Mobabel Blog
![[汇总]压力测试](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[总结]从10秒到2秒!ElasticSearch性能调优实践
做过数据收集、数据开发、数据存储的同学相信对这个简称并不陌生,而 ElasticSearch(以下简称 ES)则在 ELK 栈中占着举足轻重的地位。 前一段时间,我亲身参与了一个 ES 集群的调优,今天把我所了解与用到的调优方法与大家分享,如有错误,请大家包涵与指正。
[转]百万并发中间件系统的内核设计看Java并发性能优化
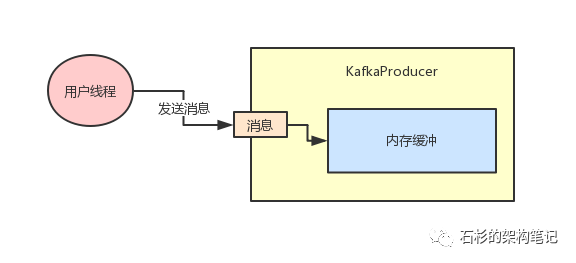
(1)大部分人对Java并发仍停留在理论阶段 (2)中间件系统的内核机制:双缓冲机制 (3)百万并发的技术挑战 (4)内存数据写入的锁机制以及串行化问题 (5)内存缓冲分片机制 + 分段加锁机制 (6)缓冲区写满时的双缓冲交换 (7)且慢!刷写磁盘不是会导致锁持有时间过长吗? (8)内存 + 磁盘并行写机制 (9)为什么必须要用双缓冲机制? (10)总结 “ 这篇文章,给大家聊聊一个百万级并发的中间件系统的内核代码里的锁性能优化。很多同学都对Java并发编程很感兴趣,学习了很多相关的技术和知识。比如volatile、Atomic、synchronized底层、读写锁、AQS、并发包下的集合类、线程池,等等。
[转]基于Elasticsearch分布式搜索引擎的架构原理
1. (1)倒排索引到底是啥? 要了解分布式搜索引擎,先了解一下搜索这个事儿吧,搜索这个技术领域里最入门级别的一个概念就是倒排索引。 我们先简单说一下倒排索引是个什么东西。
[转]新浪日访问量百亿级的应用如何做缓存架构设计
微博日活跃用户1.6亿+,每日访问量达百亿级,面对庞大用户群的海量访问,良好架构且不断改进的缓存体系具有非常重要的支撑作用。刷微博吗?跟我们一起听听那些庞大的数据是如何呈现的吧! 陈波:大家好,今天的分享主要有以下内容,首先是微博在运行过程中的数据挑战,然后是Feed系统架构,接下来会着重分析Cache架构及演进,最后是总结、展望。
[转]同程RocketMQ如何应对每天1500亿条的数据处理?
同程艺龙的机票、火车票、汽车票、酒店相关业务已经接入了 RocketMQ,用于流量高峰时候的削峰,以减少后端的压力。 同时,对常规的系统进行解耦,将一些同步处理改成异步处理,每天处理的数据达 1500 亿条。 在近期的 Apache RocketMQ Meetup 上,同程艺龙机票事业部架构师查江,分享了同程艺龙的消息系统如何应对每天 1500 亿条的数据处理。 通过此文,您将了解到: 同程艺龙消息系统的使用情况 同程艺龙消息系统的应用场景 技术上踩过的坑 基于 RocketMQ 的改进
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
