[转]分布式系统的唯一id生成算法
如何实现全局唯一id呢?有以下几种方案。
1. (1-a)方案一:独立数据库自增id
这个方案就是说你的系统每次要生成一个id,都是往一个独立库的一个独立表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id。拿到这个id之后再往对应的分库分表里去写入。
比如说你有一个auto_id库,里面就一个表,叫做auto_id表,有一个id是自增长的。
那么你每次要获取一个全局唯一id,直接往这个表里插入一条记录,获取一个全局唯一id即可,然后这个全局唯一id就可以插入订单的分库分表中。
这个方案的好处就是方便简单,谁都会用。缺点就是单库生成自增id,要是高并发的话,就会有瓶颈的,因为auto_id库要是承载个每秒几万并发,肯定是不现实的了。
2. (1-b)基于数据库集群模式
起始值和自增步长MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。-
解决DB单点问题
-
不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
3. (1-c)基于数据库的号段模式
|
|
|
|
|
|
max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。4. (2)方案二:uuid
这个每个人都应该知道吧,就是用UUID生成一个全局唯一的id。
好处就是每个系统本地生成,不要基于数据库来了
不好之处就是,uuid太长了,作为主键性能太差了,不适合用于主键。
如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
5. (3)方案三:获取系统当前时间
这个方案的意思就是获取当前时间作为全局唯一的id。
但是问题是,并发很高的时候,比如一秒并发几千,会有重复的情况,这个是肯定不合适的。
一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。
你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,比如说订单编号:时间戳 + 用户id + 业务含义编码。
6. (4)方案四:snowflake算法的思想分析
snowflake算法,是twitter开源的分布式id生成算法。
其核心思想就是:使用一个64 bit的long型的数字作为全局唯一id,这64个bit中,其中1个bit是不用的,然后用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号。
给大家举个例子吧,比如下面那个64 bit的long型数字,大家看看

上面第一个部分,是1个bit:0,这个是无意义的
上面第二个部分是41个bit:表示的是时间戳
上面第三个部分是5个bit:表示的是机房id,10001
上面第四个部分是5个bit:表示的是机器id,1 1001
上面第五个部分是12个bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的id的序号,0000 00000000
- 1 bit:是不用的,为啥呢?
因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
- 41 bit:表示的是时间戳,单位是毫秒。
41 bit可以表示的数字多达2^41 – 1,也就是可以标识2 ^ 41 – 1个毫秒值,换算成年就是表示69年的时间。
- 10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上,也就是1024台机器。
但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
- 12 bit:这个是用来记录同一个毫秒内产生的不同id。
12 bit可以代表的最大正整数是2 ^ 12 – 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
简单来说,你的某个服务假设要生成一个全局唯一id,那么就可以发送一个请求给部署了snowflake算法的系统,由这个snowflake算法系统来生成唯一id。
这个snowflake算法系统首先肯定是知道自己所在的机房和机器的,比如机房id = 17,机器id = 12。
接着snowflake算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个64 bit的long型id,64个bit中的第一个bit是无意义的。
接着41个bit,就可以用当前时间戳(单位到毫秒),然后接着5个bit设置上这个机房id,还有5个bit设置上机器id。
最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成id的请求累加一个序号,作为最后的12个bit。
最终一个64个bit的id就出来了。
这个算法可以保证说,一个机房的一台机器上,在同一毫秒内,生成了一个唯一的id。可能一个毫秒内会生成多个id,但是有最后12个bit的序号来区分开来。
下面我们简单看看这个snowflake算法的一个代码实现,这就是个示例,大家如果理解了这个意思之后,以后可以自己尝试改造这个算法。
总之就是用一个64bit的数字中各个bit位来设置不同的标志位,区分每一个id。
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
6-1. snowflake算法的代码实现
6-2. snowflake算法一个小小的改进思路
其实在实际的开发中,这个snowflake算法可以做一点点改进。
因为大家可以考虑一下,我们在生成唯一id的时候,一般都需要指定一个表名,比如说订单表的唯一id。
所以上面那64个bit中,代表机房的那5个bit,可以使用业务表名称来替代,比如用00001代表的是订单表。
因为其实很多时候,机房并没有那么多,所以那5个bit用做机房id可能意义不是太大。
这样就可以做到,snowflake算法系统的每一台机器,对一个业务表,在某一毫秒内,可以生成一个唯一的id,一毫秒内生成很多id,用最后12个bit来区分序号对待。
补充:分布式 id 生成器
7. (5)基于Redis模式
Redis也同样可以实现,原理就是利用redis的 incr命令实现ID的原子性自增。redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF-
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。 -
AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
8. (6)百度(uid-generator)
uid-generator是由百度技术部开发,项目GitHub地址 https://github.com/baidu/uid-generatoruid-generator是基于Snowflake算法实现的,与原始的snowflake算法不同在于,uid-generator支持自定义时间戳、工作机器ID和 序列号 等各部分的位数,而且uid-generator中采用用户自定义workId的生成策略。uid-generator需要与数据库配合使用,需要新增一个WORKER_NODE表。当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的workId数据由host,port组成。uid-generator ID组成结构:workId,占用了22个bit位,时间占用了28个bit位,序列化占用了13个bit位,需要注意的是,和原始的snowflake不太一样,时间的单位是秒,而不是毫秒,workId也不一样,而且同一应用每次重启就会消费一个workId。参考文献
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
9. (7)美团(Leaf)
Leaf由美团开发,github地址:https://github.com/Meituan-Dianping/LeafLeaf同时支持号段模式和snowflake算法模式,可以切换使用。9-1. 号段模式
leaf_allocleaf_alloc;号段模式,配置对应的数据库信息,并关闭snowflake模式leaf-server 模块的 LeafServerApplication项目就跑起来了9-2. snowflake模式
Leaf的snowflake模式依赖于ZooKeeper,不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。10. (8)滴滴(Tinyid)
Tinyid由滴滴开发,Github地址:https://github.com/didi/tinyid。Tinyid是基于号段模式原理实现的与Leaf如出一辙,每个服务获取一个号段(1000,2000]、(2000,3000]、(3000,4000]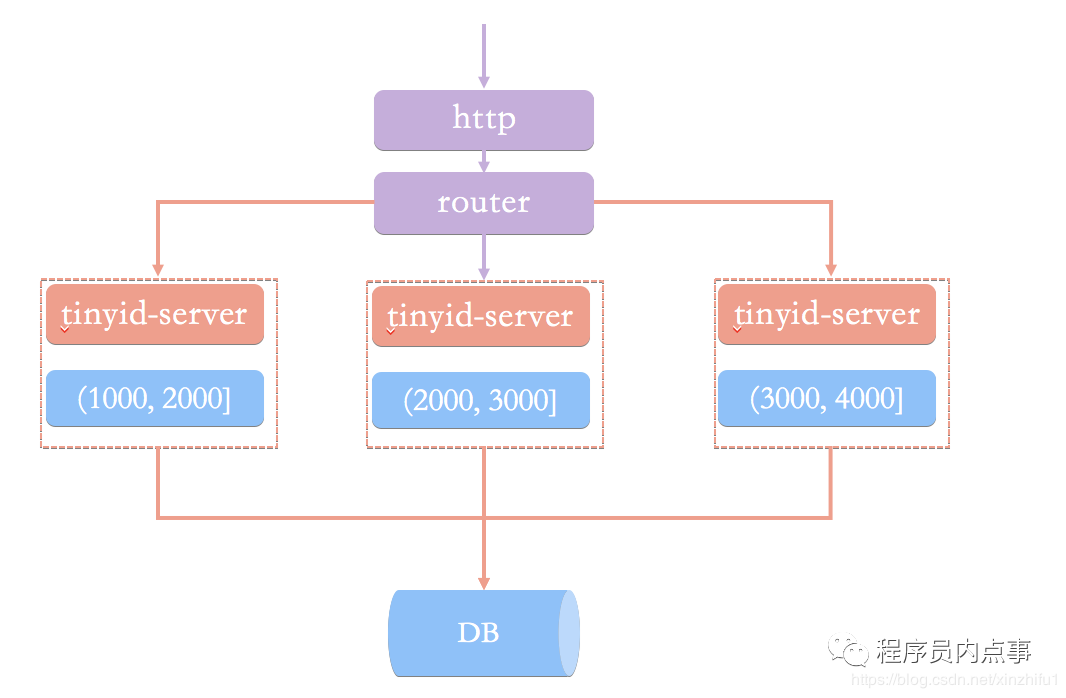
Tinyid提供http和tinyid-client两种方式接入10-1. Http方式接入
tinyid-server后测试10-2. Java客户端方式接入
test 、tinyid.token是在数据库表中预先插入的数据,test 是具体业务类型,tinyid.token表示可访问的业务类型
![[转]自增主键用完了怎么办?](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






