![[转]腾讯内部全链路追踪系统“天机阁“的设计与实现](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]腾讯内部全链路追踪系统“天机阁“的设计与实现
传说中天机阁里有一台掌控世间一切的机器,万物运行由此产生。本文的“天机阁”是一个基于链路跟踪的监控系统,后台开发人员能够通过“天机阁”洞察“天机”,快速解决问题。
Just One Pure ITer
传说中天机阁里有一台掌控世间一切的机器,万物运行由此产生。本文的“天机阁”是一个基于链路跟踪的监控系统,后台开发人员能够通过“天机阁”洞察“天机”,快速解决问题。
1. 一、业务背景 运满满创立于 2013 年,致力于为公路运输行业提供高效管理配货的 app。在 5 年时间内从初创型公司发展到独角兽企业,我们经历了很多次的技术架构调整。 今天给大家分享下不同时期,在运维监控方面做的多次架构升级。希望给大家在技术选型阶段,提供一些参考和借鉴。
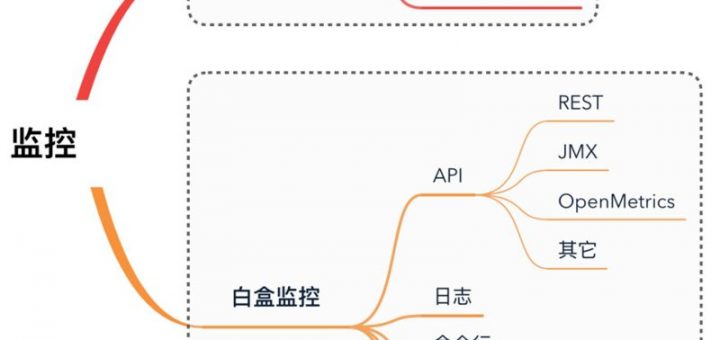
本文从饱和监控的采集和监控的四个黄金指标入手,解答关于新系统如何添加监控的问题。 有很多文章都提到过白盒监控和黑盒监控,以及监控的四个黄金指标。关于白盒与黑盒监控的定义,这里不再赘述。一般来说,白盒与黑盒分别从内部和外部来监控系统的运行状况,例如机器存活、CPU 内存使用率、业务日志、JMX 等监控都属于白盒监控,而外部端口探活、HTTP 探测以及端到端功能监控等则属于黑盒监控的范畴。
1. 导读 相比于数据分片方案的逐渐成熟,集性能、透明化、自动化、强一致、并能适用于各种应用场景于一体的分布式事务解决方案则显得凤毛麟角。基于两(三)阶段提交的分布式事务的性能瓶颈以及柔性事务的业务改造问题,使得分布式事务至今依然是令架构师们头疼的问题。 Apache ShardingSphere(Incubating)不失时机的在2019年初,提供了一个刚柔并济的一体化分布式事务解决方案。如果您的应用系统正在受到这方面的困扰,不妨倒上一杯咖啡,花十分钟阅读此文,说不定会有些收获呢?
(1)大部分人对Java并发仍停留在理论阶段 (2)中间件系统的内核机制:双缓冲机制 (3)百万并发的技术挑战 (4)内存数据写入的锁机制以及串行化问题 (5)内存缓冲分片机制 + 分段加锁机制 (6)缓冲区写满时的双缓冲交换 (7)且慢!刷写磁盘不是会导致锁持有时间过长吗? (8)内存 + 磁盘并行写机制 (9)为什么必须要用双缓冲机制? (10)总结 “ 这篇文章,给大家聊聊一个百万级并发的中间件系统的内核代码里的锁性能优化。很多同学都对Java并发编程很感兴趣,学习了很多相关的技术和知识。比如volatile、Atomic、synchronized底层、读写锁、AQS、并发包下的集合类、线程池,等等。
监控告警是网站可用性的第一道防线,为网站提供更加实时可靠高效的监控告警,对互联网企业具有非凡的意义。致力于这个目标,经过不断地改进,携程新一代监控告警平台 Hickwall 在存储效率、查询速度和告警可靠性方面都有了极大的改善。 本文将从存储、聚合、告警三个方面介绍 Hickwall 在核心架构方面的演进。
Distributed Transaction Solution
by leelight · Published February 5, 2019 · Last modified January 14, 2023
阿里分布式事务框架GTS开源 为什么阿里规定需要在事务注解@Transactional中指定rollbackFor? 1.4 w字,25 张图让你彻底掌握分布式事务原理 别以为面试老问分布式事务,项目里就一定要用,坑贼多! 《我想进大厂》之分布式事务篇 从事务的ACID开始,向大家先说了XA是分布式事务处理的规范,之后谈到2PC和3PC,2PC有同步阻塞、单点故障和数据不一致的问题,3PC在一定程度上解决了同步阻塞和单点故障的问题,但是还是没有完全解决数据不一致的问题。 之后说到TCC、SAGA、消息队列的最终一致性的方案,TCC由于实现过于麻烦和复杂,业务很少应用,SAGA了解即可,国内也很少有应用到的,消息队列提供了解耦的实现方式,对于中小公司来说可能是较为低成本的实现方式。 最后再说目前国内的实现框架,云端阿里云的GTS兼容Seata,非云端使用Seata,它提供了XA、TCC、AT、SAGA的解决方案,可以说是目前的主流选择。 基于MySQL和DynamoDB的强一致性分布式事务实践
by leelight · Published January 25, 2019 · Last modified February 3, 2019
亿级流量系统架构之如何保证百亿流量下的数据一致性(上) 亿级流量系统架构之如何保证百亿流量下的数据一致性(中) 亿级流量系统架构之如何保证百亿流量下的数据一致性(下) 如何保证消息中间件全链路数据100%不丢失(1) 如何保证消息中间件全链路数据100%不丢失(2) 消息中间件如何实现消费吞吐量的百倍优化 如何保证生产者投递到消息中间件的消息不丢失
by leelight · Published January 23, 2019 · Last modified February 3, 2019
在《亿级流量系统架构》系列第一阶段中,我们从零开始,讲述了一个大型数据平台的几个方面的构建,包括: 如何承载百亿级数据的存储挑战 如何承载设计高容错的分布式架构 如何设计高性能架构,使之能承载百亿级流量 如何设计高并发架构,能够支撑住每秒数十万的并发查询 如何设计全链路99.99%的高可用架构 好!架构演进到这个时候,系统是否无懈可击了呢?
很多业务都需要考虑消息投递的顺序性: 单聊消息投递,保证发送方发送顺序与接收方展现顺序一致 群聊消息投递,保证所有接收方展现顺序一致 充值支付消息,保证同一个用户发起的请求在服务端执行序列一致 消息顺序性是分布式系统架构设计中非常难的问题,有什么常见优化实践呢?
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |