![[总结]全链路分布式追踪系统经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[总结]全链路分布式追踪系统经验
微服务中台技术解析之全链路分布式追踪系统实践 用了3年CAT,这次我想选择SkyWalking,老板反手就是一个赞! 全链路监控神器Skywalking,就是这么秀!
Just One Pure ITer
微服务中台技术解析之全链路分布式追踪系统实践 用了3年CAT,这次我想选择SkyWalking,老板反手就是一个赞! 全链路监控神器Skywalking,就是这么秀!
40张图看懂SkyWalking分布式追踪系统原理及实践 不论是 CPU,内存,还是响应时间,使用 SkyWalking 带来的性能损耗几乎可以忽略不计。 接下来我们再来看 SkyWalking 与另一款业界比较知名的分布式追踪工具 Zipkin, Pinpoint 的对比(在采样率为 1 秒 1 个,线程数 500,请求总数为 5000 的情况下做的对比),可以看到在关键的响应时间上, Zipkin(117ms),PinPoint(201ms)远逊色于 SkyWalking(22ms)
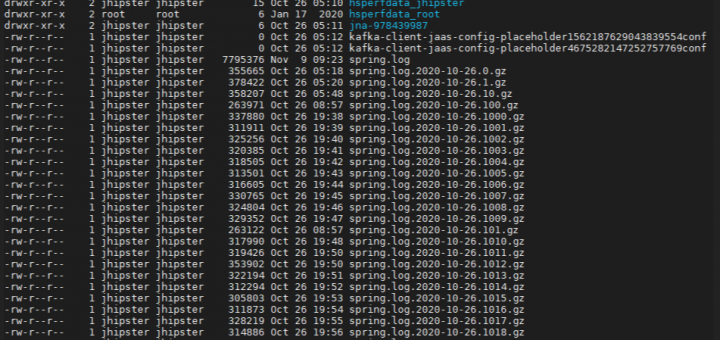
We found the spring boot project running containers will keep restarting after some time, maybe 10 days, maybe 5 days. The root cause is spring logback is writing log files into /tmp/ directory as...
日志平台为集团所有业务系统提供日志采集、消费、分析、存储、索引和查询的一站式日志服务。 主要为了解决日志分散不方便查看、日志搜索操作复杂且效率低、业务异常无法及时发现等等问题。 随着有赞业务的发展与增长,每天都会产生百亿级别的日志量(据统计,平均每秒产生 50 万条日志,峰值每秒可达 80 万条)。日志平台也随着业务的不断发展经历了多次改变和升级。 本文跟大家分享有赞在当前日志系统的建设、演进以及优化的经历,这里先抛砖引玉,欢迎大家一起交流讨论。
Spring Boot 服务监控,健康检查,线程信息,JVM堆信息,指标收集,运行情况监控等! Spring Boot是如何实现日志的? 阿里巴巴不允许工程师直接使用Log4j和Logback的API! 3种常见的数据脱敏方案 一个注解搞定接口返回数据脱敏
现代微服务架构由于业务系统模型日趋复杂,分布式系统中需要一套链路追踪系统来帮助我们理解系统行为,明确服务间调用。最近作者请到了 Zipkin 项目的主要开发维护人员 Adrian Cole 来介绍有关 Zipkin 项目的细节内容,可以让大家了解到如何在分布式追踪系统中用好 Zipkin。Adrian 一直在从事云计算相关开源项目的开发,是开源项目 Apache jclouds 和 OpenFeign 的创始人。最近几年,他专注于分布式跟踪领域,是 OpenZipkin 项目的主要开发维护人员。Adrian 目前在 Pivotal Spring Cloud OSS 团队工作。在加入 Pivotal 之前,他还在 Twitter,Square,Netflix 工作过。
Continue with Design Log Monitor System Prototype For Spring MVC 1. Practice 1-1. 1. Log format You can define yours own team log format. Name Remark requestID uuid timestamp log record time level log level...
1. Background In this article, a log monitor system is designed for one classic monolithic Spring MVC project, which contains three module layers: Controller, Service, and Repository. 2. Requirement All system exceptions should be...
1. 概述 统一日志服务使用了分布式跟踪技术来收集和存储分散在各个应用或接口服务的日志,这些日志可用于后续的运维、监控和统计分析。 分布式跟踪技术把每次请求的整个调用链记录下来,可以方便的查看一次请求从客户端到应用服务器到数据库等每个阶段的执行情况,详细参考OpenTracing。
1. 0. 缘起 大约在三年前,我曾经写过一篇 最佳日志实践,还被码农周刊选为那年的 最受欢迎技术干货 之一。当时我任职于网易杭州研究院的存储平台组,主要做网易对象存储(NOS)的开发和部分运维工作。由于网易云音乐,易信等几个重要产品陆续上线,业务压力剧增,我们的系统在前前后后大约半年的时间里,出现了大大小小各种事故。通过不断总结事故原因、不断地优化代码、进化部署架构,才使整个系统逐渐稳定下来。那个时候组里人常常开玩笑说,我们采用的是TDD的开发模式,只是这个TDD不是测试驱动开发(Test Driven Development),而是悲剧驱动开发(Tragedy Driven Development)。
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |