[转]MySQL优化指南
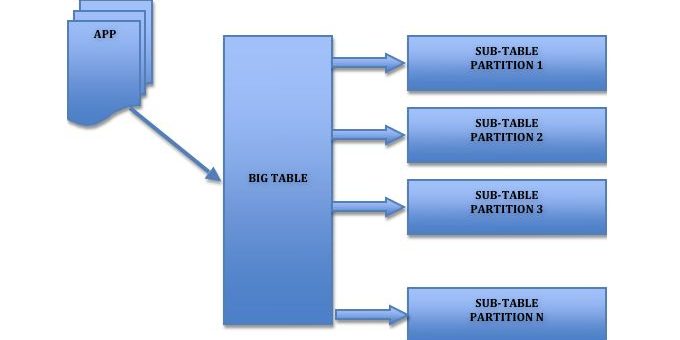
当MySQL单表记录数过大时,增删改查性能都会急剧下降,所以我们本文会提供一些优化参考,大家可以参考以下步骤来优化: 1. 一、单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度。一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的,而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量。
Just One Pure ITer
当MySQL单表记录数过大时,增删改查性能都会急剧下降,所以我们本文会提供一些优化参考,大家可以参考以下步骤来优化: 1. 一、单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度。一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的,而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量。
1. 一、基础规范 表存储引擎必须使用InnoDB 表字符集默认使用utf8,必要时候使用utf8mb4 解读: (1)通用,无乱码风险,汉字3字节,英文1字节 (2)utf8mb4是utf8的超集,有存储4字节例如表情符号时,使用它
我试图在 MariaDB(MySQL)上运行一个简单的连接查询,但性能简直糟糕透了。下面将介绍我是如何通过两个简单的 Unix 命令,将查询时间从 380 小时降到 12 小时以下的。 下面就是这个查询,它是 GHTorrent 分析的一部分,我使用了关系在线分析处理框架 simple-rolap 来实现这个分析。
|
1 2 3 4 5 6 |
select distinct project_commits.project_id, date_format(created_at, '%x%v1') as week_commit from project_commits left join commits on project_commits.commit_id = commits.id; |
两个连接字段都有索引。不过,MariaDB 是通过对 project_commits 进行全表扫描和对 commits 进行索引查找来实现连接的。这可以从 EXPLAIN 的输出看出来。
1. MySQL 慢怎么办 如果遇到 MySQL 慢的话,你的第一印象是什么,MySQL 数据库如果性能不行,你是如何处理的? 我咨询了一些同行, 得到了以下反馈: 第一反应是再试一次 第二个反应是优化一下 SQL 第三个反应是调大 buffer pool,然后开始换硬件了,换一下 SSD 最后实在不行了找个搜索引擎搜索一下“MySQL 慢怎么办”。
1. 写在前面 当我在帮助一些开发者或架构师分析及优化 Java 应用程序的性能时,关键往往不在于对个别方法进行微调,以节省一或两微秒的执行时间。虽然对某些软件来说,微秒级的优化确实非常重要,但我认为这并非着眼点所在。我在 2015 年间对数百个应用进行了分析,发现多数性能与可伸缩性问题都来源于糟糕的架构决策、框架的错误配置、错误的数据库访问模式、过量的日志记录,以及由于内存过度消耗而导致的垃圾回收所带来的影响。
by leelight · Published September 15, 2018 · Last modified September 16, 2018
港真,Null 貌似在哪里都是个头疼的问题,比如 Java 里让人头疼的 NullPointerException,为了避免猝不及防的空指针异常,千百年来程序猿们不得不在代码里小心翼翼的各种 if 判断,麻烦而又臃肿,为此 java8 引入了 Optional 来避免这一问题。 下面咱们要聊的是 MySQL 里的 null,在大量的 MySQL 优化文章和书籍里都提到了字段尽可能用NOT NULL,而不是NULL,除非特殊情况。但却都只给结论不说明原因,犹如鸡汤不给勺子一样,让不少初学者对这个结论半信半疑或者云里雾里。本文今天就详细的剖析下使用 Null 的原因,并给出一些不用 Null 的理由。
by leelight · Published September 15, 2018 · Last modified September 23, 2018
这几天在写索引,想到一些有意思的TIPS,希望大家有收获。 1. 一、一些常见的SQL实践 (1)负向条件查询不能使用索引 select * from order where status!=0 and stauts!=1 not in/not exists都不是好习惯 可以优化为in查询: select * from order where status in(2,3) (2)前导模糊查询不能使用索引 select * from order where desc like ‘%XX’ 而非前导模糊查询则可以: select *...
正文 数据库是所有架构中不可缺少的一环,一旦数据库出现性能问题,那对整个系统都回来带灾难性的后果。并且数据库一旦出现问题,由于数据库天生有状态(分主从)带数据(一般还不小),所以出问题之后的恢复时间一般不太可控,所以,对数据库的优化是需要我们花费很多精力去做的。接下来就给大家介绍一下微博数据库这些年的一点经验,希望可以对大家有帮助。
工作中,曾有同事问我以下sql的效率如何,这里扩展一下这个问题并进行分析,主要说明where子句中的子查询和函数执行次数及索引使用情况。
|
1 2 3 |
select * from trd_fundjour a where oc_date = (select collect_date from hscon.sys_arg); |
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
![[总结]58到家MySQL军规升级版](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)