(例如uid),按照一定规则(例如取模),将一个库(表)上的数据拆分到多个库(表)上,以降低单库(表)大小,达到提升性能的目的的方法,水平切分后,各个库(表)的特点是:
(1)每个库(表)的结构都一样
(2)每个库(表)的数据都不一样,没有交集
(3)所有库(表)的并集是全量数据
二、什么是垂直拆分
垂直拆分是指,将一个属性较多,一行数据较大的表,将不同的属性拆分到不同的表中,以降低单库(表)大小,达到提升性能的目的的方法,垂直切分后,各个库(表)的特点是:
(1)每个库(表)的结构都不一样
(2)一般来说,每个库(表)的属性至少有一列交集,一般是主键
(3)所有库(表)的并集是全量数据
还是以上文提到的用户表为例,如果要垂直拆分,可能拆分结果会是这样的:
三、垂直切分的依据是什么
当一个表属性很多时,如何来进行垂直拆分呢?如果没有特殊情况,拆分依据主要有几点:
(1)将长度较短,访问频率较高的属性尽量放在一个表里,这个表暂且称为主表
(2)将字段较长,访问频率较低的属性尽量放在一个表里,这个表暂且称为扩展表
如果1和2都满足,还可以考虑第三点:
(3)经常一起访问的属性,也可以放在一个表里
优先考虑1和2,第3点不是必须。另,如果实在属性过多,主表和扩展表都可以有多个。
一般来说,数据量并发量比较大时,数据库的上层都会有一个服务层。需要注意的是,当应用方需要同时访问主表和扩展表中的属性时,服务层不要使用join来连表访问,而应该分两次进行查询:
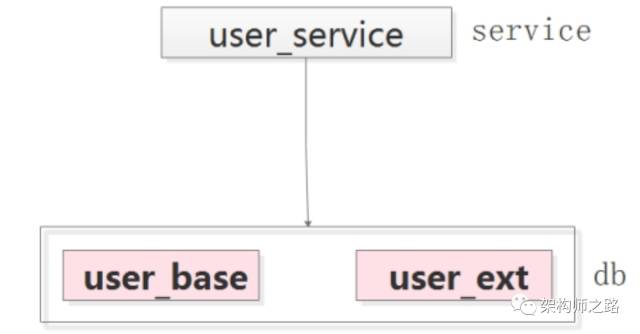
原因是,大数据高并发互联网场景下,一般来说,吞吐量和扩展性是主要矛盾:
(1)join更消损耗数据库性能
(2)join会让base表和ext表耦合在一起(必须在一个数据库实例上),不利于数据量大时拆分到不同的数据库实例上(机器上)。毕竟减少数据量,提升性能才是垂直拆分的初衷。
四、为什么要这么这么拆分
为何要将字段短,访问频率高的属性放到一个表内?为何这么垂直拆分可以提升性能?因为:
(1)数据库有自己的内存buffer,会将磁盘上的数据load到内存buffer里(暂且理解为进程内缓存吧)
(2)内存buffer缓存数据是以row为单位的
(3)在内存有限的情况下,在数据库内存buffer里缓存短row,就能缓存更多的数据
(4)在数据库内存buffer里缓存访问频率高的row,就能提升缓存命中率,减少磁盘的访问
举个例子就很好理解了:
假设数据库内存buffer为1G,未拆分的user表1行数据大小为1k,那么只能缓存100w行数据。
如果垂直拆分成user_base和user_ext,其中:
(1)user_base访问频率高(例如uid, name, passwd, 以及一些flag等),一行大小为0.1k
(2)user_ext访问频率低(例如签名, 个人介绍等),一行大小为0.9k
那边内存buffer就就能缓存近乎1000w行user_base的记录,访问磁盘的概率会大大降低,数据库访问的时延会大大降低,吞吐量会大大增加。
五、总结
(1)水平拆分和垂直拆分都是降低数据量大小,提升数据库性能的常见手段
(2)流量大,数据量大时,数据访问要有service层,并且service层不要通过join来获取主表和扩展表的属性
(3)垂直拆分的依据,尽量把长度较短,访问频率较高的属性放在主表里
The problems with single database arises when it starts getting huge. So it is required to partition it, to reduce search space, so that it can execute required actions faster.There are various partition strategies available eg: horizontal partitioning, vertical partitioning, hash based partitioning, lookup based partitioning. Horizontal, vertical scaling is different concept compare to these strategies.
- Horizontal partitioning : It splits given table/collection into multiple tables/collections based on some key information which can help in getting right table as horizontal partitioning will have multiple tables on different nodes/machines. eg: region wise users information.
- Vertical partitioning : It divide columns into multiple parts as mentioned in one of the above answers eg: columns related to user info, likes, comments, friends etc in social networking application.
- Hash based partitioning : It uses hash function to decide table/node, and take key elements as input in generating hash. If we change number of tables, it requires re arrangement of data which is costly. So there is a problem when you want to add more table/node.
- Lookup based partitioning : It uses a lookup table which helps in redirecting to different tables/node base on given input fields. We can easily add new table/node in this approach.
Horizontal scaling vs vertical scaling : When we design any application, we need to think of scaling as well. How are we going to handle huge amount of traffic in future? We need to think in terms of memory consumption, latency, cpu usage, fault tolerance, resiliency. Vertical scaling adds more resources eg: cpu, memory to single machine so that it can handle the in coming traffic. But there are limitation with this approach, you can’t add more resource than certain limit. Horizontal scaling allow in coming traffic to distribute across multiple nodes. It need to have load balancer at front which basically handle the traffic, and navigate traffic to any one node. Horizontal scaling allow you to add enough number of servers, but you would also need these many nodes.
[source]CA,给了数据库,给了机器,为啥也扩不了容?
![[转]跨库分页的四种方案](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






