[转]千万级用户的大型网站如何设计其高并发架构
目录
(1)单块架构
(2)初步的高可用架构
(3)千万级用户量的压力预估
(4)服务器压力预估
(5)业务垂直拆分
(6)用分布式缓存抗下读请求
(7)基于数据库主从架构做读写分离
(8)总结
1.
(1)单块架构
一般一个网站刚开始建立的时候,用户量是很少的,大概可能就几万或者几十万的用户量,每天活跃的用户可能就几百或者几千个。
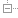
这个时候一般网站架构都是采用单体架构来设计的,总共就部署3台服务器,1台应用服务器,1台数据库服务器,1台图片服务器。
研发团队通常都在10人以内,就是在一个单块应用里写代码,然后写好之后合并代码,接着就是直接在线上的应用服务器上发布。很可能就是手动把应用服务器上的Tomcat给关掉,然后替换系统的代码war包,接着重新启动Tomcat。
数据库一般就部署在一台独立的服务器上,存放网站的全部核心数据。
然后在另外一台独立的服务器上部署NFS作为图片服务器,存放网站的全部图片。应用服务器上的代码会连接以及操作数据库以及图片服务器。如下图所示:
2. (2)初步的高可用架构
但是这种纯单块系统架构下,有高可用问题存在,最大的问题就是应用服务器可能会故障,或者是数据库可能会故障
所以在这个时期,一般稍微预算充足一点的公司,都会做一个初步的高可用架构出来。
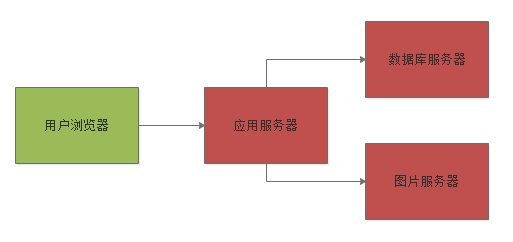
对于应用服务器而言,一般会集群化部署。当然所谓的集群化部署,在初期用户量很少的情况下,其实一般也就是部署两台应用服务器而已,然后前面会放一台服务器部署负载均衡设备,比如说LVS,均匀的把用户请求打到两台应用服务器上去。
如果此时某台应用服务器故障了,还有另外一台应用服务器是可以使用的,这样就避免了单点故障问题。如下图所示:
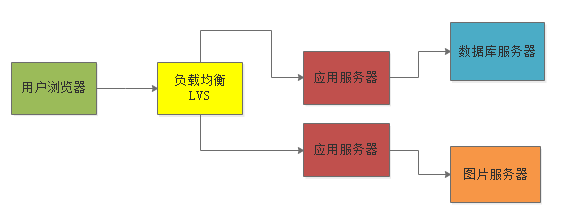
对于数据库服务器而言,此时一般也会使用主从架构,部署一台从库来从主库同步数据,这样一旦主库出现问题,可以迅速使用从库继续提供数据库服务,避免数据库故障导致整个系统都彻底故障不可用。如下图:
3. (3)千万级用户量的压力预估
这个假设这个网站预估的用户数是1000万,那么根据28法则,每天会来访问这个网站的用户占到20%,也就是200万用户每天会过来访问。
通常假设平均每个用户每次过来会有30次的点击,那么总共就有6000万的点击(PV)。
每天24小时,根据28法则,每天大部分用户最活跃的时间集中在(24小时 * 0.2)≈ 5小时内,而大部分用户指的是(6000万点击 * 0.8 ≈ 5000万点击)
也就是说,在5小时内会有5000万点击进来。
换算下来,在那5小时的活跃访问期内,大概每秒钟会有3000左右的请求量,然后这5小时中可能又会出现大量用户集中访问的高峰时间段。
比如在集中半个小时内大量用户涌入形成高峰访问。根据线上经验,一般高峰访问是活跃访问的2~3倍。假设我们按照3倍来计算,那么5小时内可能有短暂的峰值会出现每秒有10000左右的请求。
4. (4)服务器压力预估
大概知道了高峰期每秒钟可能会有1万左右的请求量之后,来看一下系统中各个服务器的压力预估。
一般来说一台虚拟机部署的应用服务器,上面放一个Tomcat,也就支撑最多每秒几百的请求。
按每秒支撑500的请求来计算,那么支撑高峰期的每秒1万访问量,需要部署20台应用服务。
而且应用服务器对数据库的访问量又是要翻几倍的,因为假设一秒钟应用服务器接收到1万个请求,但是应用服务器为了处理每个请求可能要涉及到平均3~5次数据库的访问。
按照3次数据库访问来算,那么每秒会对数据库形成3万次的请求。
按照一台数据库服务器最高支撑每秒5000左右的请求量,此时需要通过6台数据库服务器才能支撑每秒3万左右的请求。
图片服务器的压力同样会很大,因为需要大量的读取图片展示页面,这个不太好估算,但是大致可以推算出来每秒至少也会有几千次请求,因此也需要多台图片服务器来支撑图片访问的请求。
5. (5)业务垂直拆分
一般来说在这个阶段要做的第一件事儿就是业务的垂直拆分
因为如果所有业务代码都混合在一起部署,会导致多人协作开发时难以维护。在网站到了千万级用户的时候,研发团队一般都有几十人甚至上百人。
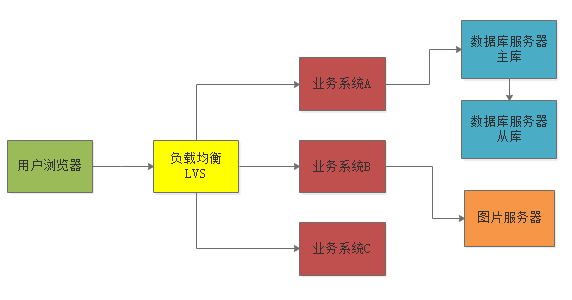
所以这时如果还是在一个单块系统里做开发,是一件非常痛苦的事情,此时需要做的就是进行业务的垂直拆分,把一个单块系统拆分为多个业务系统,然后一个小团队10个人左右就专门负责维护一个业务系统。如下图
6. (6)分布式缓存扛下读请求
这个时候应用服务器层面一般没什么大问题,因为无非就是加机器就可以抗住更高的并发请求。
现在估算出来每秒钟是1万左右的请求,部署个二三十台机器就没问题了。
但是目前上述系统架构中压力最大的,其实是数据库层面 ,因为估算出来可能高峰期对数据库的读写并发会有3万左右的请求。
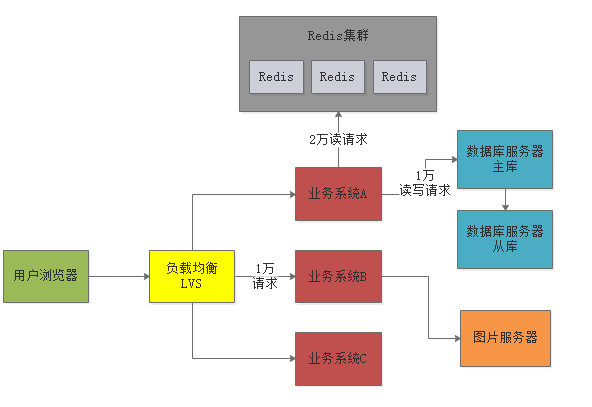
此时就需要引入分布式缓存来抗下对数据库的读请求压力了,也就是引入Redis集群。
一般来说对数据库的读写请求也大致遵循28法则,所以每秒3万的读写请求中,大概有2.4万左右是读请求
这些读请求基本上90%都可以通过分布式缓存集群来抗下来,也就是大概2万左右的读请求可以通过 Redis集群来抗住。
我们完全可以把热点的、常见的数据都在Redis集群里放一份作为缓存,然后对外提供缓存服务。
在读数据的时候优先从缓存里读,如果缓存里没有,再从数据库里读取。这样2万读请求就落到Redis上了,1万读写请求继续落在数据库上。
Redis一般单台服务器抗每秒几万请求是没问题的,所以Redis集群一般就部署3台机器,抗下每秒2万读请求是绝对没问题的。如下图所示:
7. (7)基于数据库主从架构做读写分离
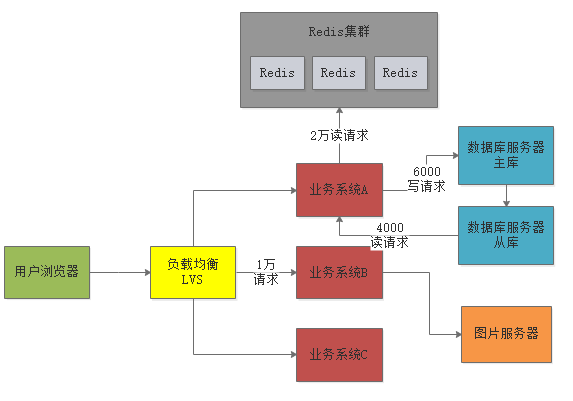
此时数据库服务器还是存在每秒1万的请求,对于单台服务器来说压力还是过大。
但是数据库一般都支持主从架构,也就是有一个从库一直从主库同步数据过去。此时可以基于主从架构做读写分离。
也就是说,每秒大概6000写请求是进入主库,大概还有4000个读请求是在从库上去读,这样就可以把1万读写请求压力分摊到两台服务器上去。
这么分摊过后,主库每秒最多6000写请求,从库每秒最多4000读请求,基本上可以勉强把压力给抗住。如下图:
(8)总结
本文主要是探讨在千万级用户场景下的大型网站的高并发架构设计,也就是预估出了千万级用户的访问压力以及对应的后台系统为了要抗住高并发,在业务系统、缓存、数据库几个层面的架构设计以及抗高并发的分析。
但是要记住,大型网站架构中共涉及的技术远远不止这些,还包括了MQ、CDN、静态化、分库分表、NoSQL、搜索、分布式文件系统、反向代理,等等很多话题,但是本文不能一一涉及,主要是在高并发这个角度分析一下系统如何抗下每秒上万的请求。
[source]千万级用户的大型网站,应该如何设计其高并发架构?
![[转]从单个服务器扩展到百万用户的系统](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)