![[转]小白都能看懂的Hadoop架构原理](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]小白都能看懂的Hadoop架构原理
Hadoop 是目前大数据领域最主流的一套技术体系,包含了多种技术,例如 HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统)等等。 有些朋友可能听说过 Hadoop,但是却不太清楚它到底是个什么东西,这篇文章就用大白话给各位阐述一下。
Just One Pure ITer
Hadoop 是目前大数据领域最主流的一套技术体系,包含了多种技术,例如 HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统)等等。 有些朋友可能听说过 Hadoop,但是却不太清楚它到底是个什么东西,这篇文章就用大白话给各位阐述一下。
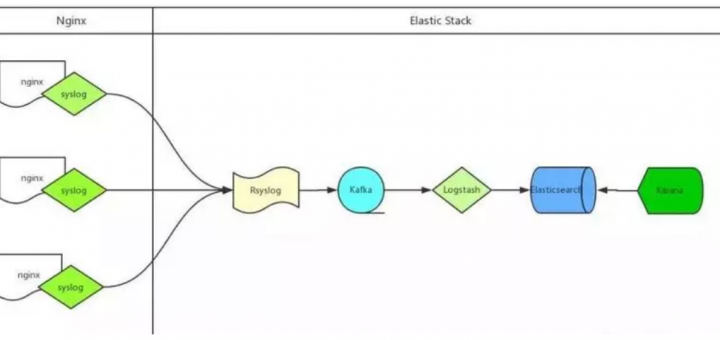
1. 日志系统的必要性? 最早定位生产问题,就是连上一台机器,然后用使用 grep / sed / awk 等 Linux 脚本工具去日志里查找故障原因。如果发现不在这台机器上,就去另一台机器上查日志。有经历过上述步骤的童鞋们,请握个抓! 然而,当你的生产上是一个有几千台机器的集群呢?你要如何定位生产问题呢?又或者,你哪天有这么一个需求,你需要收集某个时间段内的应用日志,你应该如何做? 为了解决上述问题,我们就需要将日志集中化管理。这样做,可以提高我们的诊断效率。同时也有利于我们全面理解系统。
本文重点讨论了大数据系统发展的历史轨迹,行文轻松活泼,内容通俗易懂,是一篇茶余饭后用来作为大数据谈资的不严肃说明文。本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。
ClickHouse 是俄罗斯最大的搜索公司 Yandex 推出的大数据存储和开源组件,在 2017 年易观 OLAP 大赛获得黑马冠军之后,得到了大量的媒体曝光和开发者的认同,大家戏称这是俄罗斯送来的“喀秋莎数据库”。本文将深入浅出的讲解 ClickHouse 数据引擎的基本原理和使用场景,是一篇非常好的 ClickHouse 入门之作。
数据分布的问题在大数据处理领域由来已久。很不幸,如今流行的大数据处理系统仍然没有很好地解决这个问题。在MaxCompute 2.0全新的优化器中,我们引入了复杂数据分布,添加了分区剪枝、分布上拉、下推以及分布对齐等优化措施。 本文将从数据分布的历史和原理开始,介绍我们的思路和解决办法。
Uber facilitates seamless and more enjoyable user experiences by channeling data from a variety of real-time sources. These insights range from in-the-moment traffic conditions that provide guidance on trip routes to the Estimated Time of...
Uber公司通过传播各类实时来源数据以实现更加无缝化且令人愉悦的用户体验。具体而言,Uber需要交付 UberEATS 订单的预估交付时间(简称 ETD)、结合即时交通条件得出的指导配送路线以及其间各项重要影响指标。来自Uber的几位优秀的工程师为我们带来这项技术的详细解析。
现在大数据已经成为企业信息化热点方向之一,很多企业都已经开始或者准备利用大数据大干一场,降低成本、提升数据价值,从而实现智能决策,但是从以 Hadoop 为代表的大数据技术面世以来,将近 10 年的时间,除了几家大型互联网公司以外,企业能够用好大数据的案例远远没有期望的那么多。据国外一家咨询公司 2015 年统计,只有 27% 的公司认为他们的大数据计划是成功的,而只有 8% 的认为是非常成功的。即便是在 POC 阶段,很多企业的平均成功率才只有 38%。
常规的日志收集方案中 Client 端都需要额外安装一个 Agent 来收集日志,例如 logstash、filebeat 等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实现日志收集呢?Rsyslog 就是你要找的答案! 关于 Rsyslog Rsyslog 是高速的日志收集处理服务,它具有高性能、安全可靠和模块化设计的特点,能够接收来自各种来源的日志输入(例如:file,tcp,udp,uxsock 等),并通过处理后将结果输出的不同的目的地(例如:mysql,mongodb,elasticsearch,kafka 等),每秒处理日志量能够超过百万条。 Rsyslog 作为 syslog 的增强升级版本已经在各 linux 发行版默认安装了,无需额外安装。
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |