Category: Performance Optimization
![[转]哪些原因会导致JAVA进程退出](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]哪些原因会导致JAVA进程退出
那我们就开一篇文章说一下这个问题,其实很easy的,无外乎三种情况。 linux的OOM killer杀死 JVM自身故障 jvm的OOM导致进程退出(很罕见,我至今没遇见过)
[汇总]JVM, OOM经验
记一次隐藏很深的 JVM 线上惨案的分析、排查、解决! JVM在反射代码执行的过程导致Full GC ArrayList插入1000w条数据之后,我怀疑了jvm… 加个 -XX:+PrintGCDetails -XX:+PrintGCDateStamps,看下第一次是不是有Full GC 案例实战:每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化? 神奇的 perfma:一站式解决所有 JVM 疑难杂症! JVM参数分析的链接地址:https://opts.console.perfma.com/ 生产实践经验:线上系统的 JVM 内存是越大越好吗? 所以很多人在用Elasticsearch的时候就是这样的一个问题,老是觉得ES读取速度慢,几个亿的数据写入ES,读取的时候要好几秒。那能不花费好几秒吗?你要是ES集群部署的时候,给JVM内存过大,给os cache留了几个GB的内存,导致几亿条数据大部分都在磁盘上,不在os cache里,最后读取的时候大量读磁盘,耗费个几秒钟是很正常的。 所以说,针对类似Kafka、Elasticsearch这种生产系统部署的时候,应该要给JVM比如6GB或者几个GB的内存就可以了。因为他们可能不需要耗费过大的内存空间,不依赖JVM内存管理数据,当然具体是设置多少,需要你精准的压测和优化。 但是对于这类系统,应该给os cache留出来足够的内存空间,比如32GB内存的机器,完全可以给os cache留出来20多G的内存空间,那么此时假设你这台机器总共就写入了20GB的数据,就可以全部驻留在os cache里了。然后后续在查询数据的时候,不就可以全部从os cache里读取数据了,完全依托内存来走,那你的性能必然是毫秒级的,不可能出现几秒钟才完成一个查询的情况。 为什么我们选择Java开发高频交易系统?...
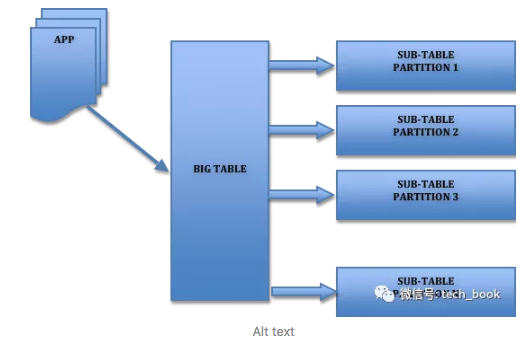
[转]数据量很大,分页查询很慢,别再用offset和limit分页了
当需要从数据库查询的表有上万条记录的时候,一次性查询所有结果会变得很慢,特别是随着数据量的增加特别明显,这时需要使用分页查询。 对于数据库分页查询,也有很多种方法和优化的点。下面简单说一下我知道的一些方法。
[汇总]MySQL优化经验和理论
MySQL每秒50w+的写入,如何实现? innodb,它是我们建表的首选存储引擎 为什么 MySQL 索引要使用 B+树而不是其它树形结构?比如 B 树? 那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170*1170*16=21902400条这样的记录。 一款SQL自动检查神器,再也不用担心SQL出错了!Yearning 两类非常隐蔽的全表扫描,不能命中索引 第一类:“列类型”与“where值类型”不符,不能命中索引,会导致全表扫描(full table scan)。 第二类:相join的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算(nested loop)。
[转]数据库连接池的大小与性能
1. 一、前言 基本上来说,大部分项目都需要跟数据库做交互,那么,数据库连接池的大小设置成多大合适呢? 一些开发老鸟可能还会告诉你:没关系,尽量设置的大些,比如设置成 200,这样数据库性能会高些,吞吐量也会大些! 你也许会点头称是,真的是这样吗?看完这篇文章,也许会颠覆你的认知哦!
[转]JVM最多支持多少个线程?
McGovernTheory在StackOverflow提了这样一个问题: Java虚拟机最多支持多少个线程?跟虚拟机开发商有关么?跟操作系统呢?还有其他的因素吗?
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






