
[转]一个包含10节点的Redis集群实践案例
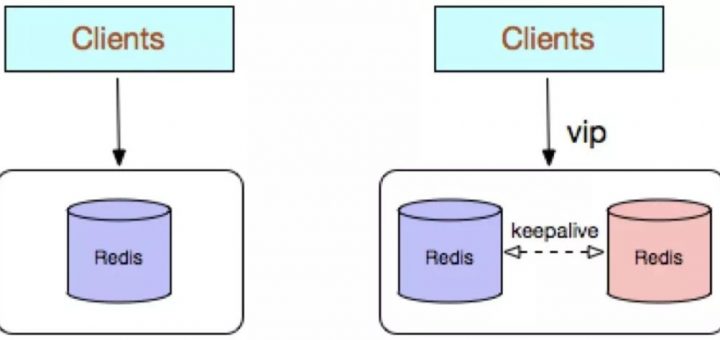
Redis 通常不会被用作主要的数据存储,但它在存储和访问可容忍丢失的临时数据(如度量指标、会话状态、缓存)方面却独有长处,并且速度非常快,不仅提供了最佳性能,还内置了一组非常有用的数据结构。它是现代技术栈中最常见的主要部件之一。 Stripe(一家做支付的硅谷创业公司)的速率限定器就是基于 Redis 构建的,这些限速器运行在一个 Redis 实例上。Redis 主服务器有一些用于失效备援的追随者,不过在任何时候,都只有一个节点在处理读写操作。 各种消息来源声称,一个 Redis 节点每秒可以处理百万次操作。尽管我们的操作没有那么多,但也不会很少。每个速率限定器都需要运行多个 Redis 命令,而每个 API 请求都要通过很多个速率限定器。所以,每个节点每秒钟需要处理数万次到数十万次的操作。 如果节点出现饱和,就会不断出现故障。我们的服务可以容忍 Redis 的不可用,因此大多数情况下是没有问题的,但在某些情况下,问题的严重程度会升级。我们最后通过迁移到包含 10 节点的 Redis 集群来解决这个问题。对性能的影响可以忽略不计,重要的是现在我们可以实现水平可伸缩。
![[转]缓存构架经验总结 – 2. 选redis还是memcache](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)





![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)





