[转]从单机到2000万QPS:如何搭建高可用Redis平台?
知乎作为知名中文知识内容平台,每日处理的访问量巨大,如何更好的承载这样巨大的访问量,同时提供稳定低时延的服务保证,是知乎技术平台同学需要面对的一大挑战。 知乎存储平台团队基于开源 Redis 组件打造的 Redis 平台管理系统,经过不断的研发迭代,目前已经形成了一整套完整自动化运维服务体系,提供一键部署集群,一键自动扩缩容,Redis 超细粒度监控,旁路流量分析等辅助功能。
Just One Pure ITer
Redis High Avaliable Scale Architect
by leelight · Published September 19, 2018 · Last modified December 16, 2018
知乎作为知名中文知识内容平台,每日处理的访问量巨大,如何更好的承载这样巨大的访问量,同时提供稳定低时延的服务保证,是知乎技术平台同学需要面对的一大挑战。 知乎存储平台团队基于开源 Redis 组件打造的 Redis 平台管理系统,经过不断的研发迭代,目前已经形成了一整套完整自动化运维服务体系,提供一键部署集群,一键自动扩缩容,Redis 超细粒度监控,旁路流量分析等辅助功能。
Cache in distributed Architecture
by leelight · Published September 19, 2018 · Last modified June 6, 2022
1. 0 背景 在之前的文章中缓存进化史介绍了某大型互联网公司的缓存架构和缓存的进化历史。俗话说得好,工欲善其事,必先利其器,有了好的工具肯定得知道如何用好这些工具,本篇将介绍如何利用好缓存。
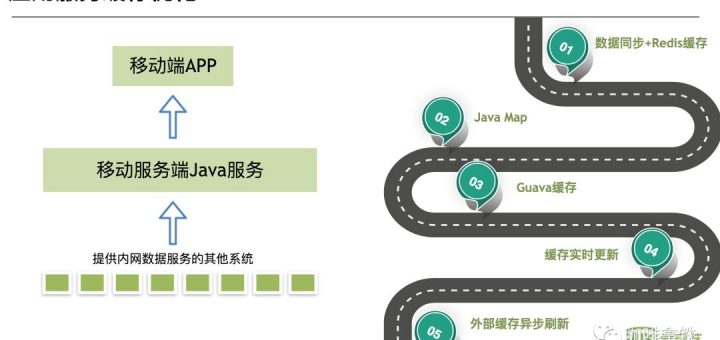
1. 1 背景 本文是上周去技术沙龙听了一下爱奇艺的Java缓存之路有感写出来的。先简单介绍一下爱奇艺的java缓存道路的发展吧。 可以看见图中分为几个阶段:
前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西? 想了半天,脑海中只是简单的能浮现出几句话: Zookeeper 可以被用作注册中心。 Zookeeper 是 Hadoop 生态系统的一员。 构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。 可见,我对于 Zookeeper 的理解仅仅是停留在了表面。所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。 如果没有学过 ZooKeeper,那么本文将会是你进入 ZooKeeper 大门的垫脚砖;如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。 最后,本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。 网上有介绍...
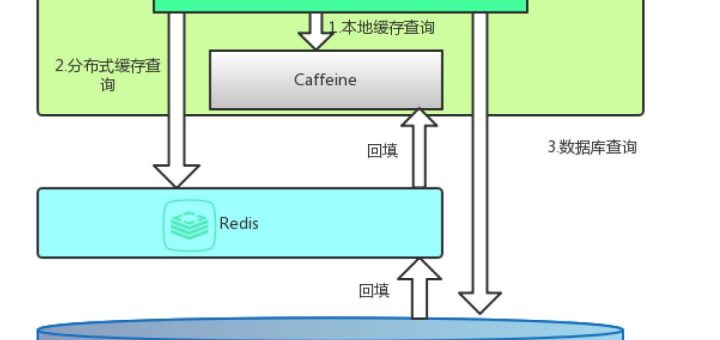
互联网软件神速发展,用户的体验度是判断一个软件好坏的重要原因,所以缓存就是必不可少的一个神器。在多线程高并发场景中往往是离不开cache的,需要根据不同的应用场景来需要选择不同的cache,比如分布式缓存如redis、memcached,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine。 说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。由于Guava的大量使用,Guava Cache也得到了大量的应用。但是,Guava Cache的性能一定是最好的吗?也许,曾经,它的性能是非常不错的。但所谓长江后浪推前浪,总会有更加优秀的技术出现。今天,我就来介绍一个比Guava Cache性能更高的缓存框架:Caffeine。 官方性能比较 Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。 EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 Caffeine是使用Java8对Guava缓存的重写版本,在Spring Boot 2.0中将取代,基于LRU算法实现,支持多种缓存过期策略。 场景1:8个线程读,100%的读操作。 场景二:6个线程读,2个线程写,也就是75%的读操作,25%的写操作。 场景三:8个线程写,100%的写操作。 可以清楚地看到Caffeine效率明显高于其他缓存。 如何使用?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class=""> 1</span> public <span class="">static</span> <span class="">void</span> main(<span class="">String</span>[] args) { <span class=""> 2</span> LoadingCache<<span class="">String</span>, <span class="">String</span>> build = CacheBuilder.newBuilder().initialCapacity(<span class="">1</span>).maximumSize(<span class="">100</span>).expireAfterWrite(<span class="">1</span>, TimeUnit.DAYS) <span class=""> 3</span> .build(<span class="">new</span> CacheLoader<<span class="">String</span>, <span class="">String</span>>() { <span class=""> 4</span> <span class="">//默认的数据加载实现,当调用get取值的时候,如果key没有对应的值,就调用这个方法进行加载</span> <span class=""> 5</span> <span class="">@Override</span> <span class=""> 6</span> public <span class="">String</span> load(<span class="">String</span> key) { <span class=""> 7</span> <span class="">return</span> <span class="">""</span>; <span class=""> 8</span> } <span class=""> 9</span> }); <span class="">10</span> } <span class="">11</span> } |
参数方法: initialCapacity(1) 初始缓存长度为1; maximumSize(100) 最大长度为100; expireAfterWrite(1, TimeUnit.DAYS) 设置缓存策略在1天未写入过期缓存(后面讲缓存策略)。 过期策略 在Caffeine中分为两种缓存,一个是有界缓存,一个是无界缓存,无界缓存不需要过期并且没有界限。 在有界缓存中提供了三个过期API: expireAfterWrite:代表着写了之后多久过期。(上面列子就是这种方式)...
考虑到绝大部分写业务的程序员,在实际开发中使用 Redis 的时候,只会 Set Value 和 Get Value 两个操作,对 Redis 整体缺乏一个认知。 所以我斗胆以 Redis 为题材,对 Redis 常见问题做一个总结,希望能够弥补大家的知识盲点。 本文围绕以下几点进行阐述: 为什么使用 Redis 使用 Redis 有什么缺点 单线程的 Redis 为什么这么快 Redis 的数据类型,以及每种数据类型的使用场景 Redis 的过期策略以及内存淘汰机制 Redis 持久化机制 Redis 事务 Redis 和数据库双写一致性问题 如何应对缓存穿透和缓存雪崩问题 如何解决 Redis 的并发竞争 Key 问题 1. 为什么使用 Redis 我觉得在项目中使用 Redis,主要是从两个角度去考虑:性能和并发。 当然,Redis 还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件,如...
Redis High Avaliable Scale Architect
by leelight · Published September 18, 2018 · Last modified June 15, 2019
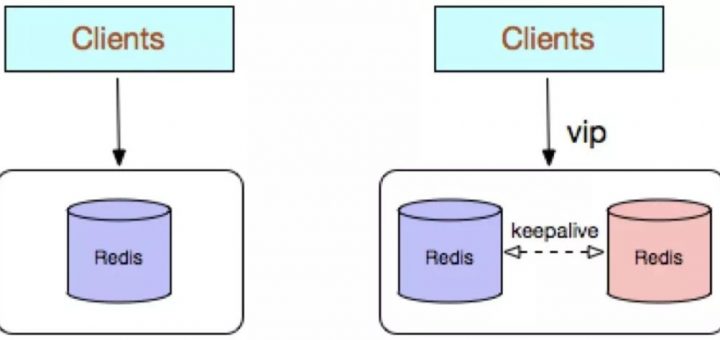
本文主要针对 Redis 常见的几种使用方式及其优缺点展开分析。 1. 一、常见使用方式 Redis 的几种常见使用方式包括: Redis 单副本; Redis 多副本(主从); Redis Sentinel(哨兵); Redis Cluster; Redis 自研。
在微服务架构中,一般都是通过 API 网关统一向外部系统提供 API 服务。熟悉 Spring Cloud 的同学知道,Zuul 在 Spring Cloud 中就起到了 API 网关的作用。同理,在菜鸟微服务架构中,菜鸟 API 网关作为对外暴露服务的网关。 菜鸟在面向全球 CP(Cainiao Partner)提供服务的时候,遇到了传统 API 网关在跨国网络上传输数据的瓶颈,如下图,Partner C(国外的 CP)调用 API Gateway 走了跨国的公网,该段网络的质量非常不稳定,严重影响了 Partner C 的服务体验。我们把这种由于网络延迟高、抖动严重而引起的网络质量问题称为 网络桎梏。
在 QCon 旧金山 2016 会议上,Neha Narkhede 做了“ETL 已死,而实时流长存”的演讲,并讨论了企业级数据处理领域所面临的挑战。该演讲的核心前提是开源的 Apache Kafka 流处理平台能够提供灵活且统一的框架,支持数据转换和处理的现代需求。 Narkhede 是 Confluent 的联合创始人和 CTO,在演讲中,他首先阐述了在过去的十年间,数据和数据系统的重要变化。该领域的传统功能包括提供联机事务处理(online transaction processing,OLTP)的操作性数据库以及提供在线分析处理(online analytical processing,OLAP)的关系型数据仓库。来自各种操作性数据库的数据会以批处理的方式加载到数据仓库的主模式中,批处理运行的周期可能是每天一次或两次。这种数据集成过程通常称为抽取 – 转换 – 加载(extract-transform-load,ETL)。
前段时间,我写了一系列分布式系统架构方面的文章(拉到文末看目录),有很多读者纷纷留言讨论相关的话题,还有读者留言表示对分布式系统架构这个主题感兴趣,希望我能推荐一些学习资料。 就像我在前面的文章中多次提到的,分布式系统的技术栈巨大无比,所以我要推荐的学习资料也比较多,会在后面的文章中陆续发出。在今天这篇文章中,我将推荐一些分布式系统的基础理论和一些不错的图书和资料。
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |