Tagged: Web Crawler
![[汇总]爬虫经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[汇总]微信开发资料
itchath和werobot itchat这是一个操作微信的第三方库。通过这个库几行代码就可以实现直接登录微信、自动添加好友、自定义给微信好友回复内容、给好友发送图片文本视频等聊天内容、参与群聊、采集微信好友的资料等等。 werobot这个库封装了微信公众号的很多接口。通过这个库你可以很容易的给订阅你公众号的粉丝发送消息、推送图文、跟粉丝互动。
[转]从千亿页面上提取数据所总结的五大经验
如今从网上抓取数据看似非常容易。有许多开源库和框架、可视化抓取工具和数据提取工具,可以很容易地从一个网站上抓取数据。但是,当你想大规模地搜索网站时,很快就会感觉到非常棘手。 本文中,我们将与你分享自2010年以来借助Scrapinghub从一千亿个产品页面上抓取数据时所学到的经验教训,让你深入了解从电子商务店铺大规模提取产品数据时面临的挑战,并与你分享一些应对这些挑战的最佳实践经验。 Scrapinghub成立于2010年,是数据提取公司中的佼佼者之一,也是Scrapy的缔造者——Scrapy是当今最强大、最受欢迎的网络抓取框架。目前,Scrapinghub为全球众多的大型电子商务公司每月抓取超过80亿的页面(其中30亿是产品页面)。
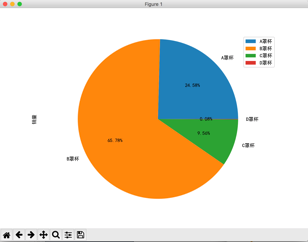
[转]根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的。是网络爬虫和数据分析的综合应用项目。本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过SQL语句、Pandas和Matplotlib对数据进行数据可视化分析。我们从分析结果中可以得出很多有的结果,例如,中国女性胸部标准尺寸是多少;胸罩上胸围的销售比例;哪个颜色的胸罩最受女性欢迎。

[转]谈爬虫反爬虫套路
爬虫与反爬虫,是一个很不阳光的行业。 这里说的不阳光,有两个含义。 第一是,这个行业是隐藏在地下的,一般很少被曝光出来。很多公司对外都不会宣称自己有爬虫团队,甚至隐瞒自己有反爬虫团队的事实。这可能是出于公司战略角度来看的,与技术无关。 第二是,这个行业并不是一个很积极向上的行业。很多人在这个行业摸爬滚打了多年,积攒了大量的经验,但是悲哀的发现,这些经验很难兑换成闪光的简历。面试的时候,因为双方爬虫理念或者反爬虫理念不同,也很可能互不认可,影响自己的求职之路。本来程序员就有“文人相轻”的倾向,何况理念真的大不同。
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)





