Category: Zookeeper
![[转]阿里巴巴为什么不用 ZooKeeper 做服务发现?](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

[转]ZooKeeper搞定服务注册与发现
1. 背景 最近在做分布式相关的工作,由于人手不够只能我一个人来怼;看着这段时间的加班表想想就是够惨的。 不过其中也有遇到的不少有意思的事情今后再拿来分享,今天重点来讨论服务的注册与发现。 2. 分布式带来的问题 我的业务比较简单,只是需要知道现在有哪些服务实例可供使用就可以了(并不是做远程调用,只需要拿到信息即可)。 要实现这一功能最简单的方式可以在应用中配置所有的服务节点,这样每次在使用时只需要通过某种算法从配置列表中选择一个就可以了。 但这样会有一个非常严重的问题: 由于应用需要根据应用负载情况来灵活的调整服务节点的数量,这样我的配置就不能写死。 不然就会出现要么新增的节点没有访问或者是已经 down 掉的节点却有请求,这样肯定是不行的。 往往要解决这类分布式问题都需要一个公共的区域来保存这些信息,比如是否可以利用 Redis? 每个节点启动之后都向 Redis 注册信息,关闭时也删除数据。 其实就是存放节点的 ip + port,然后在需要知道服务节点信息时候只需要去 Redis 中获取即可。 如下图所示: 但这样会导致每次使用时都需要频繁的去查询 Redis,为了避免这个问题我们可以在每次查询之后在本地缓存一份最新的数据。这样优先从本地获取确实可以提高效率。 但同样又会出现新的问题,如果服务提供者的节点新增或者删除消费者这边根本就不知道情况。 要解决这个问题最先想到的应该就是利用定时任务定期去更新服务列表。 以上的方案肯定不完美,并且不优雅。主要有以下几点: 基于定时任务会导致很多无效的更新。 定时任务存在周期性,没法做到实时,这样就可能存在请求异常。 如果服务被强行 kill,没法及时清除 Redis,这样这个看似可用的服务将永远不可用!...

[转]详解分布式协调服务 ZooKeeper
在 2006 年,Google 发表了一篇名为 The Chubby lock service for loosely-coupled distributed systems 的论文,其中描述了一个分布式锁服务 Chubby 的设计理念和实现原理;作为 Google 内部的一个基础服务,虽然 Chubby 与 GFS、Bigtable 和 MapReduce 相比并没有那么大的名气,不过它在 Google 内部也是非常重要的基础设施。 相比于名不见经传的 Chubby,作者相信 Zookeeper 更被广大开发者所熟知,作为非常出名的分布式协调服务,Zookeeper 有非常多的应用,包括发布订阅、命名服务、分数是协调和分布式锁,这篇文章主要会介绍 Zookeeper 的实现原理以及常见的应用,但是在具体介绍 Zookeeper 的功能和原理之前,我们会简单介绍一下分布式锁服务...
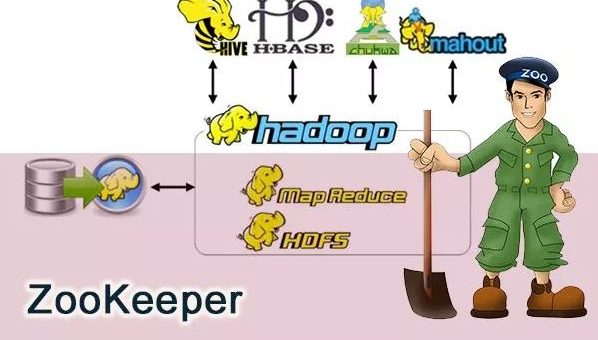
[转]ZooKeeper概念
前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西? 想了半天,脑海中只是简单的能浮现出几句话: Zookeeper 可以被用作注册中心。 Zookeeper 是 Hadoop 生态系统的一员。 构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。 可见,我对于 Zookeeper 的理解仅仅是停留在了表面。所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。 如果没有学过 ZooKeeper,那么本文将会是你进入 ZooKeeper 大门的垫脚砖;如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。 最后,本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。 网上有介绍...
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
