![[转]“反向代理层”绝不能替代“DNS轮询”!](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]“反向代理层”绝不能替代“DNS轮询”!
有朋友问我,DNS轮询是不是过时的技术了?有了反向代理层(Nginx、LVS、F5等),是不是就不需要DNS轮询了? 然而,反向代理层绝不能替代DNS轮询!
Just One Pure ITer
High Concurrency, Circuit Breaker, Rate Limit, Load Balance,etc...
by leelight · Published December 15, 2018
有朋友问我,DNS轮询是不是过时的技术了?有了反向代理层(Nginx、LVS、F5等),是不是就不需要DNS轮询了? 然而,反向代理层绝不能替代DNS轮询!
分布式系统已经诞生了很长时间,随着计算能力和存储价格的降低,我们见证了分布式系统大爆炸的时代,现代互联网公司规模都变得异常庞大,系统也变得越来越复杂,给监控工作带来了极大的难度:海量日志数据如何处理,服务如何追踪,如何高效定位故障缩短故障时长……
High Concurrency, Circuit Breaker, Rate Limit, Load Balance,etc...
by leelight · Published December 9, 2018 · Last modified December 16, 2018
1. 前言 俗话说的好,冰冻三尺非一日之寒,滴水穿石非一日之功,罗马也不是一天就建成的。两周前秒杀案例初步成型,分享到了中国最大的同性交友网站-码云。同时也收到了不少小伙伴的建议和投诉。我从不认为分布式、集群、秒杀这些就应该是大厂的专利,在互联网的今天无论什么时候都要时刻武装自己,只有这样,也许你的春天就在明天。
GitHub 开源项目地址传送门: https://github.com/qunarcorp/qmq 1. 背 景 2012 年,随着公司业务的快速增长,公司当时的单体应用架构很难满足业务快速增长的要求,和其他很多公司一样,去哪儿网也开始了服务化改造,按照业务等要素将原来庞大的单体应用拆分成不同的服务。那么在进行服务化改造之前首先就是面临是服务化基础设施的技术选型,其中最重要的就是服务之间的通信中间件。一般来讲服务之间的通信可以分为同步方式和异步方式。同步的方式的代表就是 RPC,我们选择了当时还在活跃开发的 Alibaba Dubbo(在之后 Dubbo 官方停止了开发,但是最近 Dubbo 项目又重新启动了)。 异步方式的代表就是消息队列 (Message Queue),MQ 在当时也有很多开源的选择:RabbitMQ, ActiveMQ, Kafka, MetaQ(RocketMQ 的前身)。首先因为技术栈我们排除了 erlang 开发的 RabbitMQ,而 Kafka 以及 Java 版 Kafka 的 MetaQ 在当时还并不成熟和稳定。而...
High Concurrency, Circuit Breaker, Rate Limit, Load Balance,etc...
by leelight · Published December 8, 2018
我们都对高可用有一个基本的认识,其中负载均衡是高可用的核心工作。本文将通过如下几个方面,让你妥妥的吃透“”负载均衡”。 负载均衡是什么 常用负载均衡策略图解 常用负载均衡策略优缺点和适用场景 用健康探测来保障高可用 结语
多个数据要同时操作,如何保证数据的完整性,以及一致性? 答:事务,是常见的做法。
AI 前线导读: 一年一度由世界知名科技媒体 InfoWorld 评选的 Bossie Awards 于 9 月 26 日公布,本次 Bossie Awards 评选出了最佳数据库与数据分析平台奖、最佳软件开发工具奖、最佳机器学习项目奖等多个奖项。在 最佳开源数据库与数据分析平台奖 中,之前曾连续两年入选的 Kafka 意外滑铁卢落选,取而代之的是新兴项目 Pulsar。 Bossie Awards 中对 Pulsar 点评如下:“Pulsar 旨在取代 Apache Kafka 多年的主宰地位。Pulsar 在很多情况下提供了比 Kafka 更快的吞吐量和更低的延迟,并为开发人员提供了一组兼容的 API,让他们可以很轻松地从 Kafka 切换到 Pulsar。Pulsar 的最大优点在于它提供了比 Apache Kafka...
一位软件工程师将通过本文向您呈现 Apache Kafka 在大型应用中的 20 项最佳实践。 Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展的、高吞吐量的、且高可靠的实时数据流系统。 例如,在 New Relic 的生产环境中,Kafka 群集每秒能够处理超过 1500 万条消息,而且其数据聚合率接近 1Tbps。 可见,Kafka 大幅简化了对于数据流的处理,因此它也获得了众多应用开发人员和数据管理专家的青睐。
1、单台服务器最大并发 单台服务器最大并发问题,一般是指一台服务器能够支持多少 TCP 并发连接。 一种理论说法是受到端口号范围限制。操作系统上端口号 1024 以下是系统保留的,从 1024-65535 是用户使用的。由于每个 TCP 连接都要占一个端口号,所以我们最多可以有 60000 多个并发连接。 但实际上单机并发连接数肯定要受硬件资源(内存、网卡)、网络资源(带宽)的限制。特别是网卡处理数据的能力,它是最大并发的瓶颈。
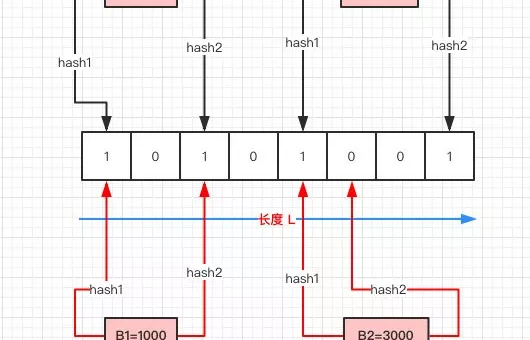
1. 前言 最近有朋友问我这么一个面试题目: 现在有一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要告诉我它是否存在其中(尽量高效)。 需求其实很清晰,只是要判断一个数据是否存在即可。 但这里有一个比较重要的前提:非常庞大的数据。
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |