Category: Database Theory & Solution
![[转]弥补MySQL和Redis短板:HBase怎么确保高可用](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]腾讯云如何应对日益膨胀的数据流量?
任何看到显著增长的应用程序或网站,最终都需要进行扩展。以适应流量的增加和确保数据安全性和完整性的方式进行扩展,对于数据驱动的应用程序和网站来说十分重要。人们可能很难预测某个网站或应用程序的流行程度,也很难预测这种流行程度会持续多久——这就是为什么有些机构选择“可动态扩展的”数据库架构的原因。 本文将讨论一种“可动态扩展的”数据库架构:分片数据库。
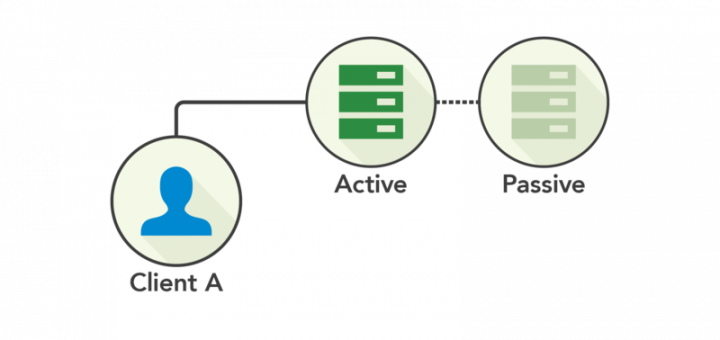
[转]db如何快速回滚+恢复,DBA的神技能
技术人如果经常线上操作DB,河边走久了,难免出现纰漏: update错数据了 delete错数据了 drop错数据了 咋办?找DBA恢复数据呗,即使恢复不了,锅总得有人背呀。 画外音:把数据全删了,怎么办,怎么办?

[总结]分表分库时机选择及策略
1. 一. 分表 1-1. 应用场景: 对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级甚至是亿级,并且数据库面临着极高的并发访问。采用Master-Slave复制模式的MySQL架构,只能够对数据库的读进行扩展,而对数据库的写入操作还是集中在Master上,并且单个Master挂载的Slave也不可能无限制多,Slave的数量受到Master能力和负载的限制。 因此,需要对数据库的吞吐能力进行进一步的扩展,以满足高并发访问与海量数据存储的需要!
[转]冗余数据一致性,到底如何保证?
1. 一,为什么要冗余数据 互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。 水平切分会有一个patition key,通过patition key的查询能够直接定位到库,但是非patition key上的查询可能就需要扫描多个库了。 此时常见的架构设计方案,是使用数据冗余这种反范式设计来满足分库后不同维度的查询需求。
[转]跨库分页的四种方案
一、需求缘起 分页需求 互联网很多业务都有分页拉取数据的需求,例如: (1)微信消息过多时,拉取第N页消息 (2)京东下单过多时,拉取第N页订单 (3)浏览58同城,查看第N页帖子 这些业务场景对应的消息表,订单表,帖子表分页拉取需求有这样一些特点: (1)有一个业务主键id, 例如msg_id, order_id, tiezi_id (2)分页排序是按照非业务主键id来排序的,业务中经常按照时间time来排序order by
[转]单KEY业务,数据库水平切分架构实践
本文将以“用户中心”为例,介绍“单KEY”类业务,随着数据量的逐步增大,数据库性能显著降低,数据库水平切分相关的架构实践: 如何来实施水平切分 水平切分后常见的问题 典型问题的优化思路及实践
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






