Category: Distributed Architecture
![[汇总]分布式构架经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[总结]Postgre经验
程序员硬核“年终大扫除”,清理了数据库 70GB 空间 在没有删除单个索引或删除任何数据下,最终释放了超过 70GB 的未优化和未利用的空间,还意外释放 20GB 未使用索引空间。
[转]日订单量达到100万单后,我们做了订单中心重构
1. 背景 几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。当时用的Mysql数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS已经上万了。秒杀我们有一套专门的解决方案,详见《秒杀系统设计~亿级用户》)。不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。 业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。 重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
[总结]MySQL经验
SQL连接图解演示-共七页 数据库底层数据结构与数据库索引类型 跳表,哈希索引,SSTable,LSM树,B树,倒排索引,R树,后缀树。 如果MySQL磁盘满了,会发生什么?还真被我遇到了! 要进行磁盘碎片化整理。原因是datafree占据的空间太多,看看自己的系统的datafree大不大 show table status from 表名; 100G内存下,MySQL查询200G大表会OOM么? MySQL中ORDER BY与LIMIT 不要一起用,有大坑 如果order by的列有相同的值时,mysql会随机选取这些行,为了保证每次都返回的顺序一致可以额外增加一个排序字段(比如:id),用两个字段来尽可能减少重复的概率。
[总结]MySQL主从读写分离经验
数据库读写分离的这些坑,让我一脸懵逼! 「由于数据库同步存在延时,这就导致数据同步的这段时间,主从数据将会不一致,从库无法查询到最新的数据。」 最优解:缓存路由大法
[汇总]分布式ID经验
美团(Leaf)分布式ID生成器 ULID – 一种比UUID更好的方案 为什么MySQL不推荐使用uuid或者雪花id作为主键? 时间占用量总体可以打出的效率排名为:auto_key>random_key>uuid 那么使用自增的id就完全没有坏处了吗?并不是,自增id也会存在以下几点问题: ①别人一旦爬取你的数据库,就可以根据数据库的自增id获取到你的业务增长信息,很容易分析出你的经营情况 ②对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争 ③Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失 我在项目里用雪花算法搞了唯一ID生成,结果上线就引发了故障 我们猜测是不是服务器上的时钟不同步后,又自动进行同步了,前后时间不一致。
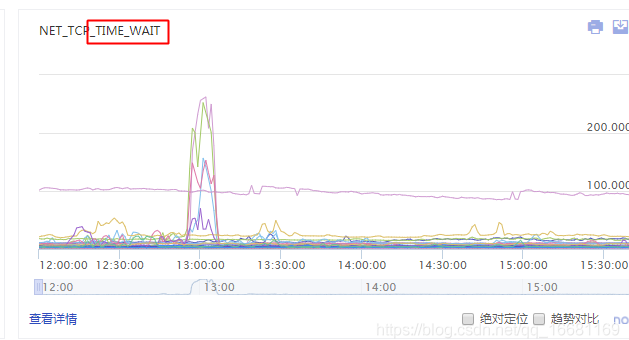
[转]HttpClient 连接池设置引发的一次雪崩
1. 一. 事件背景 我最近运维了一个网上的实时接口服务,最近经常出现Address already in use (Bind failed)的问题。很明显是一个端口绑定冲突的问题,于是大概排查了一下当前系统的网络连接情况和端口使用情况,发现是有大量time_wait的连接一直占用着端口没释放,导致端口被占满(最高的时候6w+个),因此HttpClient建立连接的时候会出现申请端口冲突的情况。
[汇总]关于JWT扩展思考
如果accessToken放Client端,refreshToken存储在服务器,那么会违背微服务的无状态构架初衷。 accessToken和refreshToken统一放在Client端,可以遵循微服务无状态构架。 两种情况都可以通过accessToken来延长refreshToken,做到长时间保持登录状态的需求。
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






